ReST-MCTS*: LLM Self-Training via Process Reward Guided Tree Search
2406.03816
0
0
Abstract
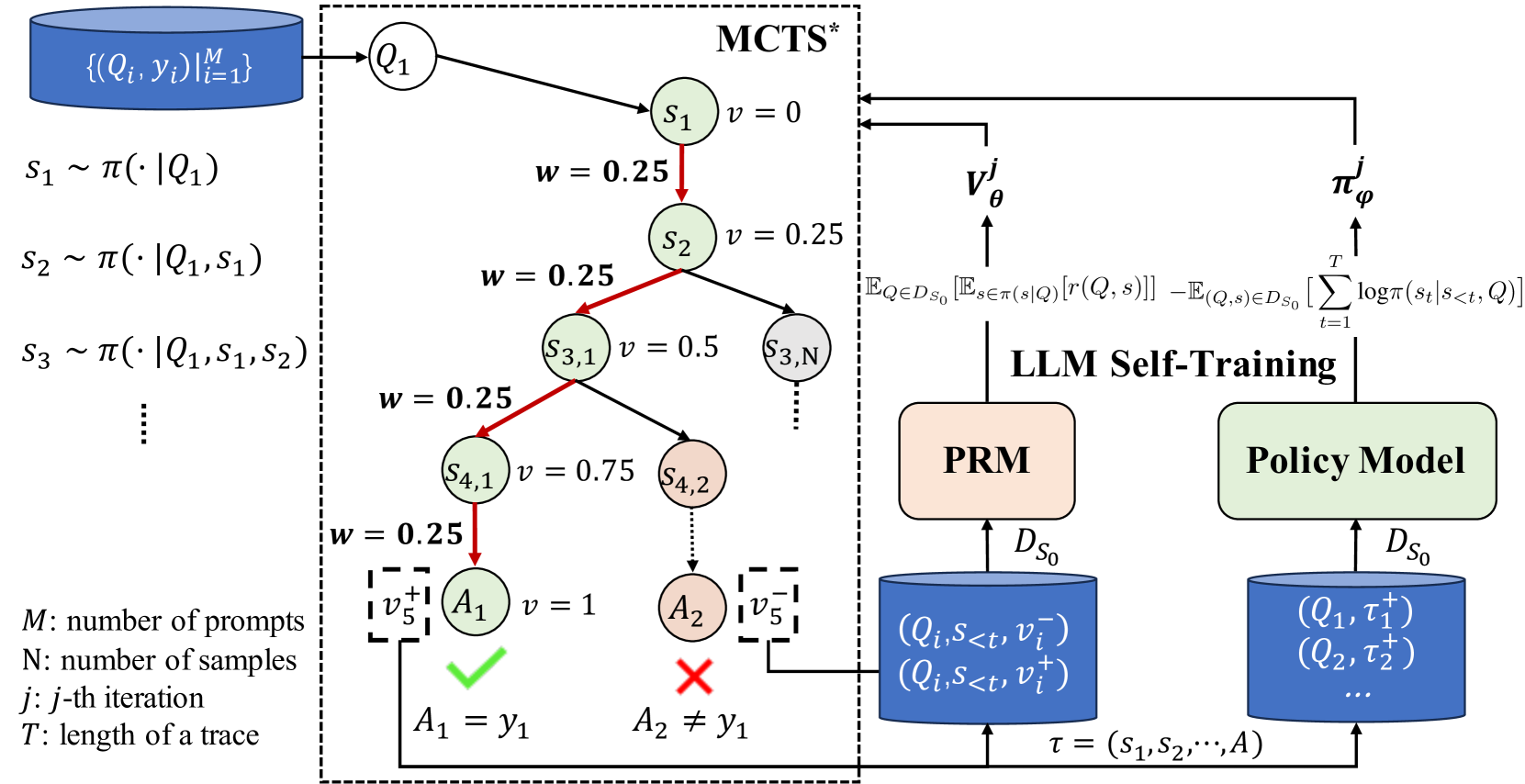
Recent methodologies in LLM self-training mostly rely on LLM generating responses and filtering those with correct output answers as training data. This approach often yields a low-quality fine-tuning training set (e.g., incorrect plans or intermediate reasoning). In this paper, we develop a reinforced self-training approach, called ReST-MCTS*, based on integrating process reward guidance with tree search MCTS* for collecting higher-quality reasoning traces as well as per-step value to train policy and reward models. ReST-MCTS* circumvents the per-step manual annotation typically used to train process rewards by tree-search-based reinforcement learning: Given oracle final correct answers, ReST-MCTS* is able to infer the correct process rewards by estimating the probability this step can help lead to the correct answer. These inferred rewards serve dual purposes: they act as value targets for further refining the process reward model and also facilitate the selection of high-quality traces for policy model self-training. We first show that the tree-search policy in ReST-MCTS* achieves higher accuracy compared with prior LLM reasoning baselines such as Best-of-N and Tree-of-Thought, within the same search budget. We then show that by using traces searched by this tree-search policy as training data, we can continuously enhance the three language models for multiple iterations, and outperform other self-training algorithms such as ReST$^text{EM}$ and Self-Rewarding LM.
Create account to get full access
Overview
- This paper presents ReST-MCTS*, a novel approach that combines Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS) to enable self-training and improve reasoning capabilities.
- The key idea is to use MCTS to explore and evaluate different reasoning paths, guided by a reward function that captures the "process quality" of the reasoning, rather than just the final outcome.
- This process-focused reward allows the LLM to learn and improve its reasoning skills in a self-supervised manner, without the need for extensive labeled data.
Plain English Explanation
The researchers developed a system called ReST-MCTS* that combines the power of large language models (LLMs) with a technique called Monte Carlo Tree Search (MCTS). LLMs are AI systems that can generate human-like text, while MCTS is a way of exploring different options and evaluating them to find the best course of action.
In this case, the researchers used MCTS to explore different reasoning paths that the LLM could take. Instead of just looking at the final result, the system evaluated the "quality" of the reasoning process itself, using a special reward function. This allowed the LLM to learn and improve its reasoning skills on its own, without needing a lot of labeled training data.
The key insight is that by focusing on the reasoning process, rather than just the final answer, the LLM can learn to reason more effectively and solve complex problems better over time. This self-training approach could be a powerful way to help large language models become more capable and reliable, without the need for manual supervision or labeling of every training example.
Technical Explanation
The researchers present ReST-MCTS*, a system that integrates Monte Carlo Tree Search (MCTS) with Large Language Models (LLMs) to enable self-training and improved reasoning capabilities.
The core idea is to use MCTS to explore and evaluate different reasoning paths that the LLM can take, guided by a "process reward" function that captures the quality of the reasoning process, rather than just the final outcome. This process-focused reward allows the LLM to learn and improve its reasoning skills in a self-supervised manner, without the need for extensive labeled data.
The researchers draw inspiration from prior work on learning planning-based reasoning and value model generation to design the ReST-MCTS* system. They demonstrate the effectiveness of their approach on various reasoning tasks, showing that the LLM can progressively improve its reasoning capabilities through this self-training process.
Critical Analysis
The researchers acknowledge several limitations and areas for future research in their paper. For example, the process reward function is a key component, and further work is needed to understand how to design effective reward functions for different types of reasoning tasks.
Additionally, the paper does not extensively explore the potential biases or safety concerns that may arise from this self-training approach. As LLMs become more capable through this process, it will be important to carefully monitor their outputs and behaviors to ensure they are aligned with ethical and societal values.
Another area for further investigation is the scalability of the ReST-MCTS* approach. The researchers demonstrate the method on relatively small-scale tasks, and it remains to be seen how well it would perform on more complex, real-world reasoning problems.
Overall, the ReST-MCTS* system represents an intriguing step towards self-improvement of LLMs via imagination searching, but there are still many open questions and challenges to be addressed in this promising area of research.
Conclusion
The ReST-MCTS* system presented in this paper offers a novel approach to enabling large language models to self-train and improve their reasoning capabilities. By integrating MCTS with a process-focused reward function, the researchers have demonstrated a way for LLMs to progressively learn and enhance their problem-solving skills without the need for extensive labeled data.
This work represents an important step towards more autonomous and capable AI systems that can learn and reason in a more self-directed manner. As the field of artificial intelligence continues to advance, techniques like ReST-MCTS* may play a key role in helping large language models become more robust, reliable, and beneficial to society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Enhancing Biomedical Knowledge Retrieval-Augmented Generation with Self-Rewarding Tree Search and Proximal Policy Optimization
Minda Hu, Licheng Zong, Hongru Wang, Jingyan Zhou, Jingjing Li, Yichen Gao, Kam-Fai Wong, Yu Li, Irwin King
0
0
Large Language Models (LLMs) have shown great potential in the biomedical domain with the advancement of retrieval-augmented generation (RAG). However, existing retrieval-augmented approaches face challenges in addressing diverse queries and documents, particularly for medical knowledge queries, resulting in sub-optimal performance. To address these limitations, we propose a novel plug-and-play LLM-based retrieval method called Self-Rewarding Tree Search (SeRTS) based on Monte Carlo Tree Search (MCTS) and a self-rewarding paradigm. By combining the reasoning capabilities of LLMs with the effectiveness of tree search, SeRTS boosts the zero-shot performance of retrieving high-quality and informative results for RAG. We further enhance retrieval performance by fine-tuning LLMs with Proximal Policy Optimization (PPO) objectives using the trajectories collected by SeRTS as feedback. Controlled experiments using the BioASQ-QA dataset with GPT-3.5-Turbo and LLama2-7b demonstrate that our method significantly improves the performance of the BM25 retriever and surpasses the strong baseline of self-reflection in both efficiency and scalability. Moreover, SeRTS generates higher-quality feedback for PPO training than self-reflection. Our proposed method effectively adapts LLMs to document retrieval tasks, enhancing their ability to retrieve highly relevant documents for RAG in the context of medical knowledge queries. This work presents a significant step forward in leveraging LLMs for accurate and comprehensive biomedical question answering.
6/18/2024
Improve Mathematical Reasoning in Language Models by Automated Process Supervision
Liangchen Luo, Yinxiao Liu, Rosanne Liu, Samrat Phatale, Harsh Lara, Yunxuan Li, Lei Shu, Yun Zhu, Lei Meng, Jiao Sun, Abhinav Rastogi
0
0
Complex multi-step reasoning tasks, such as solving mathematical problems or generating code, remain a significant hurdle for even the most advanced large language models (LLMs). Verifying LLM outputs with an Outcome Reward Model (ORM) is a standard inference-time technique aimed at enhancing the reasoning performance of LLMs. However, this still proves insufficient for reasoning tasks with a lengthy or multi-hop reasoning chain, where the intermediate outcomes are neither properly rewarded nor penalized. Process supervision addresses this limitation by assigning intermediate rewards during the reasoning process. To date, the methods used to collect process supervision data have relied on either human annotation or per-step Monte Carlo estimation, both prohibitively expensive to scale, thus hindering the broad application of this technique. In response to this challenge, we propose a novel divide-and-conquer style Monte Carlo Tree Search (MCTS) algorithm named textit{OmegaPRM} for the efficient collection of high-quality process supervision data. This algorithm swiftly identifies the first error in the Chain of Thought (CoT) with binary search and balances the positive and negative examples, thereby ensuring both efficiency and quality. As a result, we are able to collect over 1.5 million process supervision annotations to train a Process Reward Model (PRM). Utilizing this fully automated process supervision alongside the weighted self-consistency algorithm, we have enhanced the instruction tuned Gemini Pro model's math reasoning performance, achieving a 69.4% success rate on the MATH benchmark, a 36% relative improvement from the 51% base model performance. Additionally, the entire process operates without any human intervention, making our method both financially and computationally cost-effective compared to existing methods.
6/12/2024
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
6/19/2024

Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
Di Zhang, Xiaoshui Huang, Dongzhan Zhou, Yuqiang Li, Wanli Ouyang
0
0
This paper introduces the MCT Self-Refine (MCTSr) algorithm, an innovative integration of Large Language Models (LLMs) with Monte Carlo Tree Search (MCTS), designed to enhance performance in complex mathematical reasoning tasks. Addressing the challenges of accuracy and reliability in LLMs, particularly in strategic and mathematical reasoning, MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance. Extensive experiments demonstrate MCTSr's efficacy in solving Olympiad-level mathematical problems, significantly improving success rates across multiple datasets, including GSM8K, GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench. The study advances the application of LLMs in complex reasoning tasks and sets a foundation for future AI integration, enhancing decision-making accuracy and reliability in LLM-driven applications.
6/14/2024