Step-level Value Preference Optimization for Mathematical Reasoning
2406.10858
0
0

Abstract
Direct Preference Optimization (DPO) using an implicit reward model has proven to be an effective alternative to reinforcement learning from human feedback (RLHF) for fine-tuning preference aligned large language models (LLMs). However, the overall preference annotations of responses do not fully capture the fine-grained quality of model outputs in complex multi-step reasoning tasks, such as mathematical reasoning. To address this limitation, we introduce a novel algorithm called Step-level Value Preference Optimization (SVPO). Our approach employs Monte Carlo Tree Search (MCTS) to automatically annotate step-level preferences for multi-step reasoning. Furthermore, from the perspective of learning-to-rank, we train an explicit value model to replicate the behavior of the implicit reward model, complementing standard preference optimization. This value model enables the LLM to generate higher reward responses with minimal cost during inference. Experimental results demonstrate that our method achieves state-of-the-art performance on both in-domain and out-of-domain mathematical reasoning benchmarks.
Create account to get full access
Overview
- This paper proposes a method called "Step-level Value Preference Optimization" for improving mathematical reasoning in AI systems.
- The approach aims to optimize the value preferences of an AI model at the individual step level, rather than just the overall task performance.
- This is designed to lead to more reliable and interpretable mathematical reasoning capabilities.
Plain English Explanation
The paper describes a new technique for training AI models to be better at mathematical reasoning. The key idea is to optimize the model's preferences not just for the overall performance on a task, but for the individual steps along the way.
Typical AI models are trained to focus on getting the final answer right, without much attention paid to the reasoning process. This can lead to models that are good at producing the right outputs, but don't necessarily understand the underlying math concepts or show their work in an interpretable way.
The Step-level Value Preference Optimization approach tries to fix this by explicitly training the model to prefer certain intermediate steps or logical inferences over others. The goal is to create AI systems that don't just spit out answers, but can clearly explain their mathematical reasoning.
This could be useful in applications like tutoring, where an AI math assistant needs to provide step-by-step guidance, or in fields like scientific research, where the ability to follow and validate the reasoning process is crucial. By optimizing the model's preferences at a granular level, the authors hope to produce more reliable, transparent, and trustworthy mathematical reasoning capabilities.
Technical Explanation
The paper introduces a new training technique called "Step-level Value Preference Optimization" (SLVPO) for improving the mathematical reasoning abilities of AI models.
Typical reinforcement learning approaches optimize the model's overall performance on a task, but don't account for the quality or interpretability of the intermediate reasoning steps. SLVPO aims to address this by incorporating a "step-level value preference" objective, which encourages the model to prefer certain logical inferences or calculation steps over others.
The authors implement SLVPO using a two-stage training process. First, they train a "reward model" to predict the human-annotated value or preference for each step in the reasoning process. Then, they use this reward model to guide the optimization of the main AI agent, pushing it to generate step sequences that align with the learned human preferences.
The paper evaluates SLVPO on a set of mathematical reasoning tasks, comparing it to baseline reinforcement learning approaches. The results show that SLVPO leads to models that not only achieve higher overall task performance, but also generate reasoning sequences that are more aligned with human preferences and more interpretable.
The authors also analyze the types of step-level preferences the reward model learns, finding that it captures both low-level preferences (e.g., favoring certain mathematical operations) and higher-level preferences (e.g., favoring logically valid inference chains).
Critical Analysis
The SLVPO approach presented in this paper is an interesting step towards improving the transparency and interpretability of AI reasoning, particularly in mathematical domains. By optimizing for step-level preferences in addition to overall task performance, the authors aim to create AI systems that can not only solve problems, but also explain their reasoning in a way that aligns with human intuitions.
One potential limitation of the approach is the reliance on human-annotated step preferences to train the reward model. This could make the technique difficult to scale, as collecting such detailed annotations may be labor-intensive. It would be interesting to see if the authors could explore methods for learning these preferences more autonomously, perhaps by mining existing educational resources or crowdsourcing step-level evaluations.
Additionally, the paper focuses on a relatively narrow set of mathematical reasoning tasks. It would be valuable to see how well the SLVPO approach generalizes to a broader range of reasoning problems, including those that involve more complex logical structures or require higher-level abstraction and concept understanding.
Overall, this paper represents an important contribution to the field of AI-based mathematical reasoning and interpretable AI. The SLVPO technique offers a promising way to create AI systems that are not only capable, but also transparent and aligned with human preferences. Further research in this direction could lead to significant advancements in the field of AI-assisted problem-solving and tutoring.
Conclusion
This paper introduces a novel training approach called "Step-level Value Preference Optimization" (SLVPO) that aims to improve the mathematical reasoning capabilities of AI systems. By optimizing the model's preferences not just for overall task performance, but for the individual reasoning steps, the authors hope to create more reliable, transparent, and trustworthy AI agents.
The key insight behind SLVPO is that optimizing for step-level preferences, in addition to final outcomes, can lead to more interpretable and human-aligned reasoning processes. This could have significant implications for applications like educational AI assistants, scientific research tools, and other domains where the ability to explain and validate the reasoning process is crucial.
While the current implementation of SLVPO relies on human-annotated step preferences, future work in this area could explore ways to learn these preferences more autonomously. Expanding the approach to a broader range of reasoning tasks would also help solidify its generalizability and impact.
Overall, this paper represents an important contribution to the ongoing effort to develop AI systems that can not only solve problems, but also explain their reasoning in a way that is transparent and aligned with human values. As the field of AI-based mathematical reasoning continues to evolve, techniques like SLVPO will likely play an increasingly important role in creating AI agents that are both capable and trustworthy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

New!Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, Jiaya Jia
0
0
Mathematical reasoning presents a significant challenge for Large Language Models (LLMs) due to the extensive and precise chain of reasoning required for accuracy. Ensuring the correctness of each reasoning step is critical. To address this, we aim to enhance the robustness and factuality of LLMs by learning from human feedback. However, Direct Preference Optimization (DPO) has shown limited benefits for long-chain mathematical reasoning, as models employing DPO struggle to identify detailed errors in incorrect answers. This limitation stems from a lack of fine-grained process supervision. We propose a simple, effective, and data-efficient method called Step-DPO, which treats individual reasoning steps as units for preference optimization rather than evaluating answers holistically. Additionally, we have developed a data construction pipeline for Step-DPO, enabling the creation of a high-quality dataset containing 10K step-wise preference pairs. We also observe that in DPO, self-generated data is more effective than data generated by humans or GPT-4, due to the latter's out-of-distribution nature. Our findings demonstrate that as few as 10K preference data pairs and fewer than 500 Step-DPO training steps can yield a nearly 3% gain in accuracy on MATH for models with over 70B parameters. Notably, Step-DPO, when applied to Qwen2-72B-Instruct, achieves scores of 70.8% and 94.0% on the test sets of MATH and GSM8K, respectively, surpassing a series of closed-source models, including GPT-4-1106, Claude-3-Opus, and Gemini-1.5-Pro. Our code, data, and models are available at https://github.com/dvlab-research/Step-DPO.
6/28/2024
🔎
Monte Carlo Tree Search Boosts Reasoning via Iterative Preference Learning
Yuxi Xie, Anirudh Goyal, Wenyue Zheng, Min-Yen Kan, Timothy P. Lillicrap, Kenji Kawaguchi, Michael Shieh
0
0
We introduce an approach aimed at enhancing the reasoning capabilities of Large Language Models (LLMs) through an iterative preference learning process inspired by the successful strategy employed by AlphaZero. Our work leverages Monte Carlo Tree Search (MCTS) to iteratively collect preference data, utilizing its look-ahead ability to break down instance-level rewards into more granular step-level signals. To enhance consistency in intermediate steps, we combine outcome validation and stepwise self-evaluation, continually updating the quality assessment of newly generated data. The proposed algorithm employs Direct Preference Optimization (DPO) to update the LLM policy using this newly generated step-level preference data. Theoretical analysis reveals the importance of using on-policy sampled data for successful self-improving. Extensive evaluations on various arithmetic and commonsense reasoning tasks demonstrate remarkable performance improvements over existing models. For instance, our approach outperforms the Mistral-7B Supervised Fine-Tuning (SFT) baseline on GSM8K, MATH, and ARC-C, with substantial increases in accuracy to $81.8%$ (+$5.9%$), $34.7%$ (+$5.8%$), and $76.4%$ (+$15.8%$), respectively. Additionally, our research delves into the training and inference compute tradeoff, providing insights into how our method effectively maximizes performance gains. Our code is publicly available at https://github.com/YuxiXie/MCTS-DPO.
6/19/2024
✅
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Fangkai Jiao, Chengwei Qin, Zhengyuan Liu, Nancy F. Chen, Shafiq Joty
0
0
Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through Direct Preference Optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
4/16/2024
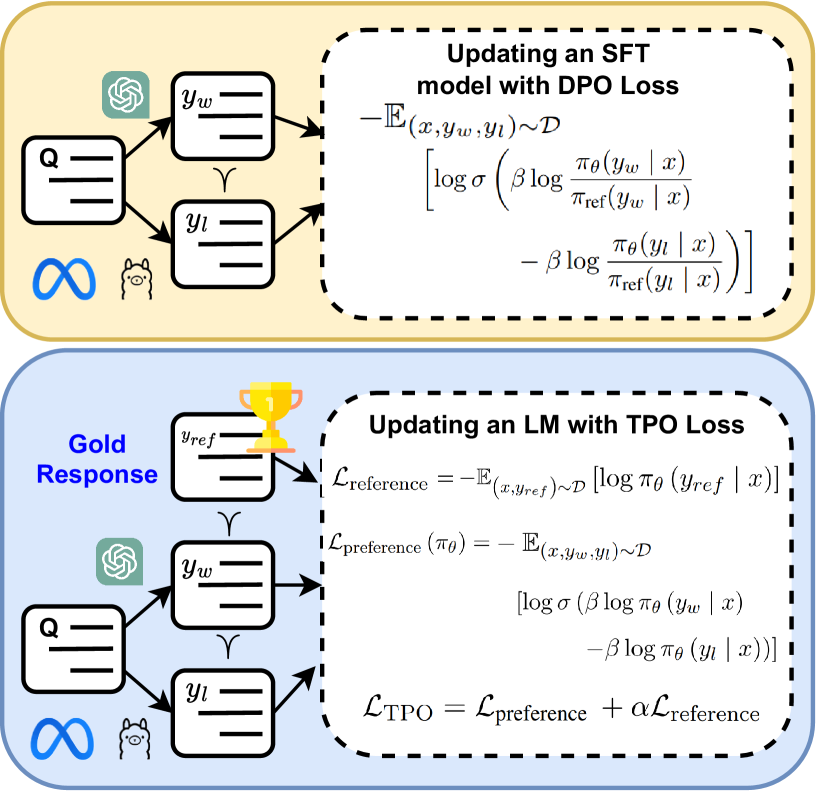
Triple Preference Optimization: Achieving Better Alignment with Less Data in a Single Step Optimization
Amir Saeidi, Shivanshu Verma, Aswin RRV, Chitta Baral
0
0
Large Language Models (LLMs) perform well across diverse tasks, but aligning them with human demonstrations is challenging. Recently, Reinforcement Learning (RL)-free methods like Direct Preference Optimization (DPO) have emerged, offering improved stability and scalability while retaining competitive performance relative to RL-based methods. However, while RL-free methods deliver satisfactory performance, they require significant data to develop a robust Supervised Fine-Tuned (SFT) model and an additional step to fine-tune this model on a preference dataset, which constrains their utility and scalability. In this paper, we introduce Triple Preference Optimization (TPO), a new preference learning method designed to align an LLM with three preferences without requiring a separate SFT step and using considerably less data. Through a combination of practical experiments and theoretical analysis, we show the efficacy of TPO as a single-step alignment strategy. Specifically, we fine-tuned the Phi-2 (2.7B) and Mistral (7B) models using TPO directly on the UltraFeedback dataset, achieving superior results compared to models aligned through other methods such as SFT, DPO, KTO, IPO, CPO, and ORPO. Moreover, the performance of TPO without the SFT component led to notable improvements in the MT-Bench score, with increases of +1.27 and +0.63 over SFT and DPO, respectively. Additionally, TPO showed higher average accuracy, surpassing DPO and SFT by 4.2% and 4.97% on the Open LLM Leaderboard benchmarks. Our code is publicly available at https://github.com/sahsaeedi/triple-preference-optimization .
5/28/2024