Downstream bias mitigation is all you need

0
📈
Sign in to get full access
Overview
- Transformer-based architectures and large language models (LLMs) have significantly advanced natural language processing (NLP) performance.
- LLMs trained on web data may absorb harmful biases from the data.
- Fine-tuning LLMs on task-specific datasets can further contribute to biases.
- This paper investigates biases in pre-trained LLMs and the impact of fine-tuning on bias.
Plain English Explanation
Recent advancements in natural language processing (NLP) have been driven by powerful transformer-based architectures and large language models (LLMs). These LLMs are trained on vast amounts of data from the internet and other sources. However, this data may contain harmful biases, which can then get absorbed by the LLMs.
When these pre-trained LLMs are fine-tuned on specific tasks using domain-specific datasets, the biases in those datasets can further contribute to the model's biases. This paper explores the extent of biases in pre-trained LLMs and how the fine-tuning process impacts those biases.
Technical Explanation
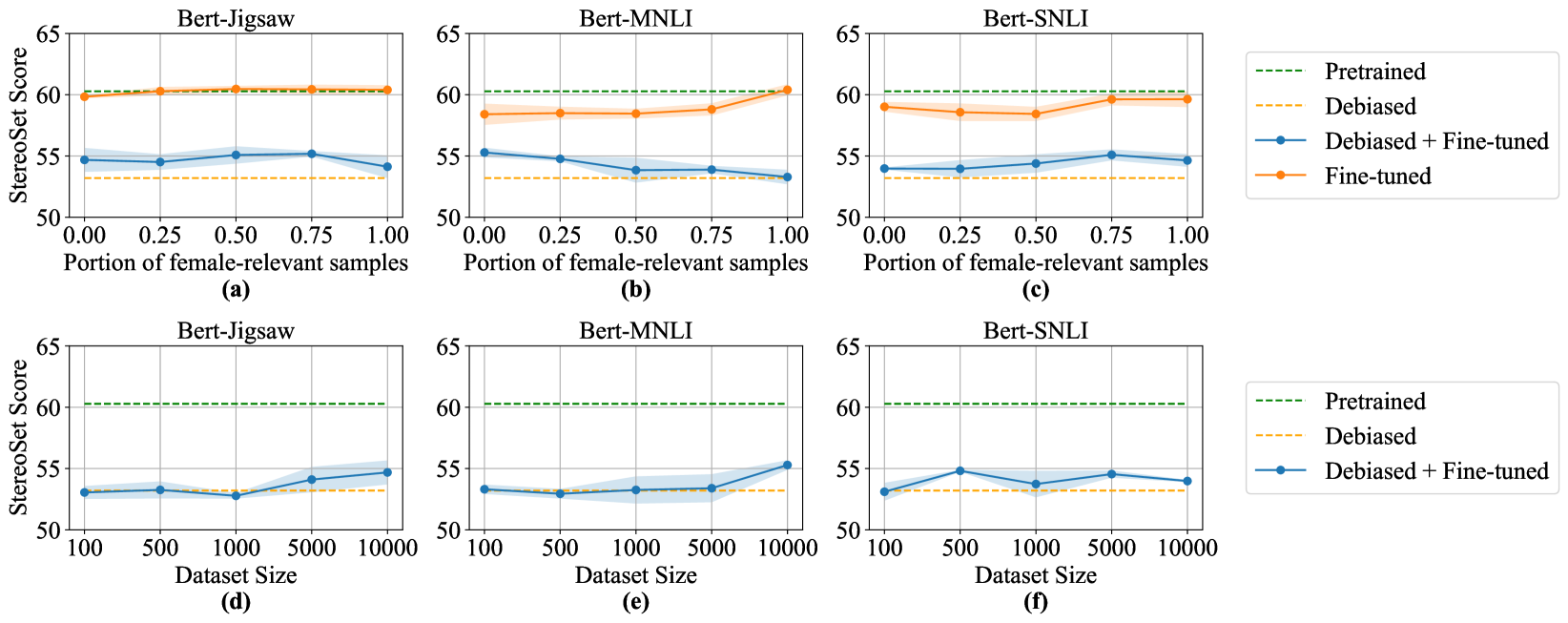
The researchers found that making controlled interventions on pre-trained LLMs before fine-tuning had minimal effect on reducing biases in the resulting classifiers. However, the biases present in the domain-specific datasets used for fine-tuning played a much bigger role. Mitigating biases at the fine-tuning stage had a more significant impact.
While the biases present in the pre-training data do matter, the researchers found that even small changes in the co-occurrence rates within the fine-tuning dataset can have a substantial effect on the bias of the final model. This suggests that the fine-tuning stage is critical for addressing biases in LLMs.
Critical Analysis
The paper acknowledges some limitations of the study, such as the challenge of definitively measuring and attributing biases in LLMs. The researchers also note that their findings may be specific to the particular tasks and datasets they examined, and that further research is needed to understand the generalizability of their conclusions.
Additionally, the paper does not delve into the potential sources or societal implications of the biases observed in the LLMs and fine-tuned models. Readers may want to critically consider the broader ethical and societal ramifications of biases in these powerful language models.
Conclusion
This study highlights the importance of carefully managing biases at the fine-tuning stage of LLM development, as this appears to have a more significant impact than interventions made during the pre-training phase. As these models become increasingly prevalent in various applications, understanding and mitigating biases will be crucial to ensuring fair and equitable outcomes for all users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Downstream bias mitigation is all you need
Arkadeep Baksi, Rahul Singh, Tarun Joshi
The advent of transformer-based architectures and large language models (LLMs) have significantly advanced the performance of natural language processing (NLP) models. Since these LLMs are trained on huge corpuses of data from the web and other sources, there has been a major concern about harmful prejudices that may potentially be transferred from the data. In many applications, these pre-trained LLMs are fine-tuned on task specific datasets, which can further contribute to biases. This paper studies the extent of biases absorbed by LLMs during pre-training as well as task-specific behaviour after fine-tuning. We found that controlled interventions on pre-trained LLMs, prior to fine-tuning, have minimal effect on lowering biases in classifiers. However, the biases present in domain-specific datasets play a much bigger role, and hence mitigating them at this stage has a bigger impact. While pre-training does matter, but after the model has been pre-trained, even slight changes to co-occurrence rates in the fine-tuning dataset has a significant effect on the bias of the model.
Read more8/29/2024
0
Towards Understanding Task-agnostic Debiasing Through the Lenses of Intrinsic Bias and Forgetfulness
Guangliang Liu, Milad Afshari, Xitong Zhang, Zhiyu Xue, Avrajit Ghosh, Bidhan Bashyal, Rongrong Wang, Kristen Johnson
While task-agnostic debiasing provides notable generalizability and reduced reliance on downstream data, its impact on language modeling ability and the risk of relearning social biases from downstream task-specific data remain as the two most significant challenges when debiasing Pretrained Language Models (PLMs). The impact on language modeling ability can be alleviated given a high-quality and long-contextualized debiasing corpus, but there remains a deficiency in understanding the specifics of relearning biases. We empirically ascertain that the effectiveness of task-agnostic debiasing hinges on the quantitative bias level of both the task-specific data used for downstream applications and the debiased model. We empirically show that the lower bound of the bias level of the downstream fine-tuned model can be approximated by the bias level of the debiased model, in most practical cases. To gain more in-depth understanding about how the parameters of PLMs change during fine-tuning due to the forgetting issue of PLMs, we propose a novel framework which can Propagate Socially-fair Debiasing to Downstream Fine-tuning, ProSocialTuning. Our proposed framework can push the fine-tuned model to approach the bias lower bound during downstream fine-tuning, indicating that the ineffectiveness of debiasing can be alleviated by overcoming the forgetting issue through regularizing successfully debiased attention heads based on the PLMs' bias levels from stages of pretraining and debiasing.
Read more6/7/2024

0
Understanding the Interplay of Scale, Data, and Bias in Language Models: A Case Study with BERT
Muhammad Ali, Swetasudha Panda, Qinlan Shen, Michael Wick, Ari Kobren
In the current landscape of language model research, larger models, larger datasets and more compute seems to be the only way to advance towards intelligence. While there have been extensive studies of scaling laws and models' scaling behaviors, the effect of scale on a model's social biases and stereotyping tendencies has received less attention. In this study, we explore the influence of model scale and pre-training data on its learnt social biases. We focus on BERT -- an extremely popular language model -- and investigate biases as they show up during language modeling (upstream), as well as during classification applications after fine-tuning (downstream). Our experiments on four architecture sizes of BERT demonstrate that pre-training data substantially influences how upstream biases evolve with model scale. With increasing scale, models pre-trained on large internet scrapes like Common Crawl exhibit higher toxicity, whereas models pre-trained on moderated data sources like Wikipedia show greater gender stereotypes. However, downstream biases generally decrease with increasing model scale, irrespective of the pre-training data. Our results highlight the qualitative role of pre-training data in the biased behavior of language models, an often overlooked aspect in the study of scale. Through a detailed case study of BERT, we shed light on the complex interplay of data and model scale, and investigate how it translates to concrete biases.
Read more8/1/2024
0
Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs
Ahmed Agiza, Mohamed Mostagir, Sherief Reda
In an era where language models are increasingly integrated into decision-making and communication, understanding the biases within Large Language Models (LLMs) becomes imperative, especially when these models are applied in the economic and political domains. This work investigates the impact of fine-tuning and data selection on economic and political biases in LLMs. In this context, we introduce PoliTune, a fine-tuning methodology to explore the systematic aspects of aligning LLMs with specific ideologies, mindful of the biases that arise from their extensive training on diverse datasets. Distinct from earlier efforts that either focus on smaller models or entail resource-intensive pre-training, PoliTune employs Parameter-Efficient Fine-Tuning (PEFT) techniques, which allow for the alignment of LLMs with targeted ideologies by modifying a small subset of parameters. We introduce a systematic method for using the open-source LLM Llama3-70B for dataset selection, annotation, and synthesizing a preferences dataset for Direct Preference Optimization (DPO) to align the model with a given political ideology. We assess the effectiveness of PoliTune through both quantitative and qualitative evaluations of aligning open-source LLMs (Llama3-8B and Mistral-7B) to different ideologies. Our work analyzes the potential of embedding specific biases into LLMs and contributes to the dialogue on the ethical application of AI, highlighting the importance of deploying AI in a manner that aligns with societal values.
Read more7/30/2024