Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs

0
Sign in to get full access
Overview
• This paper investigates how the data selection and fine-tuning process can impact the economic and political biases present in large language models (LLMs). • The researchers explore how adjusting the training data and fine-tuning approach can potentially mitigate or exacerbate biases in model outputs. • The findings have important implications for the responsible development and deployment of LLMs, particularly in domains where biases can have significant societal consequences.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, these models can also reflect and amplify societal biases present in their training data, such as biases related to economics and politics.
This paper examines how the specific data used to train LLMs and the way the models are fine-tuned (further trained) can influence the presence of these economic and political biases. The researchers explore different approaches to data selection and fine-tuning, and analyze how they impact the biases present in the model outputs.
The findings from this research are important because LLMs are increasingly being deployed in real-world applications, such as chatbots and content generation. If these models exhibit significant biases, it could lead to unfair or harmful outcomes, especially in domains like policy-making or research synthesis. By understanding how to mitigate biases through careful data selection and fine-tuning, the researchers aim to help ensure that LLMs are developed and used responsibly.
Technical Explanation
The paper begins by providing an overview of large language models (LLMs) and the various ways they can exhibit biases, particularly in the economic and political domains. The authors note that while LLMs have shown impressive performance on a wide range of tasks, they can also reflect and amplify societal biases present in their training data.
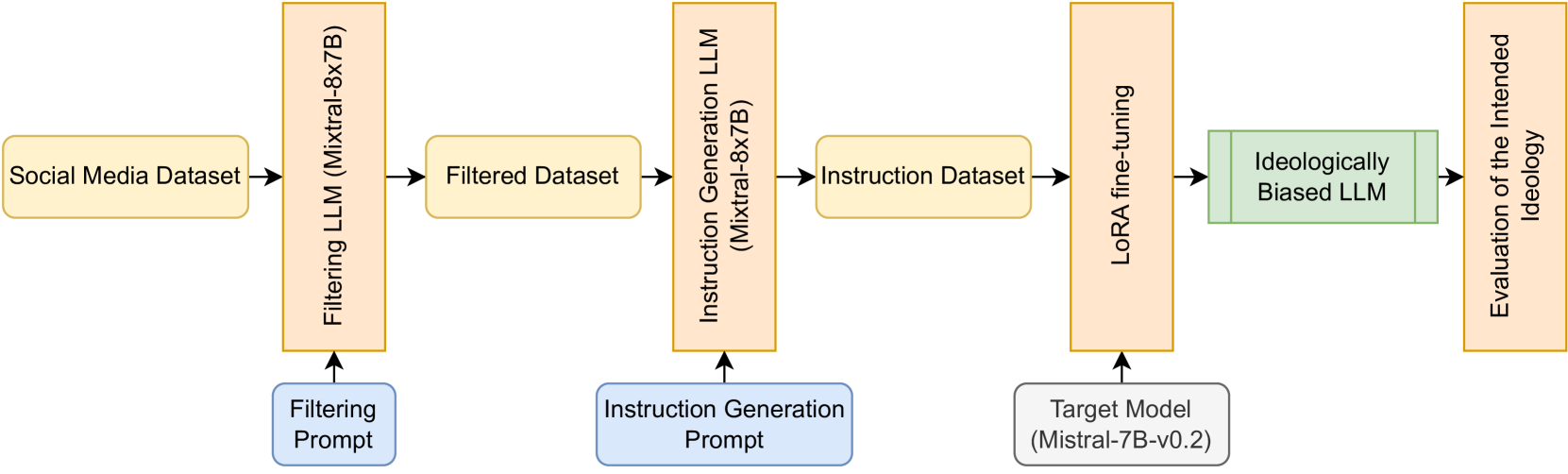
To investigate this issue, the researchers conducted a series of experiments examining the impact of data selection and fine-tuning on the economic and political biases present in LLM outputs. They experimented with different approaches to data curation, including sourcing data from a variety of perspectives and using techniques like debiasing and position-aware fine-tuning.
The results suggest that the choice of training data and fine-tuning approach can have a significant influence on the biases exhibited by the resulting LLMs. The researchers found that carefully curating the training data and applying targeted fine-tuning techniques can help mitigate certain biases, while other approaches may inadvertently exacerbate them.
Critical Analysis
The paper provides a thorough and well-designed investigation into the complex issue of bias in large language models. The researchers have carefully considered the potential impacts of data selection and fine-tuning, and their findings offer valuable insights for the responsible development of LLMs.
However, the paper also acknowledges several limitations and areas for further research. For example, the authors note that their experiments focused on a specific set of economic and political biases, and that additional work is needed to explore a broader range of biases and their interactions. There is also a need to investigate the long-term stability of the debiasing approaches and their performance in real-world deployment scenarios.
Additionally, the paper does not address the potential vulnerabilities that can arise from certain fine-tuning and optimization techniques, which could have important implications for the practical implementation of the proposed methods.
Overall, this paper makes a significant contribution to the ongoing efforts to understand and mitigate biases in large language models. By highlighting the importance of careful data curation and fine-tuning, the researchers have provided a valuable framework for researchers and practitioners to consider as they work to develop and deploy LLMs responsibly.
Conclusion
This paper presents a comprehensive investigation into the impact of data selection and fine-tuning on the economic and political biases present in large language models (LLMs). The researchers demonstrate that the specific choices made during the training and fine-tuning process can have a significant influence on the biases exhibited by the resulting models.
The findings from this work have important implications for the responsible development and deployment of LLMs, particularly in domains where biases can have substantial societal consequences. By understanding how to mitigate biases through careful data curation and targeted fine-tuning, the researchers aim to help ensure that these powerful AI systems are used in a way that promotes fairness and equity.
As LLMs continue to advance and become more widely adopted, the insights and methodologies presented in this paper will be crucial for guiding the research and development community towards the responsible and ethical use of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Analyzing the Impact of Data Selection and Fine-Tuning on Economic and Political Biases in LLMs
Ahmed Agiza, Mohamed Mostagir, Sherief Reda
In an era where language models are increasingly integrated into decision-making and communication, understanding the biases within Large Language Models (LLMs) becomes imperative, especially when these models are applied in the economic and political domains. This work investigates the impact of fine-tuning and data selection on economic and political biases in LLMs. In this context, we introduce PoliTune, a fine-tuning methodology to explore the systematic aspects of aligning LLMs with specific ideologies, mindful of the biases that arise from their extensive training on diverse datasets. Distinct from earlier efforts that either focus on smaller models or entail resource-intensive pre-training, PoliTune employs Parameter-Efficient Fine-Tuning (PEFT) techniques, which allow for the alignment of LLMs with targeted ideologies by modifying a small subset of parameters. We introduce a systematic method for using the open-source LLM Llama3-70B for dataset selection, annotation, and synthesizing a preferences dataset for Direct Preference Optimization (DPO) to align the model with a given political ideology. We assess the effectiveness of PoliTune through both quantitative and qualitative evaluations of aligning open-source LLMs (Llama3-8B and Mistral-7B) to different ideologies. Our work analyzes the potential of embedding specific biases into LLMs and contributes to the dialogue on the ethical application of AI, highlighting the importance of deploying AI in a manner that aligns with societal values.
Read more7/30/2024
💬
0
Assessing Political Bias in Large Language Models
Luca Rettenberger, Markus Reischl, Mark Schutera
The assessment of bias within Large Language Models (LLMs) has emerged as a critical concern in the contemporary discourse surrounding Artificial Intelligence (AI) in the context of their potential impact on societal dynamics. Recognizing and considering political bias within LLM applications is especially important when closing in on the tipping point toward performative prediction. Then, being educated about potential effects and the societal behavior LLMs can drive at scale due to their interplay with human operators. In this way, the upcoming elections of the European Parliament will not remain unaffected by LLMs. We evaluate the political bias of the currently most popular open-source LLMs (instruct or assistant models) concerning political issues within the European Union (EU) from a German voter's perspective. To do so, we use the Wahl-O-Mat, a voting advice application used in Germany. From the voting advice of the Wahl-O-Mat we quantize the degree of alignment of LLMs with German political parties. We show that larger models, such as Llama3-70B, tend to align more closely with left-leaning political parties, while smaller models often remain neutral, particularly when prompted in English. The central finding is that LLMs are similarly biased, with low variances in the alignment concerning a specific party. Our findings underline the importance of rigorously assessing and making bias transparent in LLMs to safeguard the integrity and trustworthiness of applications that employ the capabilities of performative prediction and the invisible hand of machine learning prediction and language generation.
Read more6/6/2024

0
The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities
Venkatesh Balavadhani Parthasarathy, Ahtsham Zafar, Aafaq Khan, Arsalan Shahid
This report examines the fine-tuning of Large Language Models (LLMs), integrating theoretical insights with practical applications. It outlines the historical evolution of LLMs from traditional Natural Language Processing (NLP) models to their pivotal role in AI. A comparison of fine-tuning methodologies, including supervised, unsupervised, and instruction-based approaches, highlights their applicability to different tasks. The report introduces a structured seven-stage pipeline for fine-tuning LLMs, spanning data preparation, model initialization, hyperparameter tuning, and model deployment. Emphasis is placed on managing imbalanced datasets and optimization techniques. Parameter-efficient methods like Low-Rank Adaptation (LoRA) and Half Fine-Tuning are explored for balancing computational efficiency with performance. Advanced techniques such as memory fine-tuning, Mixture of Experts (MoE), and Mixture of Agents (MoA) are discussed for leveraging specialized networks and multi-agent collaboration. The report also examines novel approaches like Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), which align LLMs with human preferences, alongside pruning and routing optimizations to improve efficiency. Further sections cover validation frameworks, post-deployment monitoring, and inference optimization, with attention to deploying LLMs on distributed and cloud-based platforms. Emerging areas such as multimodal LLMs, fine-tuning for audio and speech, and challenges related to scalability, privacy, and accountability are also addressed. This report offers actionable insights for researchers and practitioners navigating LLM fine-tuning in an evolving landscape.
Read more8/27/2024

0
Examining the Influence of Political Bias on Large Language Model Performance in Stance Classification
Lynnette Hui Xian Ng, Iain Cruickshank, Roy Ka-Wei Lee
Large Language Models (LLMs) have demonstrated remarkable capabilities in executing tasks based on natural language queries. However, these models, trained on curated datasets, inherently embody biases ranging from racial to national and gender biases. It remains uncertain whether these biases impact the performance of LLMs for certain tasks. In this study, we investigate the political biases of LLMs within the stance classification task, specifically examining whether these models exhibit a tendency to more accurately classify politically-charged stances. Utilizing three datasets, seven LLMs, and four distinct prompting schemes, we analyze the performance of LLMs on politically oriented statements and targets. Our findings reveal a statistically significant difference in the performance of LLMs across various politically oriented stance classification tasks. Furthermore, we observe that this difference primarily manifests at the dataset level, with models and prompting schemes showing statistically similar performances across different stance classification datasets. Lastly, we observe that when there is greater ambiguity in the target the statement is directed towards, LLMs have poorer stance classification accuracy. Code & Dataset: http://doi.org/10.5281/zenodo.12938478
Read more7/29/2024