Dr-LLaVA: Visual Instruction Tuning with Symbolic Clinical Grounding

0
Sign in to get full access
Overview
- This paper presents Dr-LLaVA, a visual instruction tuning approach that leverages symbolic clinical grounding to improve the performance of large language models on medical tasks.
- The key idea is to fine-tune a large vision-language model (LLM) on a dataset of clinical instructions and corresponding medical images, in order to better understand and follow visual instructions in a clinical context.
- The authors propose using a symbolic knowledge base to ground the language model's understanding of medical concepts, helping it reason more accurately about visual instructions.
- Experiments on a medical image-based visual instructions dataset show that Dr-LLaVA outperforms standard fine-tuning approaches, demonstrating the benefits of the symbolic clinical grounding.
Plain English Explanation
The paper introduces a new approach called Dr-LLaVA that aims to improve how large language models (LLMs) can understand and follow visual instructions in a medical context. LLMs are powerful AI systems that can process and generate human-like text, but they can struggle with tasks that require specific domain knowledge, like understanding medical procedures.
To address this, the researchers fine-tuned an LLM on a dataset of clinical instructions paired with corresponding medical images. This helps the model learn the connections between the language used in medical settings and the visual information it needs to interpret those instructions correctly.
But the key innovation is that the researchers also used a symbolic knowledge base - a structured database of medical concepts and their relationships - to further ground the language model's understanding. This symbolic grounding allows the model to reason more accurately about the medical terminology and content in the visual instructions, rather than just memorizing patterns in the training data.
The experiments show that this approach, called Dr-LLaVA, outperforms standard fine-tuning methods on a dataset of medical image-based instructions. This suggests that the symbolic clinical grounding helps the language model better comprehend and follow the visual guidance, which could be valuable for applications like assisting clinicians or training medical students.
Technical Explanation
The core of the Dr-LLaVA approach is to fine-tune a large vision-language model (LLM) on a dataset of clinical instructions paired with corresponding medical images. This helps the model learn the connections between the language used in medical settings and the visual information needed to interpret those instructions.
To further enhance the model's medical reasoning capabilities, the authors propose incorporating a symbolic knowledge base to ground the language model's understanding. Specifically, they use an ontology of medical concepts and their relationships to help the model reason more accurately about the clinical terminology and content in the visual instructions.
The full Dr-LLaVA architecture consists of a vision-language backbone model (e.g. VisualGPT or VD-GD) that is fine-tuned on the medical image-instruction dataset. In parallel, the model also learns to map the text to corresponding concepts in the symbolic medical ontology. This allows the language understanding to be grounded in the structured medical knowledge.
The experiments evaluate Dr-LLaVA on a benchmark dataset of medical image-based instructions, showing that it outperforms standard fine-tuning approaches. The authors attribute this improved performance to the symbolic clinical grounding, which helps the model reason more accurately about the visual instructions in a medical context.
Critical Analysis
The paper presents a compelling approach for improving LLMs' understanding of medical visual instructions through the use of symbolic clinical grounding. The authors make a strong case for the benefits of this technique, demonstrating clear performance gains on a relevant benchmark task.
That said, the paper could have provided more details on the specific medical ontology used and how it was integrated into the model training. Additionally, it would have been interesting to see an analysis of the types of errors or failures the standard fine-tuned model made, versus the errors reduced by the symbolic grounding approach.
Some potential limitations of the work include the reliance on a curated medical ontology, which may not be available or comprehensive for all domains. Additionally, the performance gains, while significant, may be relatively modest compared to the additional complexity introduced by the symbolic grounding component.
Further research could explore ways to make the symbolic integration more scalable and generalizable, perhaps through techniques like knowledge-grounded adaptation or mitigating hallucinations with cognitive prompts. Studying the model's internal reasoning and decision-making process could also yield insights into how the symbolic grounding improves performance.
Overall, the Dr-LLaVA approach represents an interesting and promising step towards making large language models more reliable and effective in specialized domains like healthcare. The use of symbolic knowledge to ground language understanding is an important area of research that could lead to more robust and trustworthy AI systems.
Conclusion
The Dr-LLaVA paper presents a novel approach to improving the performance of large language models on medical visual instruction tasks. By fine-tuning the models on a dataset of clinical instructions and medical images, while also leveraging a symbolic knowledge base to ground the language understanding, the researchers demonstrate significant gains over standard fine-tuning methods.
This work highlights the potential benefits of combining the representational power of large language models with structured domain knowledge to tackle specialized tasks that require both language and visual understanding. As LLMs continue to be applied in high-stakes domains like healthcare, techniques like the symbolic clinical grounding used in Dr-LLaVA will be increasingly important for ensuring the reliability and trustworthiness of these AI systems.
While the paper leaves room for further exploration and refinement, it represents an important contribution to the field of vision-language modeling, with promising implications for improving the capabilities of large language models in real-world medical and clinical applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dr-LLaVA: Visual Instruction Tuning with Symbolic Clinical Grounding
Shenghuan Sun, Gregory M. Goldgof, Alexander Schubert, Zhiqing Sun, Thomas Hartvigsen, Atul J. Butte, Ahmed Alaa
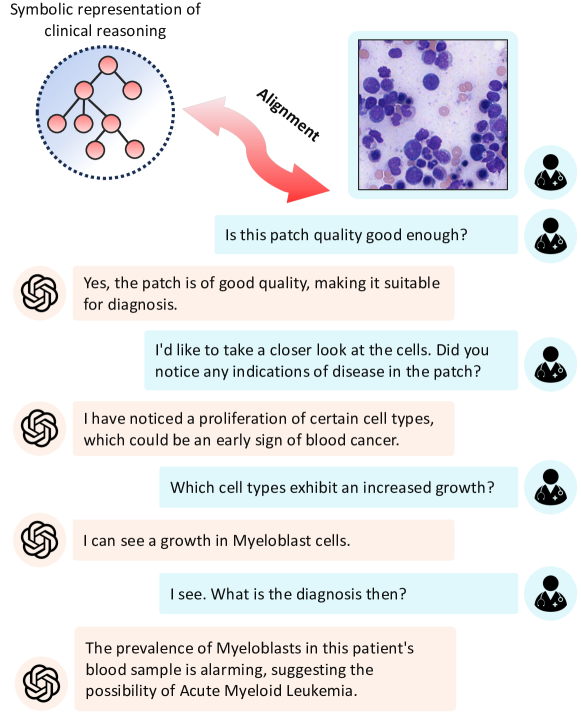
Vision-Language Models (VLM) can support clinicians by analyzing medical images and engaging in natural language interactions to assist in diagnostic and treatment tasks. However, VLMs often exhibit hallucinogenic behavior, generating textual outputs not grounded in contextual multimodal information. This challenge is particularly pronounced in the medical domain, where we do not only require VLM outputs to be accurate in single interactions but also to be consistent with clinical reasoning and diagnostic pathways throughout multi-turn conversations. For this purpose, we propose a new alignment algorithm that uses symbolic representations of clinical reasoning to ground VLMs in medical knowledge. These representations are utilized to (i) generate GPT-4-guided visual instruction tuning data at scale, simulating clinician-VLM conversations with demonstrations of clinical reasoning, and (ii) create an automatic reward function that evaluates the clinical validity of VLM generations throughout clinician-VLM interactions. Our algorithm eliminates the need for human involvement in training data generation or reward model construction, reducing costs compared to standard reinforcement learning with human feedback (RLHF). We apply our alignment algorithm to develop Dr-LLaVA, a conversational VLM finetuned for analyzing bone marrow pathology slides, demonstrating strong performance in multi-turn medical conversations.
Read more5/31/2024
0
Vision-Language Models for Medical Report Generation and Visual Question Answering: A Review
Iryna Hartsock, Ghulam Rasool
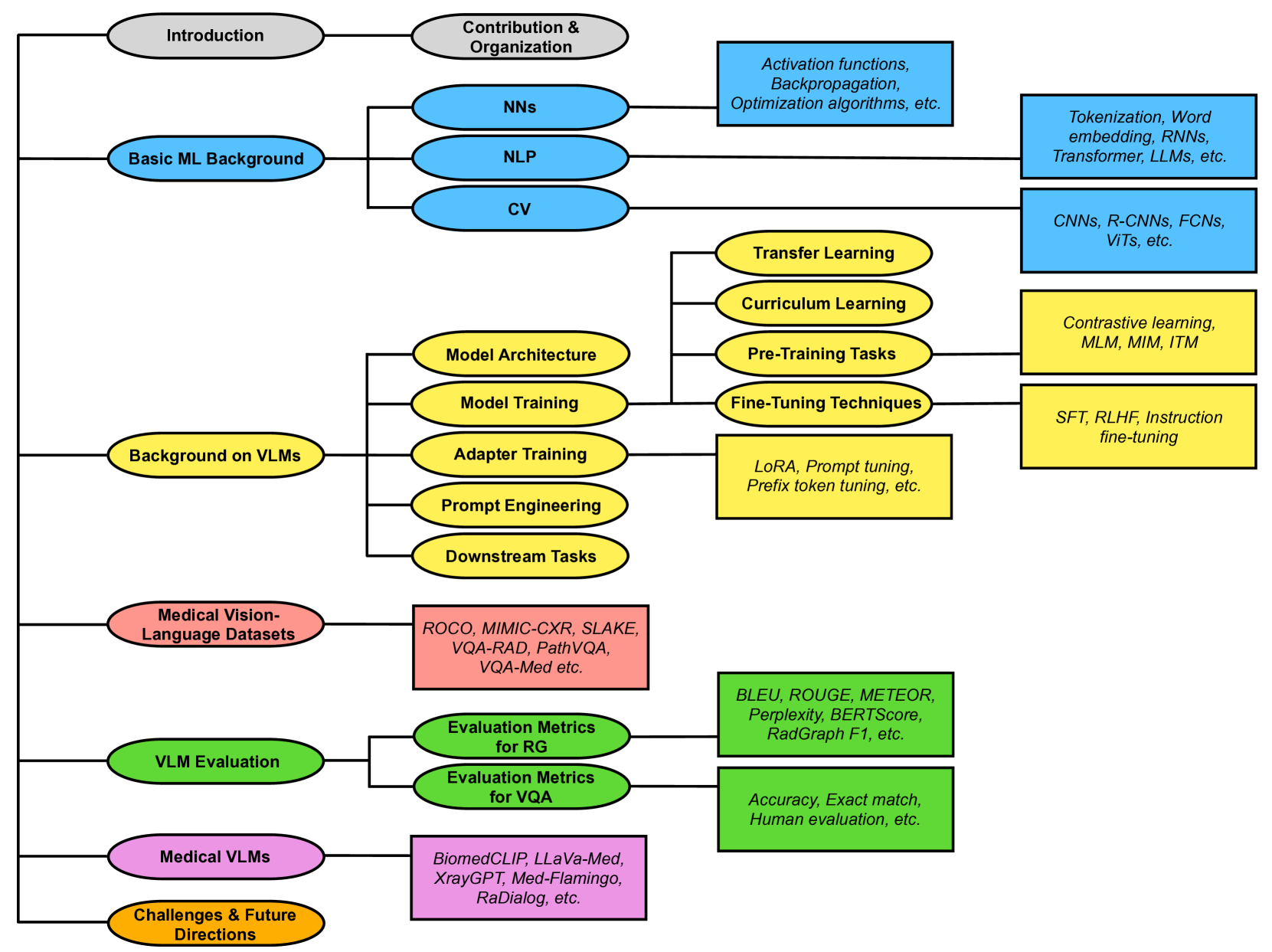
Medical vision-language models (VLMs) combine computer vision (CV) and natural language processing (NLP) to analyze visual and textual medical data. Our paper reviews recent advancements in developing VLMs specialized for healthcare, focusing on models designed for medical report generation and visual question answering (VQA). We provide background on NLP and CV, explaining how techniques from both fields are integrated into VLMs to enable learning from multimodal data. Key areas we address include the exploration of medical vision-language datasets, in-depth analyses of architectures and pre-training strategies employed in recent noteworthy medical VLMs, and comprehensive discussion on evaluation metrics for assessing VLMs' performance in medical report generation and VQA. We also highlight current challenges and propose future directions, including enhancing clinical validity and addressing patient privacy concerns. Overall, our review summarizes recent progress in developing VLMs to harness multimodal medical data for improved healthcare applications.
Read more4/16/2024
📈
0
Surgical-LVLM: Learning to Adapt Large Vision-Language Model for Grounded Visual Question Answering in Robotic Surgery
Guankun Wang, Long Bai, Wan Jun Nah, Jie Wang, Zhaoxi Zhang, Zhen Chen, Jinlin Wu, Mobarakol Islam, Hongbin Liu, Hongliang Ren
Recent advancements in Surgical Visual Question Answering (Surgical-VQA) and related region grounding have shown great promise for robotic and medical applications, addressing the critical need for automated methods in personalized surgical mentorship. However, existing models primarily provide simple structured answers and struggle with complex scenarios due to their limited capability in recognizing long-range dependencies and aligning multimodal information. In this paper, we introduce Surgical-LVLM, a novel personalized large vision-language model tailored for complex surgical scenarios. Leveraging the pre-trained large vision-language model and specialized Visual Perception LoRA (VP-LoRA) blocks, our model excels in understanding complex visual-language tasks within surgical contexts. In addressing the visual grounding task, we propose the Token-Interaction (TIT) module, which strengthens the interaction between the grounding module and the language responses of the Large Visual Language Model (LVLM) after projecting them into the latent space. We demonstrate the effectiveness of Surgical-LVLM on several benchmarks, including EndoVis-17-VQLA, EndoVis-18-VQLA, and a newly introduced EndoVis Conversations dataset, which sets new performance standards. Our work contributes to advancing the field of automated surgical mentorship by providing a context-aware solution.
Read more5/21/2024

0
MedThink: Inducing Medical Large-scale Visual Language Models to Hallucinate Less by Thinking More
Yue Jiang, Jiawei Chen, Dingkang Yang, Mingcheng Li, Shunli Wang, Tong Wu, Ke Li, Lihua Zhang
Automatic medical report generation (MRG), which possesses significant research value as it can aid radiologists in clinical diagnosis and report composition, has garnered increasing attention. Despite recent progress, generating accurate reports remains arduous due to the requirement for precise clinical comprehension and disease diagnosis inference. Furthermore, owing to the limited accessibility of medical data and the imbalanced distribution of diseases, the underrepresentation of rare diseases in training data makes large-scale medical visual language models (LVLMs) prone to hallucinations, such as omissions or fabrications, severely undermining diagnostic performance and further intensifying the challenges for MRG in practice. In this study, to effectively mitigate hallucinations in medical report generation, we propose a chain-of-medical-thought approach (CoMT), which intends to imitate the cognitive process of human doctors by decomposing diagnostic procedures. The radiological features with different importance are structured into fine-grained medical thought chains to enhance the inferential ability during diagnosis, thereby alleviating hallucination problems and enhancing the diagnostic accuracy of MRG. All resources of this work will be released soon.
Read more9/19/2024