Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models

0
📉
Sign in to get full access
Overview
- The paper introduces a robotics framework called Dream2Real that integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline.
- The robot autonomously constructs a 3D representation of the scene, where objects can be virtually rearranged and an image of the resulting arrangement rendered.
- These renders are evaluated by a VLM to select the arrangement that best satisfies the user instruction, which is then recreated in the real world through pick-and-place.
- This enables language-conditioned rearrangement to be performed zero-shot, without needing a training dataset of example arrangements.
Plain English Explanation
The paper describes a robotics system called Dream2Real that allows a robot to rearrange objects in a 3D environment based on language instructions. The key innovation is the integration of vision-language models (VLMs) trained on 2D data.
The robot first builds a 3D model of the scene, then it can virtually rearrange the objects and render an image of the new arrangement. This rendered image is evaluated by the VLM to determine how well it matches the language instruction. The robot then executes the best arrangement in the real world using pick-and-place operations.
This allows the robot to rearrange objects in complex ways without needing a large dataset of example arrangements for training. The robot can follow language instructions in a "zero-shot" manner, meaning it can handle new tasks without additional training.
Technical Explanation
The Dream2Real framework works as follows:
- The robot constructs a 3D representation of the scene using depth sensing and object detection.
- It can then virtually rearrange the objects in this 3D model and render an image of the new arrangement.
- This rendered image is evaluated by a vision-language model (VLM) that has been trained on 2D image-text pairs.
- The VLM scores the arrangement based on how well it matches the user's language instruction, and the robot selects the highest-scoring arrangement.
- Finally, the robot executes the selected arrangement in the real world using pick-and-place operations.
The key advantage of this approach is that it enables language-conditioned rearrangement to be performed in a zero-shot manner, without needing to collect a dataset of example arrangements. The robot can handle new tasks just by following natural language instructions.
Critical Analysis
The paper demonstrates that the Dream2Real framework is robust to distractors, controllable by language, and capable of understanding complex multi-object relations. However, the authors acknowledge that it is currently limited to tabletop and 6-DoF rearrangement tasks.
Additionally, the performance of the system is highly dependent on the capabilities of the underlying vision-language model (VLM). Further research could explore ways to integrate VLMs more tightly with the robotics pipeline or develop specialized VLMs for robotic tasks.
Conclusion
The Dream2Real framework represents an exciting step towards language-driven robotic manipulation that can be applied to a wide range of tasks without extensive training. By leveraging vision-language models, this system enables robots to understand and execute complex instructions in a zero-shot manner, paving the way for more natural and intuitive human-robot interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📉
0
Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Ivan Kapelyukh, Yifei Ren, Ignacio Alzugaray, Edward Johns
We introduce Dream2Real, a robotics framework which integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline. This is achieved by the robot autonomously constructing a 3D representation of the scene, where objects can be rearranged virtually and an image of the resulting arrangement rendered. These renders are evaluated by a VLM, so that the arrangement which best satisfies the user instruction is selected and recreated in the real world with pick-and-place. This enables language-conditioned rearrangement to be performed zero-shot, without needing to collect a training dataset of example arrangements. Results on a series of real-world tasks show that this framework is robust to distractors, controllable by language, capable of understanding complex multi-object relations, and readily applicable to both tabletop and 6-DoF rearrangement tasks.
Read more7/31/2024
0
From Words to Poses: Enhancing Novel Object Pose Estimation with Vision Language Models
Tessa Pulli, Stefan Thalhammer, Simon Schwaiger, Markus Vincze
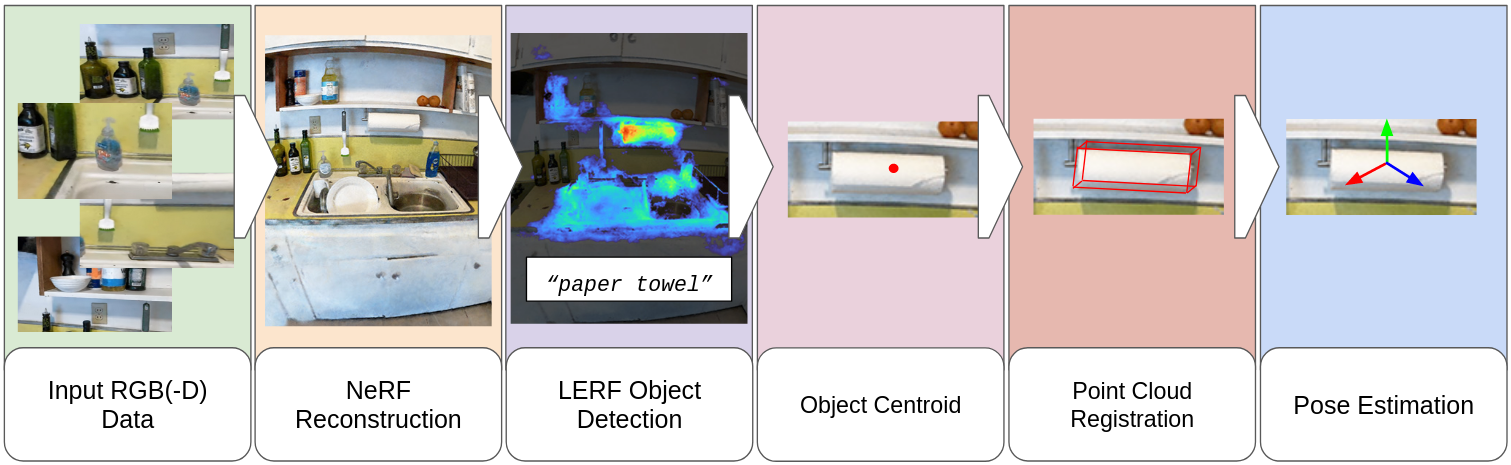
Robots are increasingly envisioned to interact in real-world scenarios, where they must continuously adapt to new situations. To detect and grasp novel objects, zero-shot pose estimators determine poses without prior knowledge. Recently, vision language models (VLMs) have shown considerable advances in robotics applications by establishing an understanding between language input and image input. In our work, we take advantage of VLMs zero-shot capabilities and translate this ability to 6D object pose estimation. We propose a novel framework for promptable zero-shot 6D object pose estimation using language embeddings. The idea is to derive a coarse location of an object based on the relevancy map of a language-embedded NeRF reconstruction and to compute the pose estimate with a point cloud registration method. Additionally, we provide an analysis of LERF's suitability for open-set object pose estimation. We examine hyperparameters, such as activation thresholds for relevancy maps and investigate the zero-shot capabilities on an instance- and category-level. Furthermore, we plan to conduct robotic grasping experiments in a real-world setting.
Read more9/10/2024

0
Solving Robotics Problems in Zero-Shot with Vision-Language Models
Zidan Wang, Rui Shen, Bradly Stadie
We introduce Wonderful Team, a multi-agent visual LLM (VLLM) framework for solving robotics problems in the zero-shot regime. By zero-shot we mean that, for a novel environment, we feed a VLLM an image of the robot's environment and a description of the task, and have the VLLM output the sequence of actions necessary for the robot to complete the task. Prior work on VLLMs in robotics has largely focused on settings where some part of the pipeline is fine-tuned, such as tuning an LLM on robot data or training a separate vision encoder for perception and action generation. Surprisingly, due to recent advances in the capabilities of VLLMs, this type of fine-tuning may no longer be necessary for many tasks. In this work, we show that with careful engineering, we can prompt a single off-the-shelf VLLM to handle all aspects of a robotics task, from high-level planning to low-level location-extraction and action-execution. Wonderful Team builds on recent advances in multi-agent LLMs to partition tasks across an agent hierarchy, making it self-corrective and able to effectively partition and solve even long-horizon tasks. Extensive experiments on VIMABench and real-world robotic environments demonstrate the system's capability to handle a variety of robotic tasks, including manipulation, visual goal-reaching, and visual reasoning, all in a zero-shot manner. These results underscore a key point: vision-language models have progressed rapidly in the past year, and should strongly be considered as a backbone for robotics problems going forward.
Read more8/26/2024

0
HumanVLA: Towards Vision-Language Directed Object Rearrangement by Physical Humanoid
Xinyu Xu, Yizheng Zhang, Yong-Lu Li, Lei Han, Cewu Lu
Physical Human-Scene Interaction (HSI) plays a crucial role in numerous applications. However, existing HSI techniques are limited to specific object dynamics and privileged information, which prevents the development of more comprehensive applications. To address this limitation, we introduce HumanVLA for general object rearrangement directed by practical vision and language. A teacher-student framework is utilized to develop HumanVLA. A state-based teacher policy is trained first using goal-conditioned reinforcement learning and adversarial motion prior. Then, it is distilled into a vision-language-action model via behavior cloning. We propose several key insights to facilitate the large-scale learning process. To support general object rearrangement by physical humanoid, we introduce a novel Human-in-the-Room dataset encompassing various rearrangement tasks. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed approach.
Read more7/1/2024