HumanVLA: Towards Vision-Language Directed Object Rearrangement by Physical Humanoid

0

Sign in to get full access
Overview
• This paper presents HumanVLA, a system for enabling a physical humanoid robot to rearrange objects in a room based on vision-language instructions. • The system combines computer vision, language understanding, and robotic manipulation capabilities to allow the robot to interpret natural language commands and execute the corresponding physical actions. • The key innovations of HumanVLA include a vision-language action model, a human-aware navigation module, and an open-source implementation.
Plain English Explanation
The paper describes a system that allows a humanoid robot to rearrange objects in a room based on simple spoken or written commands. For example, the robot could be told "Move the blue box to the table" and it would use its cameras to locate the blue box, plan a path to the table, and physically pick up and place the box in the desired location.
This is a challenging task that requires the robot to have advanced capabilities in understanding natural language, perceiving its surroundings, and precisely controlling its movements. The researchers have developed new machine learning models and algorithms to enable this vision-language-action (VLA) system, which they call HumanVLA.
Some key innovations in HumanVLA include:
- A VLA model that can translate natural language instructions into a sequence of robotic actions
- A human-aware navigation module that allows the robot to safely navigate around people in the environment
- An open-source implementation that can be used by other researchers to build on this work
The overall goal is to create robots that can seamlessly interact with and assist humans in everyday tasks and environments, bridging the gap between the physical and digital worlds.
Technical Explanation
The core of HumanVLA is a vision-language-action (VLA) model that can translate natural language instructions into a sequence of robotic actions. This VLA model takes in visual observations of the environment and language commands, and outputs a plan for how the robot should manipulate objects to fulfill the instructions.
To enable the robot to navigate safely around humans in the environment, the researchers developed a human-aware navigation module. This module uses computer vision to detect and track people in the scene, and then plans collision-free paths for the robot to execute its actions.
The researchers also provide an open-source implementation of HumanVLA, allowing other researchers to build on their work and advance the state-of-the-art in vision-language-action systems.
Critical Analysis
The HumanVLA system represents an important step towards endowing robots with the ability to fluidly interact with and assist humans in real-world environments. However, the paper does acknowledge some limitations and areas for further research.
For example, the system currently only supports a limited set of object manipulation tasks, and its performance may degrade in more complex or cluttered environments. Additionally, the human-awareness component, while innovative, may not fully capture the nuances of human behavior and social norms.
Further research could explore expanding the scope of the VLA model to handle a wider range of tasks, as well as incorporating more sophisticated models of human-robot interaction. Ultimately, the success of systems like HumanVLA will depend on their ability to robustly operate in real-world settings and seamlessly collaborate with human users.
Conclusion
The HumanVLA system represents an important step towards enabling physical robots to understand and act upon vision-language instructions, with the goal of creating robots that can assist humans in everyday tasks and environments. The key innovations include a robust VLA model, a human-aware navigation module, and an open-source implementation that can be built upon by other researchers.
While the current system has some limitations, the work lays the groundwork for future advancements in vision-language-action systems that could dramatically improve the ability of robots to interact with and support humans in the real world. As this technology continues to evolve, it has the potential to transform how we live and work, bridging the gap between the digital and physical domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HumanVLA: Towards Vision-Language Directed Object Rearrangement by Physical Humanoid
Xinyu Xu, Yizheng Zhang, Yong-Lu Li, Lei Han, Cewu Lu
Physical Human-Scene Interaction (HSI) plays a crucial role in numerous applications. However, existing HSI techniques are limited to specific object dynamics and privileged information, which prevents the development of more comprehensive applications. To address this limitation, we introduce HumanVLA for general object rearrangement directed by practical vision and language. A teacher-student framework is utilized to develop HumanVLA. A state-based teacher policy is trained first using goal-conditioned reinforcement learning and adversarial motion prior. Then, it is distilled into a vision-language-action model via behavior cloning. We propose several key insights to facilitate the large-scale learning process. To support general object rearrangement by physical humanoid, we introduce a novel Human-in-the-Room dataset encompassing various rearrangement tasks. Through extensive experiments and analysis, we demonstrate the effectiveness of the proposed approach.
Read more7/1/2024
0
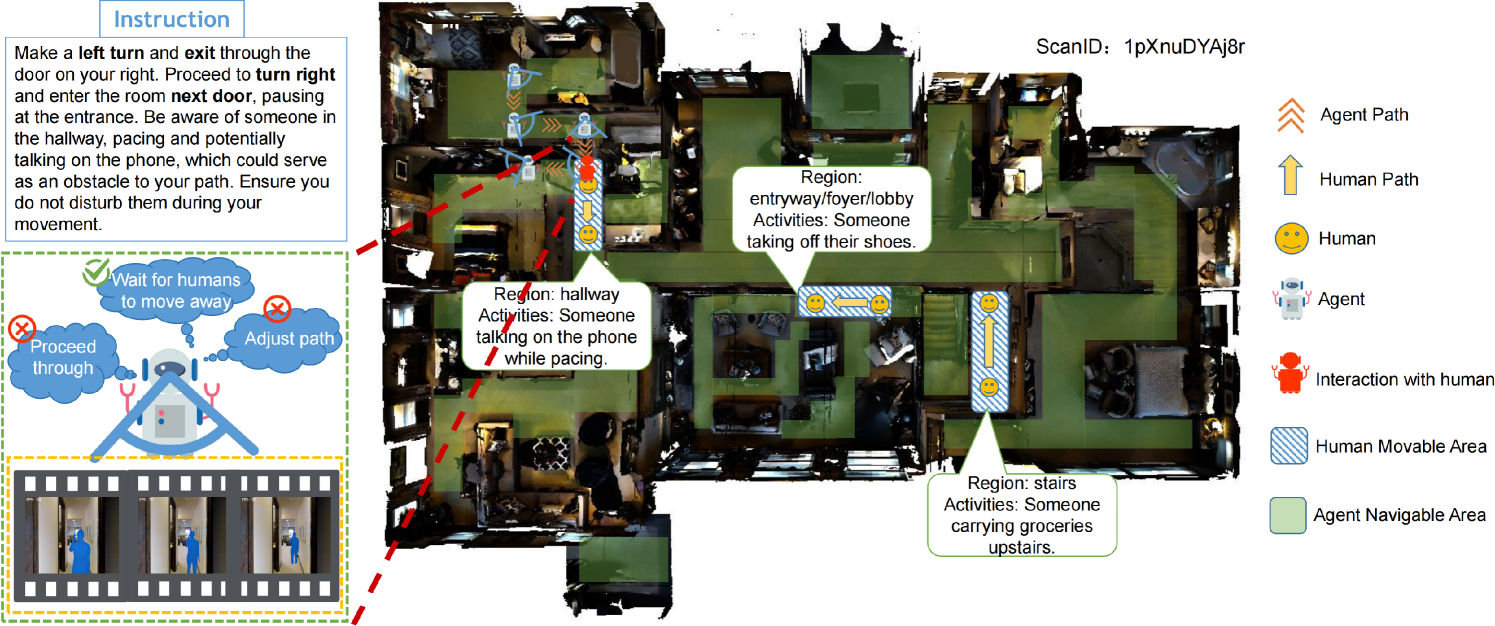
Human-Aware Vision-and-Language Navigation: Bridging Simulation to Reality with Dynamic Human Interactions
Minghan Li, Heng Li, Zhi-Qi Cheng, Yifei Dong, Yuxuan Zhou, Jun-Yan He, Qi Dai, Teruko Mitamura, Alexander G. Hauptmann
Vision-and-Language Navigation (VLN) aims to develop embodied agents that navigate based on human instructions. However, current VLN frameworks often rely on static environments and optimal expert supervision, limiting their real-world applicability. To address this, we introduce Human-Aware Vision-and-Language Navigation (HA-VLN), extending traditional VLN by incorporating dynamic human activities and relaxing key assumptions. We propose the Human-Aware 3D (HA3D) simulator, which combines dynamic human activities with the Matterport3D dataset, and the Human-Aware Room-to-Room (HA-R2R) dataset, extending R2R with human activity descriptions. To tackle HA-VLN challenges, we present the Expert-Supervised Cross-Modal (VLN-CM) and Non-Expert-Supervised Decision Transformer (VLN-DT) agents, utilizing cross-modal fusion and diverse training strategies for effective navigation in dynamic human environments. A comprehensive evaluation, including metrics considering human activities, and systematic analysis of HA-VLN's unique challenges, underscores the need for further research to enhance HA-VLN agents' real-world robustness and adaptability. Ultimately, this work provides benchmarks and insights for future research on embodied AI and Sim2Real transfer, paving the way for more realistic and applicable VLN systems in human-populated environments.
Read more7/8/2024
📉
0
Dream2Real: Zero-Shot 3D Object Rearrangement with Vision-Language Models
Ivan Kapelyukh, Yifei Ren, Ignacio Alzugaray, Edward Johns
We introduce Dream2Real, a robotics framework which integrates vision-language models (VLMs) trained on 2D data into a 3D object rearrangement pipeline. This is achieved by the robot autonomously constructing a 3D representation of the scene, where objects can be rearranged virtually and an image of the resulting arrangement rendered. These renders are evaluated by a VLM, so that the arrangement which best satisfies the user instruction is selected and recreated in the real world with pick-and-place. This enables language-conditioned rearrangement to be performed zero-shot, without needing to collect a training dataset of example arrangements. Results on a series of real-world tasks show that this framework is robust to distractors, controllable by language, capable of understanding complex multi-object relations, and readily applicable to both tabletop and 6-DoF rearrangement tasks.
Read more7/31/2024
0
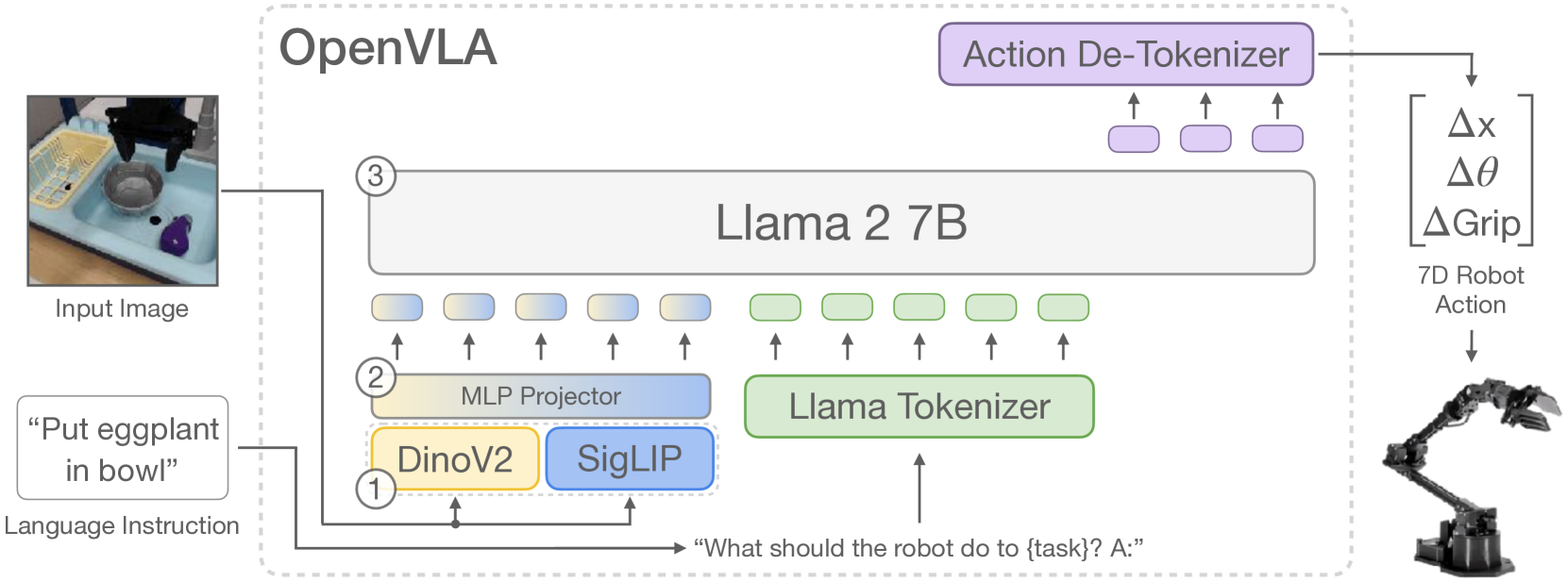
OpenVLA: An Open-Source Vision-Language-Action Model
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, Quan Vuong, Thomas Kollar, Benjamin Burchfiel, Russ Tedrake, Dorsa Sadigh, Sergey Levine, Percy Liang, Chelsea Finn
Large policies pretrained on a combination of Internet-scale vision-language data and diverse robot demonstrations have the potential to change how we teach robots new skills: rather than training new behaviors from scratch, we can fine-tune such vision-language-action (VLA) models to obtain robust, generalizable policies for visuomotor control. Yet, widespread adoption of VLAs for robotics has been challenging as 1) existing VLAs are largely closed and inaccessible to the public, and 2) prior work fails to explore methods for efficiently fine-tuning VLAs for new tasks, a key component for adoption. Addressing these challenges, we introduce OpenVLA, a 7B-parameter open-source VLA trained on a diverse collection of 970k real-world robot demonstrations. OpenVLA builds on a Llama 2 language model combined with a visual encoder that fuses pretrained features from DINOv2 and SigLIP. As a product of the added data diversity and new model components, OpenVLA demonstrates strong results for generalist manipulation, outperforming closed models such as RT-2-X (55B) by 16.5% in absolute task success rate across 29 tasks and multiple robot embodiments, with 7x fewer parameters. We further show that we can effectively fine-tune OpenVLA for new settings, with especially strong generalization results in multi-task environments involving multiple objects and strong language grounding abilities, and outperform expressive from-scratch imitation learning methods such as Diffusion Policy by 20.4%. We also explore compute efficiency; as a separate contribution, we show that OpenVLA can be fine-tuned on consumer GPUs via modern low-rank adaptation methods and served efficiently via quantization without a hit to downstream success rate. Finally, we release model checkpoints, fine-tuning notebooks, and our PyTorch codebase with built-in support for training VLAs at scale on Open X-Embodiment datasets.
Read more9/9/2024