Dual-Adapter: Training-free Dual Adaptation for Few-shot Out-of-Distribution Detection
2405.16146
0
0

Abstract
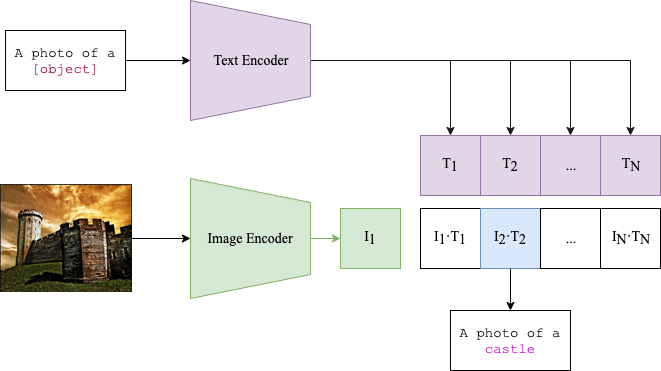
We study the problem of few-shot out-of-distribution (OOD) detection, which aims to detect OOD samples from unseen categories during inference time with only a few labeled in-domain (ID) samples. Existing methods mainly focus on training task-aware prompts for OOD detection. However, training on few-shot data may cause severe overfitting and textual prompts alone may not be enough for effective detection. To tackle these problems, we propose a prior-based Training-free Dual Adaptation method (Dual-Adapter) to detect OOD samples from both textual and visual perspectives. Specifically, Dual-Adapter first extracts the most significant channels as positive features and designates the remaining less relevant channels as negative features. Then, it constructs both a positive adapter and a negative adapter from a dual perspective, thereby better leveraging previously outlooked or interfering features in the training dataset. In this way, Dual-Adapter can inherit the advantages of CLIP not having to train, but also excels in distinguishing between ID and OOD samples. Extensive experimental results on four benchmark datasets demonstrate the superiority of Dual-Adapter.
Create account to get full access
Overview
- The paper presents a novel approach called Dual-Adapter for few-shot out-of-distribution (OOD) detection.
- Dual-Adapter is a training-free technique that can adapt a pre-trained model to perform OOD detection without requiring additional training data or fine-tuning.
- The method leverages two complementary feature adapters to capture both in-distribution and out-of-distribution characteristics, enabling effective OOD detection.
Plain English Explanation
Dual-Adapter is a technique that helps machine learning models identify data that is different from the type of data they were trained on. This is important because in the real world, models often encounter situations where the input data is very different from the data they were trained on, and they need to be able to recognize when this happens.
The key idea behind Dual-Adapter is to use two separate "feature adapters" that work together to capture both the characteristics of the data the model was trained on (the "in-distribution" data) and the characteristics of data that is different from the training data (the "out-of-distribution" data). By using these two complementary adapters, the model can more effectively detect when it's being presented with data that is very different from what it was designed to handle.
Importantly, Dual-Adapter is a "training-free" approach, which means that the model doesn't need to go through a lengthy fine-tuning or retraining process to be able to detect out-of-distribution data. This makes it a practical and efficient solution for real-world applications where the model may need to adapt to new types of data over time.
Technical Explanation
The Dual-Adapter approach consists of two key components: a Base Adapter and a Novelty Adapter. The Base Adapter is designed to capture the characteristics of the in-distribution data that the model was originally trained on, while the Novelty Adapter is responsible for identifying the features that are unique to the out-of-distribution data.
These two adapters are then combined in a way that allows the model to simultaneously consider both the in-distribution and out-of-distribution characteristics of the input data. This dual-adaptation mechanism enables the model to make more accurate decisions about whether a given input is part of the original distribution or something new and different.
Importantly, the Dual-Adapter approach is "training-free," meaning that it can be applied to a pre-trained model without requiring any additional fine-tuning or retraining. This is a significant advantage over other OOD detection methods that often require substantial amounts of labeled data and computational resources to adapt to new scenarios.
The paper evaluates the Dual-Adapter approach on a range of OOD detection benchmarks, including Enhancing Near-OOD Detection with Prompt Learning and Maximum Entropy, MultiOOD: Scaling Out-of-Distribution Detection to Multiple Modalities, and Toward a Realistic Benchmark for Out-of-Distribution Detection. The results demonstrate that Dual-Adapter outperforms traditional OOD detection methods, particularly in few-shot settings where only a small amount of out-of-distribution data is available for adaptation.
Critical Analysis
The Dual-Adapter approach presents a promising solution for OOD detection, but it's important to consider some potential limitations and areas for further research:
-
Generalization to Diverse OOD Scenarios: While the paper shows strong performance on the evaluated benchmarks, it's unclear how well Dual-Adapter would generalize to a wider range of OOD scenarios, including those with more complex or adversarial out-of-distribution data.
-
Interpretability and Explainability: The paper does not provide much insight into how the two adapters work together to make OOD detection decisions. Improving the interpretability of the Dual-Adapter approach could help users better understand its inner workings and build trust in its decisions.
-
Computational Efficiency: Although Dual-Adapter is a training-free technique, the addition of the two adapters may introduce some computational overhead compared to simpler OOD detection methods. The impact on model inference speed and resource usage should be further investigated.
-
Deployment Considerations: The paper does not address how the Dual-Adapter approach could be integrated into real-world systems and workflows. Addressing deployment-related challenges, such as model versioning, monitoring, and updating, would be an important next step.
Conclusion
The Dual-Adapter approach presented in this paper offers a promising solution for few-shot out-of-distribution detection. By leveraging two complementary feature adapters, the model can effectively capture both in-distribution and out-of-distribution characteristics, enabling accurate OOD detection without the need for additional training.
The training-free nature of Dual-Adapter makes it a practical and efficient option for real-world applications, where models may need to adapt to new data sources over time. Further research is needed to explore the method's generalization capabilities, interpretability, and computational efficiency, as well as its integration into production systems. Nonetheless, the Dual-Adapter approach represents an important step forward in the field of out-of-distribution detection.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploiting Diffusion Prior for Out-of-Distribution Detection
Armando Zhu, Jiabei Liu, Keqin Li, Shuying Dai, Bo Hong, Peng Zhao, Changsong Wei
0
0
Out-of-distribution (OOD) detection is crucial for deploying robust machine learning models, especially in areas where security is critical. However, traditional OOD detection methods often fail to capture complex data distributions from large scale date. In this paper, we present a novel approach for OOD detection that leverages the generative ability of diffusion models and the powerful feature extraction capabilities of CLIP. By using these features as conditional inputs to a diffusion model, we can reconstruct the images after encoding them with CLIP. The difference between the original and reconstructed images is used as a signal for OOD identification. The practicality and scalability of our method is increased by the fact that it does not require class-specific labeled ID data, as is the case with many other methods. Extensive experiments on several benchmark datasets demonstrates the robustness and effectiveness of our method, which have significantly improved the detection accuracy.
6/18/2024
🔎
MultiOOD: Scaling Out-of-Distribution Detection for Multiple Modalities
Hao Dong, Yue Zhao, Eleni Chatzi, Olga Fink
0
0
Detecting out-of-distribution (OOD) samples is important for deploying machine learning models in safety-critical applications such as autonomous driving and robot-assisted surgery. Existing research has mainly focused on unimodal scenarios on image data. However, real-world applications are inherently multimodal, which makes it essential to leverage information from multiple modalities to enhance the efficacy of OOD detection. To establish a foundation for more realistic Multimodal OOD Detection, we introduce the first-of-its-kind benchmark, MultiOOD, characterized by diverse dataset sizes and varying modality combinations. We first evaluate existing unimodal OOD detection algorithms on MultiOOD, observing that the mere inclusion of additional modalities yields substantial improvements. This underscores the importance of utilizing multiple modalities for OOD detection. Based on the observation of Modality Prediction Discrepancy between in-distribution (ID) and OOD data, and its strong correlation with OOD performance, we propose the Agree-to-Disagree (A2D) algorithm to encourage such discrepancy during training. Moreover, we introduce a novel outlier synthesis method, NP-Mix, which explores broader feature spaces by leveraging the information from nearest neighbor classes and complements A2D to strengthen OOD detection performance. Extensive experiments on MultiOOD demonstrate that training with A2D and NP-Mix improves existing OOD detection algorithms by a large margin. Our source code and MultiOOD benchmark are available at https://github.com/donghao51/MultiOOD.
5/28/2024

Enhancing Near OOD Detection in Prompt Learning: Maximum Gains, Minimal Costs
Myong Chol Jung, He Zhao, Joanna Dipnall, Belinda Gabbe, Lan Du
0
0
Prompt learning has shown to be an efficient and effective fine-tuning method for vision-language models like CLIP. While numerous studies have focused on the generalisation of these models in few-shot classification, their capability in near out-of-distribution (OOD) detection has been overlooked. A few recent works have highlighted the promising performance of prompt learning in far OOD detection. However, the more challenging task of few-shot near OOD detection has not yet been addressed. In this study, we investigate the near OOD detection capabilities of prompt learning models and observe that commonly used OOD scores have limited performance in near OOD detection. To enhance the performance, we propose a fast and simple post-hoc method that complements existing logit-based scores, improving near OOD detection AUROC by up to 11.67% with minimal computational cost. Our method can be easily applied to any prompt learning model without change in architecture or re-training the models. Comprehensive empirical evaluations across 13 datasets and 8 models demonstrate the effectiveness and adaptability of our method.
5/28/2024

Continual Unsupervised Out-of-Distribution Detection
Lars Doorenbos, Raphael Sznitman, Pablo M'arquez-Neila
0
0
Deep learning models excel when the data distribution during training aligns with testing data. Yet, their performance diminishes when faced with out-of-distribution (OOD) samples, leading to great interest in the field of OOD detection. Current approaches typically assume that OOD samples originate from an unconcentrated distribution complementary to the training distribution. While this assumption is appropriate in the traditional unsupervised OOD (U-OOD) setting, it proves inadequate when considering the place of deployment of the underlying deep learning model. To better reflect this real-world scenario, we introduce the novel setting of continual U-OOD detection. To tackle this new setting, we propose a method that starts from a U-OOD detector, which is agnostic to the OOD distribution, and slowly updates during deployment to account for the actual OOD distribution. Our method uses a new U-OOD scoring function that combines the Mahalanobis distance with a nearest-neighbor approach. Furthermore, we design a confidence-scaled few-shot OOD detector that outperforms previous methods. We show our method greatly improves upon strong baselines from related fields.
6/5/2024