Dual-Branch Knowledge Distillation for Noise-Robust Synthetic Speech Detection

0
🗣️
Sign in to get full access
Overview
- Focuses on improving noise robustness in synthetic speech detection (SSD) systems
- Proposes a dual-branch knowledge distillation approach called DKDSSD
- Aims to enhance performance in noisy environments while maintaining cross-dataset reliability
Plain English Explanation
Synthetic speech detection (SSD) is the task of identifying whether a given audio sample is produced by a human or a computer-generated voice. Most SSD research has focused on improving performance on clean, noise-free datasets. However, in real-world situations, there is often background noise that can significantly degrade the performance of SSD systems.
To address this issue, the researchers propose a method called DKDSSD, which uses a dual-branch architecture. One branch, the "clean teacher," is trained on high-quality, noise-free data, while the other branch, the "noisy student," is trained on data with added noise. The two branches interact and learn from each other through an interactive fusion module and a teacher-student paradigm.
The noisy student branch first applies speech enhancement to reduce the impact of strong noise, then combines the denoised features with the original noisy features to mitigate the effects of speech distortion. The teacher-student paradigm helps the noisy student branch learn to make decisions similar to the clean teacher branch, enabling the noisy speech to behave more like clean speech.
By using this dual-branch approach and the various techniques to bridge the gap between clean and noisy data, the researchers were able to improve the noise robustness of their SSD system while maintaining performance on cross-dataset experiments.
Technical Explanation
The DKDSSD method consists of two parallel data flows: a clean teacher branch and a noisy student branch. The clean teacher branch is trained on high-quality, noise-free data, while the noisy student branch is trained on data with added noise.
To reduce the impact of strong noise in the noisy student branch, the researchers first apply speech enhancement, which aims to denoise the input audio. The denoised features are then combined with the original noisy features through an interactive fusion module, which helps mitigate the effects of speech distortion and maintain consistency with the data distribution of the clean branch.
Additionally, the researchers employ a teacher-student paradigm to guide the training of the noisy student branch. This paradigm maps the student's decision space to the teacher's decision space, enabling the noisy speech to behave more similarly to the clean speech.
The researchers also use a joint training method to optimize both the clean teacher and noisy student branches simultaneously, aiming to achieve global optimality.
Experimental results on multiple datasets demonstrate that the proposed DKDSSD method performs effectively in noisy environments and maintains its performance in cross-dataset experiments.
Critical Analysis
The researchers have identified an important problem in synthetic speech detection, namely the significant performance degradation caused by noise interference in real-world situations. Their proposed DKDSSD method is a promising approach to address this challenge.
However, the paper does not provide a detailed analysis of the limitations or potential issues with the method. For example, it would be valuable to understand the computational and memory requirements of the dual-branch architecture, as well as the sensitivity of the method to different types and levels of noise.
Additionally, the researchers could have explored the generalizability of the DKDSSD method to other audio classification tasks beyond synthetic speech detection, as the core ideas of using a clean teacher branch and a noisy student branch with interactive fusion and a teacher-student paradigm may be applicable in a broader context.
Overall, the research presents a valuable contribution to the field of synthetic speech detection, but further investigation into the method's limitations and potential extensions could strengthen the work and provide a more comprehensive understanding of its capabilities and drawbacks.
Conclusion
The DKDSSD method proposed in this paper offers a novel approach to improving the noise robustness of synthetic speech detection systems. By leveraging a dual-branch architecture, speech enhancement, interactive fusion, and a teacher-student paradigm, the researchers were able to achieve effective performance in noisy environments while maintaining cross-dataset reliability.
This research highlights the importance of addressing real-world noise challenges in audio-based classification tasks and demonstrates the potential of using knowledge distillation techniques to bridge the gap between clean and noisy data. The insights gained from this work could inspire further research into robust and adaptable audio processing systems, with applications in speech recognition, audio surveillance, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
0
Dual-Branch Knowledge Distillation for Noise-Robust Synthetic Speech Detection
Cunhang Fan, Mingming Ding, Jianhua Tao, Ruibo Fu, Jiangyan Yi, Zhengqi Wen, Zhao Lv
Most research in synthetic speech detection (SSD) focuses on improving performance on standard noise-free datasets. However, in actual situations, noise interference is usually present, causing significant performance degradation in SSD systems. To improve noise robustness, this paper proposes a dual-branch knowledge distillation synthetic speech detection (DKDSSD) method. Specifically, a parallel data flow of the clean teacher branch and the noisy student branch is designed, and interactive fusion module and response-based teacher-student paradigms are proposed to guide the training of noisy data from both the data distribution and decision-making perspectives. In the noisy student branch, speech enhancement is introduced initially for denoising, aiming to reduce the interference of strong noise. The proposed interactive fusion combines denoised features and noisy features to mitigate the impact of speech distortion and ensure consistency with the data distribution of the clean branch. The teacher-student paradigm maps the student's decision space to the teacher's decision space, enabling noisy speech to behave similarly to clean speech. Additionally, a joint training method is employed to optimize both branches for achieving global optimality. Experimental results based on multiple datasets demonstrate that the proposed method performs effectively in noisy environments and maintains its performance in cross-dataset experiments. Source code is available at https://github.com/fchest/DKDSSD.
Read more4/17/2024
0
Leave No Knowledge Behind During Knowledge Distillation: Towards Practical and Effective Knowledge Distillation for Code-Switching ASR Using Realistic Data
Liang-Hsuan Tseng, Zih-Ching Chen, Wei-Shun Chang, Cheng-Kuang Lee, Tsung-Ren Huang, Hung-yi Lee
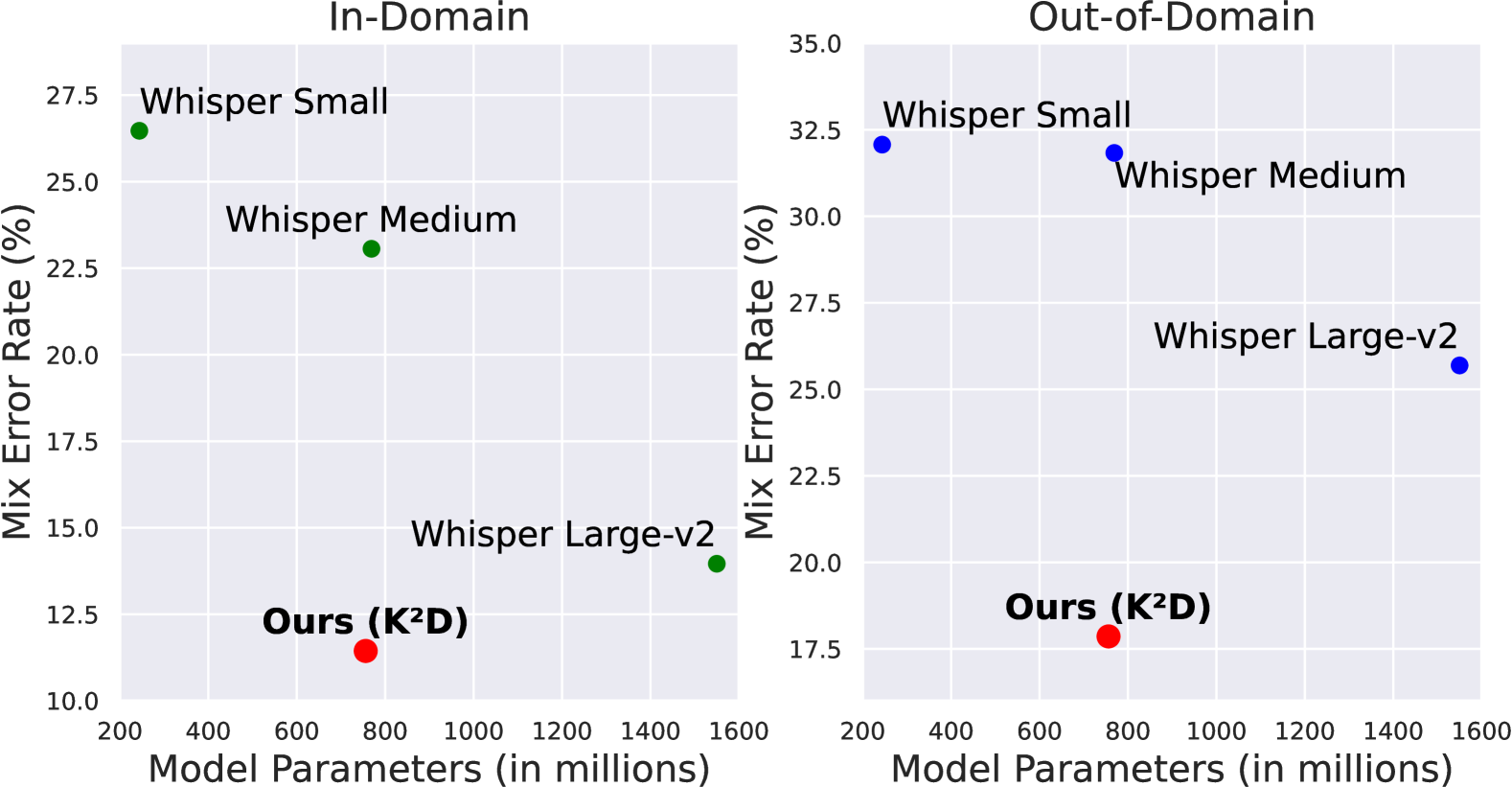
Recent advances in automatic speech recognition (ASR) often rely on large speech foundation models for generating high-quality transcriptions. However, these models can be impractical due to limited computing resources. The situation is even more severe in terms of more realistic or difficult scenarios, such as code-switching ASR (CS-ASR). To address this, we present a framework for developing more efficient models for CS-ASR through knowledge distillation using realistic speech-only data. Our proposed method, Leave No Knowledge Behind During Knowledge Distillation (K$^2$D), leverages both the teacher model's knowledge and additional insights from a small auxiliary model. We evaluate our approach on two in-domain and two out-domain datasets, demonstrating that K$^2$D is effective. By conducting K$^2$D on the unlabeled realistic data, we have successfully obtained a 2-time smaller model with 5-time faster generation speed while outperforming the baseline methods and the teacher model on all the testing sets. We have made our model publicly available on Hugging Face (https://huggingface.co/andybi7676/k2d-whisper.zh-en).
Read more7/16/2024

0
Robust Noisy Label Learning via Two-Stream Sample Distillation
Sihan Bai, Sanping Zhou, Zheng Qin, Le Wang, Nanning Zheng
Noisy label learning aims to learn robust networks under the supervision of noisy labels, which plays a critical role in deep learning. Existing work either conducts sample selection or label correction to deal with noisy labels during the model training process. In this paper, we design a simple yet effective sample selection framework, termed Two-Stream Sample Distillation (TSSD), for noisy label learning, which can extract more high-quality samples with clean labels to improve the robustness of network training. Firstly, a novel Parallel Sample Division (PSD) module is designed to generate a certain training set with sufficient reliable positive and negative samples by jointly considering the sample structure in feature space and the human prior in loss space. Secondly, a novel Meta Sample Purification (MSP) module is further designed to mine adequate semi-hard samples from the remaining uncertain training set by learning a strong meta classifier with extra golden data. As a result, more and more high-quality samples will be distilled from the noisy training set to train networks robustly in every iteration. Extensive experiments on four benchmark datasets, including CIFAR-10, CIFAR-100, Tiny-ImageNet, and Clothing-1M, show that our method has achieved state-of-the-art results over its competitors.
Read more4/17/2024

0
Frequency-mix Knowledge Distillation for Fake Speech Detection
Cunhang Fan, Shunbo Dong, Jun Xue, Yujie Chen, Jiangyan Yi, Zhao Lv
In the telephony scenarios, the fake speech detection (FSD) task to combat speech spoofing attacks is challenging. Data augmentation (DA) methods are considered effective means to address the FSD task in telephony scenarios, typically divided into time domain and frequency domain stages. While each has its advantages, both can result in information loss. To tackle this issue, we propose a novel DA method, Frequency-mix (Freqmix), and introduce the Freqmix knowledge distillation (FKD) to enhance model information extraction and generalization abilities. Specifically, we use Freqmix-enhanced data as input for the teacher model, while the student model's input undergoes time-domain DA method. We use a multi-level feature distillation approach to restore information and improve the model's generalization capabilities. Our approach achieves state-of-the-art results on ASVspoof 2021 LA dataset, showing a 31% improvement over baseline and performs competitively on ASVspoof 2021 DF dataset.
Read more6/17/2024