Leave No Knowledge Behind During Knowledge Distillation: Towards Practical and Effective Knowledge Distillation for Code-Switching ASR Using Realistic Data

0
Sign in to get full access
Overview
- The paper focuses on knowledge distillation, a technique to transfer knowledge from a larger, more complex model to a smaller, more efficient model.
- The authors explore knowledge distillation for code-switching automatic speech recognition (ASR) using realistic data, aiming to preserve important knowledge in the process.
- They propose techniques to ensure that no knowledge is left behind during the distillation process, making the smaller model as effective as the larger one.
Plain English Explanation
The paper is about a machine learning technique called knowledge distillation. This is a way to take a large, complex machine learning model and transfer its knowledge to a smaller, simpler model. The smaller model can then be used for tasks that require less computing power, like running on a mobile device.
The researchers in this paper focused on applying knowledge distillation to a specific type of speech recognition task called code-switching ASR. Code-switching is when people switch between two or more languages in the same conversation. The researchers wanted to find a way to distill the knowledge from a large, complex model that can handle code-switching to a smaller model, without losing any important information in the process.
They developed new techniques to ensure that the smaller model retains all the valuable knowledge from the larger model, making it just as effective for code-switching ASR. This could be useful for deploying high-quality speech recognition systems on devices with limited computing power, like smartphones.
Technical Explanation
The authors propose techniques to address the challenge of leaving no knowledge behind during knowledge distillation for code-switching ASR using realistic data. They build on prior work in knowledge distillation for speech recognition and the importance of preserving model robustness during distillation.
The key elements of their approach include:
-
Multilingual Embeddings: The authors use multilingual word embeddings to enable the smaller model to understand code-switching, even if it was not trained on code-switched data directly.
-
Knowledge Distillation with Regularization: They introduce additional regularization terms to the knowledge distillation objective to ensure the smaller model retains important knowledge from the larger model, such as frame-level alignments.
-
Curriculum Learning: The authors use a curriculum learning approach, starting with monolingual data and gradually increasing the difficulty to code-switched data, to help the smaller model learn effectively.
Through extensive experiments on realistic code-switching ASR datasets, the authors demonstrate that their techniques can produce a smaller model that is just as effective as the larger, more complex model, without leaving any important knowledge behind.
Critical Analysis
The paper presents a thorough and well-designed study on preserving knowledge during the knowledge distillation process for code-switching ASR. The authors acknowledge the limitations of their work, such as the need for further investigation into the generalization of their techniques to other language pairs and the potential for additional compression of the smaller model.
One area that could be explored further is the impact of the specific choice of multilingual word embeddings on the performance of the smaller model. The authors use a publicly available set of embeddings, but the suitability of these embeddings for the task at hand could be investigated in more depth.
Additionally, the authors focus on preserving frame-level alignments during distillation, but there may be other types of knowledge, such as higher-level linguistic or acoustic patterns, that are also important to retain. Exploring additional knowledge transfer mechanisms beyond just aligning frame-level outputs could be a fruitful area for future research.
Overall, the paper presents a significant contribution to the field of knowledge distillation for code-switching ASR, and the techniques developed could have broader applicability beyond the specific task addressed in this work.
Conclusion
This paper introduces novel techniques to ensure that no important knowledge is lost during the knowledge distillation process for code-switching automatic speech recognition (ASR) using realistic data. By leveraging multilingual word embeddings, regularized distillation objectives, and curriculum learning, the authors are able to produce a smaller model that is just as effective as the larger, more complex model.
The proposed methods could have important implications for deploying high-quality speech recognition systems on resource-constrained devices, such as smartphones, by allowing the use of a smaller and more efficient model without sacrificing performance. The authors' focus on preserving critical knowledge during distillation is a valuable contribution to the field of knowledge distillation, with potential applications beyond the specific task of code-switching ASR.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Leave No Knowledge Behind During Knowledge Distillation: Towards Practical and Effective Knowledge Distillation for Code-Switching ASR Using Realistic Data
Liang-Hsuan Tseng, Zih-Ching Chen, Wei-Shun Chang, Cheng-Kuang Lee, Tsung-Ren Huang, Hung-yi Lee
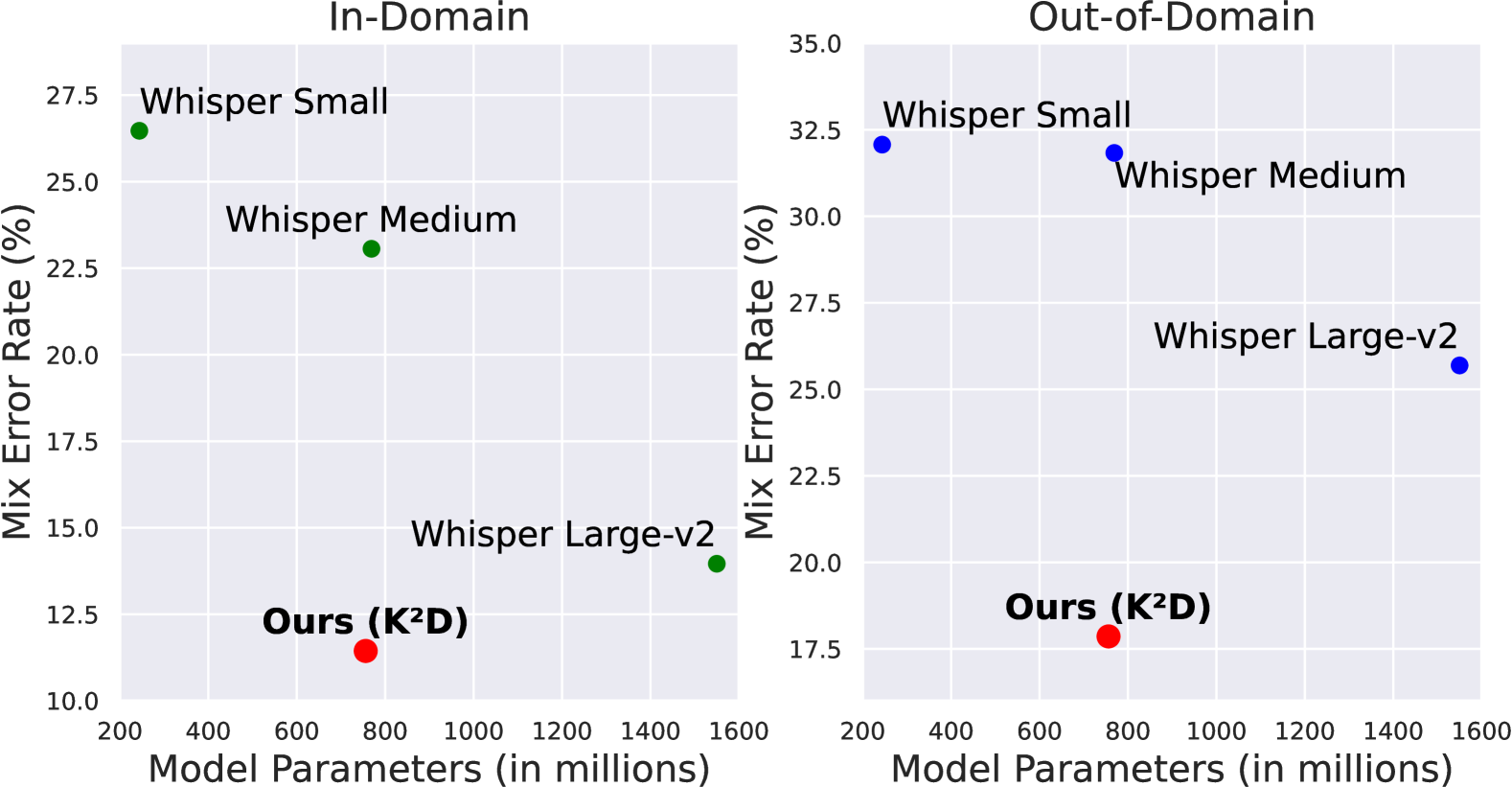
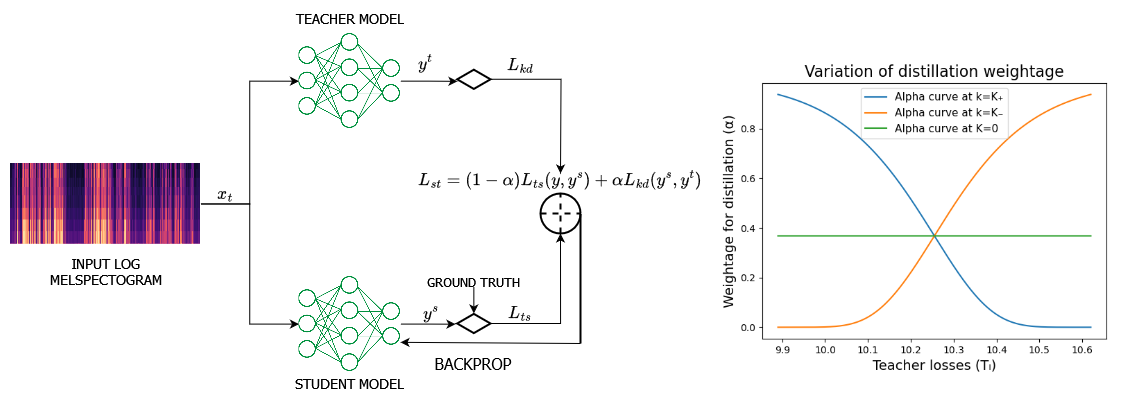
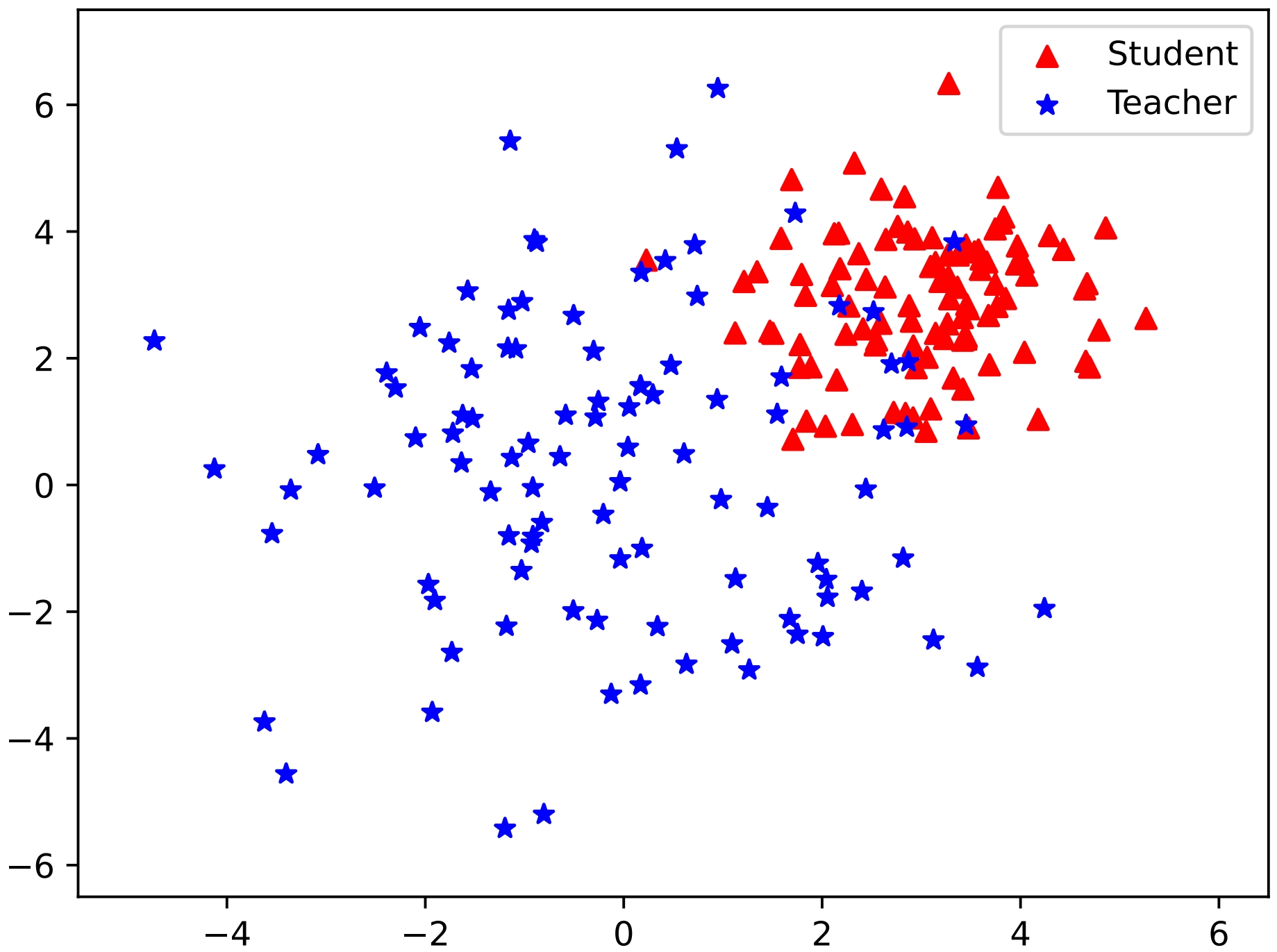
Recent advances in automatic speech recognition (ASR) often rely on large speech foundation models for generating high-quality transcriptions. However, these models can be impractical due to limited computing resources. The situation is even more severe in terms of more realistic or difficult scenarios, such as code-switching ASR (CS-ASR). To address this, we present a framework for developing more efficient models for CS-ASR through knowledge distillation using realistic speech-only data. Our proposed method, Leave No Knowledge Behind During Knowledge Distillation (K$^2$D), leverages both the teacher model's knowledge and additional insights from a small auxiliary model. We evaluate our approach on two in-domain and two out-domain datasets, demonstrating that K$^2$D is effective. By conducting K$^2$D on the unlabeled realistic data, we have successfully obtained a 2-time smaller model with 5-time faster generation speed while outperforming the baseline methods and the teacher model on all the testing sets. We have made our model publicly available on Hugging Face (https://huggingface.co/andybi7676/k2d-whisper.zh-en).
Read more7/16/2024
0
AdaKD: Dynamic Knowledge Distillation of ASR models using Adaptive Loss Weighting
Shreyan Ganguly, Roshan Nayak, Rakshith Rao, Ujan Deb, Prathosh AP
Knowledge distillation, a widely used model compression technique, works on the basis of transferring knowledge from a cumbersome teacher model to a lightweight student model. The technique involves jointly optimizing the task specific and knowledge distillation losses with a weight assigned to them. Despite these weights playing a crucial role in the performance of the distillation process, current methods provide equal weight to both losses, leading to suboptimal performance. In this paper, we propose Adaptive Knowledge Distillation, a novel technique inspired by curriculum learning to adaptively weigh the losses at instance level. This technique goes by the notion that sample difficulty increases with teacher loss. Our method follows a plug-and-play paradigm that can be applied on top of any task-specific and distillation objectives. Experiments show that our method performs better than conventional knowledge distillation method and existing instance-level loss functions.
Read more5/15/2024

0
BLSP-KD: Bootstrapping Language-Speech Pre-training via Knowledge Distillation
Chen Wang, Minpeng Liao, Zhongqiang Huang, Jiajun Zhang
Recent end-to-end approaches have shown promise in extending large language models (LLMs) to speech inputs, but face limitations in directly assessing and optimizing alignment quality and fail to achieve fine-grained alignment due to speech-text length mismatch. We introduce BLSP-KD, a novel approach for Bootstrapping Language-Speech Pretraining via Knowledge Distillation, which addresses these limitations through two key techniques. First, it optimizes speech-text alignment by minimizing the divergence between the LLM's next-token prediction distributions for speech and text inputs using knowledge distillation. Second, it employs a continuous-integrate-andfire strategy to segment speech into tokens that correspond one-to-one with text tokens, enabling fine-grained alignment. We also introduce Partial LoRA (PLoRA), a new adaptation method supporting LLM finetuning for speech inputs under knowledge distillation. Quantitative evaluation shows that BLSP-KD outperforms previous end-to-end baselines and cascaded systems with comparable scale of parameters, facilitating general instruction-following capabilities for LLMs with speech inputs. This approach provides new possibilities for extending LLMs to spoken language interactions.
Read more5/30/2024
0
Dual-Space Knowledge Distillation for Large Language Models
Songming Zhang, Xue Zhang, Zengkui Sun, Yufeng Chen, Jinan Xu
Knowledge distillation (KD) is known as a promising solution to compress large language models (LLMs) via transferring their knowledge to smaller models. During this process, white-box KD methods usually minimize the distance between the output distributions of the two models so that more knowledge can be transferred. However, in the current white-box KD framework, the output distributions are from the respective output spaces of the two models, using their own prediction heads. We argue that the space discrepancy will lead to low similarity between the teacher model and the student model on both representation and distribution levels. Furthermore, this discrepancy also hinders the KD process between models with different vocabularies, which is common for current LLMs. To address these issues, we propose a dual-space knowledge distillation (DSKD) framework that unifies the output spaces of the two models for KD. On the basis of DSKD, we further develop a cross-model attention mechanism, which can automatically align the representations of the two models with different vocabularies. Thus, our framework is not only compatible with various distance functions for KD (e.g., KL divergence) like the current framework, but also supports KD between any two LLMs regardless of their vocabularies. Experiments on task-agnostic instruction-following benchmarks show that DSKD significantly outperforms the current white-box KD framework with various distance functions, and also surpasses existing KD methods for LLMs with different vocabularies.
Read more10/2/2024