Dual-CBA: Improving Online Continual Learning via Dual Continual Bias Adaptors from a Bi-level Optimization Perspective

0

Sign in to get full access
Overview
- A paper that proposes a new method called Dual-CBA for improving online continual learning
- The method uses a bi-level optimization approach to adapt network biases for both task-recency and stability
- Experiments show Dual-CBA outperforms existing continual learning methods on various benchmark datasets
Plain English Explanation
The paper introduces a new technique called Dual-CBA for improving online continual learning. In continual learning, an AI system needs to learn new tasks sequentially without forgetting previously learned information.
Dual-CBA uses a bi-level optimization approach to address two key challenges in continual learning - task-recency bias (tendency to prioritize recent tasks) and stability gap (divergence between training and test performance).
The method introduces dual continual bias adaptors that adapt the network biases to better balance recent and past tasks. This allows the model to maintain high performance on new tasks while also preserving knowledge from earlier ones.
Experiments on benchmark datasets show that Dual-CBA outperforms existing continual learning techniques like learning to continually learn, reshaping online data buffering, and adaptive cascading network.
Technical Explanation
The key innovation in Dual-CBA is the use of dual continual bias adaptors that are optimized via bi-level optimization. The first adaptor handles task-recency bias by adjusting the network biases to prioritize recent tasks, while the second adaptor addresses stability gap by maintaining performance on past tasks.
The authors formulate the continual learning problem as a bi-level optimization problem, where the upper-level objective is to minimize the loss on the current task, and the lower-level objective is to maintain performance on previous tasks.
Dual-CBA introduces two sets of continual bias parameters that are optimized jointly with the model parameters. These bias parameters are updated after each task, allowing the network to dynamically adjust its biases to balance recent and past knowledge.
The authors conduct experiments on standard continual learning benchmarks like CIFAR-100, Split-MNIST, and Split-CUB-200-2011. The results demonstrate that Dual-CBA consistently outperforms existing methods in terms of both task-recency bias and stability gap.
Critical Analysis
The paper provides a novel and promising approach to addressing the key challenges in online continual learning. The bi-level optimization framework and dual continual bias adaptors are well-designed and theoretically grounded.
However, the paper does not discuss the potential computational overhead or training time implications of the bi-level optimization process. The method may be more computationally intensive than some simpler continual learning techniques.
Additionally, the paper could have provided more analysis on the learned bias parameters and how they evolve over time. This could offer valuable insights into the model's behavior and the trade-offs between task-recency and stability.
Further research could explore the applicability of Dual-CBA to more complex, real-world continual learning scenarios, as well as potential extensions or improvements to the core method.
Conclusion
The Dual-CBA method proposed in this paper represents a significant advancement in the field of online continual learning. By addressing both task-recency bias and stability gap through a bi-level optimization approach, the method demonstrates improved performance on standard benchmarks compared to existing techniques.
While the method may have some computational overhead, the underlying principles and innovations introduced in this work could inspire future research and lead to further breakthroughs in continual learning systems. As AI systems continue to be deployed in dynamic, real-world environments, advancements like Dual-CBA will be crucial for enabling them to learn and adapt effectively over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Dual-CBA: Improving Online Continual Learning via Dual Continual Bias Adaptors from a Bi-level Optimization Perspective
Quanziang Wang, Renzhen Wang, Yichen Wu, Xixi Jia, Minghao Zhou, Deyu Meng
In online continual learning (CL), models trained on changing distributions easily forget previously learned knowledge and bias toward newly received tasks. To address this issue, we present Continual Bias Adaptor (CBA), a bi-level framework that augments the classification network to adapt to catastrophic distribution shifts during training, enabling the network to achieve a stable consolidation of all seen tasks. However, the CBA module adjusts distribution shifts in a class-specific manner, exacerbating the stability gap issue and, to some extent, fails to meet the need for continual testing in online CL. To mitigate this challenge, we further propose a novel class-agnostic CBA module that separately aggregates the posterior probabilities of classes from new and old tasks, and applies a stable adjustment to the resulting posterior probabilities. We combine the two kinds of CBA modules into a unified Dual-CBA module, which thus is capable of adapting to catastrophic distribution shifts and simultaneously meets the real-time testing requirements of online CL. Besides, we propose Incremental Batch Normalization (IBN), a tailored BN module to re-estimate its population statistics for alleviating the feature bias arising from the inner loop optimization problem of our bi-level framework. To validate the effectiveness of the proposed method, we theoretically provide some insights into how it mitigates catastrophic distribution shifts, and empirically demonstrate its superiority through extensive experiments based on four rehearsal-based baselines and three public continual learning benchmarks.
Read more8/27/2024

0
Learning to Continually Learn with the Bayesian Principle
Soochan Lee, Hyeonseong Jeon, Jaehyeon Son, Gunhee Kim
In the present era of deep learning, continual learning research is mainly focused on mitigating forgetting when training a neural network with stochastic gradient descent on a non-stationary stream of data. On the other hand, in the more classical literature of statistical machine learning, many models have sequential Bayesian update rules that yield the same learning outcome as the batch training, i.e., they are completely immune to catastrophic forgetting. However, they are often overly simple to model complex real-world data. In this work, we adopt the meta-learning paradigm to combine the strong representational power of neural networks and simple statistical models' robustness to forgetting. In our novel meta-continual learning framework, continual learning takes place only in statistical models via ideal sequential Bayesian update rules, while neural networks are meta-learned to bridge the raw data and the statistical models. Since the neural networks remain fixed during continual learning, they are protected from catastrophic forgetting. This approach not only achieves significantly improved performance but also exhibits excellent scalability. Since our approach is domain-agnostic and model-agnostic, it can be applied to a wide range of problems and easily integrated with existing model architectures.
Read more5/30/2024
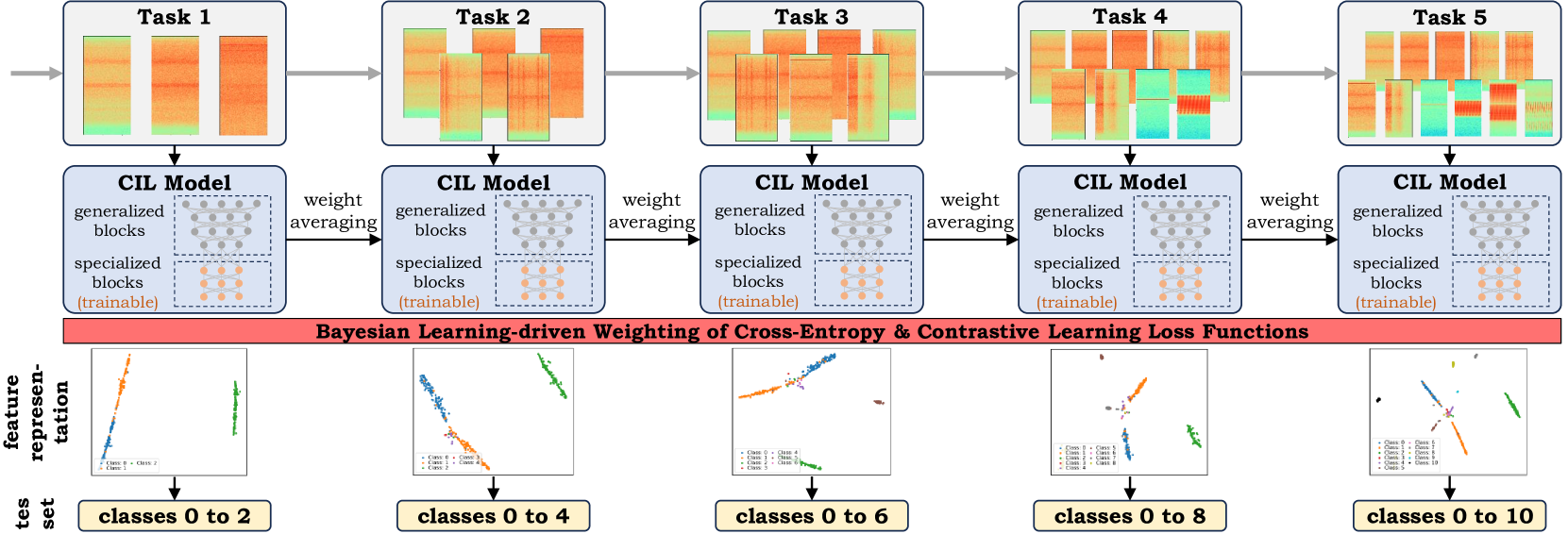
0
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 and CIFAR-100 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
Read more7/15/2024

0
Reshaping the Online Data Buffering and Organizing Mechanism for Continual Test-Time Adaptation
Zhilin Zhu, Xiaopeng Hong, Zhiheng Ma, Weijun Zhuang, Yaohui Ma, Yong Dai, Yaowei Wang
Continual Test-Time Adaptation (CTTA) involves adapting a pre-trained source model to continually changing unsupervised target domains. In this paper, we systematically analyze the challenges of this task: online environment, unsupervised nature, and the risks of error accumulation and catastrophic forgetting under continual domain shifts. To address these challenges, we reshape the online data buffering and organizing mechanism for CTTA. We propose an uncertainty-aware buffering approach to identify and aggregate significant samples with high certainty from the unsupervised, single-pass data stream. Based on this, we propose a graph-based class relation preservation constraint to overcome catastrophic forgetting. Furthermore, a pseudo-target replay objective is used to mitigate error accumulation. Extensive experiments demonstrate the superiority of our method in both segmentation and classification CTTA tasks. Code is available at https://github.com/z1358/OBAO.
Read more7/19/2024