Dual-Modal Prompting for Sketch-Based Image Retrieval

0
🖼️
Sign in to get full access
Ablation Experiments
The paper provides an appendix with additional details on the ablation experiments conducted as part of the research. Ablation experiments are a common technique used to assess the importance of different components or features in a model by systematically removing or modifying them and evaluating the impact on the model's performance.
Plain English Explanation
The researchers likely performed these ablation experiments to better understand which aspects of their approach were most crucial to its success. By selectively disabling or altering different parts of their system, they could determine which components were the most impactful and which ones were less critical. This type of analysis helps the researchers fine-tune their model and identify opportunities for further improvement. Ablation studies provide valuable insight into the inner workings of complex systems and can guide future iterations of the research.
Technical Explanation
The appendix likely includes details on the specific ablation experiments conducted, such as:
- Removing or modifying different input modalities (e.g., disabling the visual input, relying only on text, etc.) to assess the importance of multimodal learning
- Altering the architecture of the model, such as changing the size or depth of the neural networks, to understand the impact of model complexity
- Disabling or adjusting the various components of the prompt engineering process to evaluate their individual contributions
- Varying the amount of training data or the data augmentation techniques used to gauge the sensitivity to the quantity and quality of the training corpus
Through these types of targeted experiments, the researchers could systematically explore the design space and gain a deeper understanding of the critical factors driving the performance of their approach.
Critical Analysis
While the appendix provides valuable technical details, it would be helpful if the paper also included a more accessible summary of the key takeaways from the ablation experiments. The researchers could have highlighted the most impactful findings and discussed how those insights informed the final design of their system. Additionally, it would be interesting to see the researchers acknowledge any limitations or unexpected results that arose during the ablation process, as those could point to areas for future exploration.
Conclusion
The appendix on ablation experiments offers a deeper look into the technical aspects of the research, but a more concise and plain-language summary of the key findings could make the insights more accessible to a broader audience. By clearly communicating the most important takeaways from these targeted experiments, the researchers could better showcase the rigor and depth of their investigation, ultimately strengthening the overall impact of the work.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Dual-Modal Prompting for Sketch-Based Image Retrieval
Liying Gao, Bingliang Jiao, Peng Wang, Shizhou Zhang, Hanwang Zhang, Yanning Zhang
Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
Read more4/30/2024
0
Elevating All Zero-Shot Sketch-Based Image Retrieval Through Multimodal Prompt Learning
Mainak Singha, Ankit Jha, Divyam Gupta, Pranav Singla, Biplab Banerjee
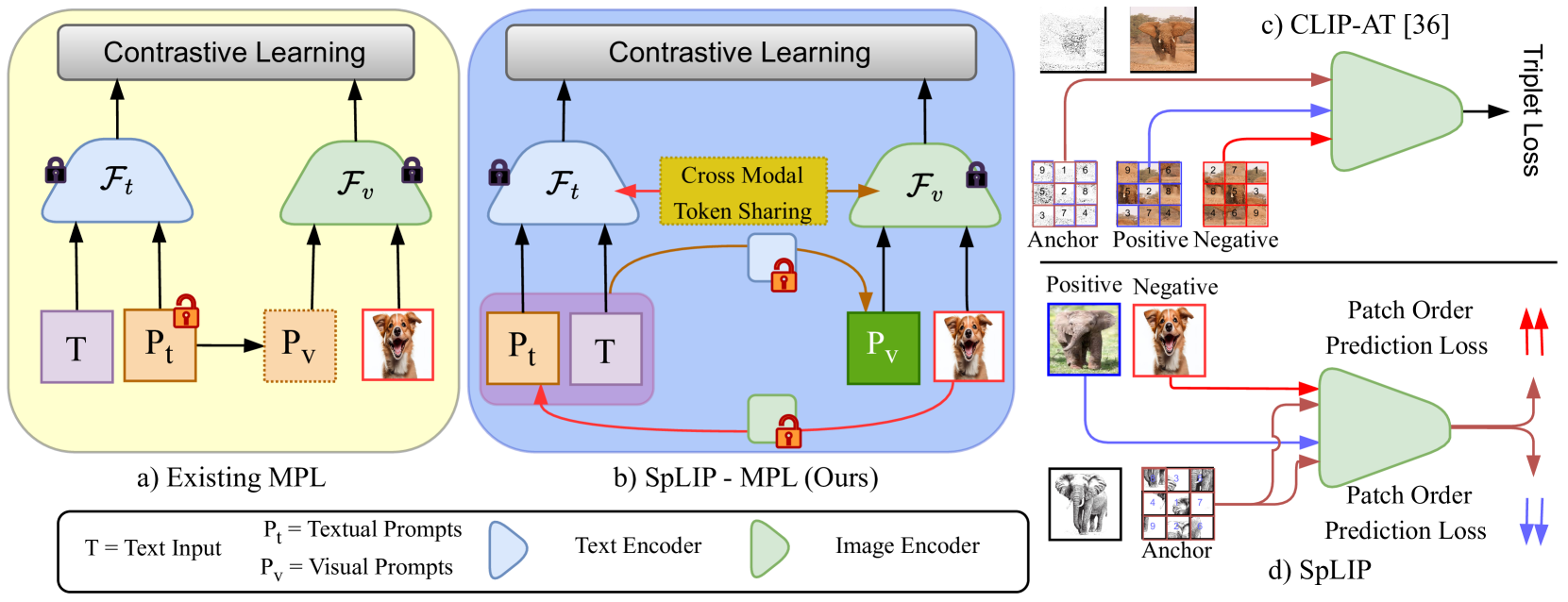
We address the challenges inherent in sketch-based image retrieval (SBIR) across various settings, including zero-shot SBIR, generalized zero-shot SBIR, and fine-grained zero-shot SBIR, by leveraging the vision-language foundation model CLIP. While recent endeavors have employed CLIP to enhance SBIR, these approaches predominantly follow uni-modal prompt processing and overlook to exploit CLIP's integrated visual and textual capabilities fully. To bridge this gap, we introduce SpLIP, a novel multi-modal prompt learning scheme designed to operate effectively with frozen CLIP backbones. We diverge from existing multi-modal prompting methods that treat visual and textual prompts independently or integrate them in a limited fashion, leading to suboptimal generalization. SpLIP implements a bi-directional prompt-sharing strategy that enables mutual knowledge exchange between CLIP's visual and textual encoders, fostering a more cohesive and synergistic prompt processing mechanism that significantly reduces the semantic gap between the sketch and photo embeddings. In addition to pioneering multi-modal prompt learning, we propose two innovative strategies for further refining the embedding space. The first is an adaptive margin generation for the sketch-photo triplet loss, regulated by CLIP's class textual embeddings. The second introduces a novel task, termed conditional cross-modal jigsaw, aimed at enhancing fine-grained sketch-photo alignment by implicitly modeling sketches' viable patch arrangement using knowledge of unshuffled photos. Our comprehensive experimental evaluations across multiple benchmarks demonstrate the superior performance of SpLIP in all three SBIR scenarios. Project page: https://mainaksingha01.github.io/SpLIP/ .
Read more7/24/2024

0
The Solution for Language-Enhanced Image New Category Discovery
Haonan Xu, Dian Chao, Xiangyu Wu, Zhonghua Wan, Yang Yang
Treating texts as images, combining prompts with textual labels for prompt tuning, and leveraging the alignment properties of CLIP have been successfully applied in zero-shot multi-label image recognition. Nonetheless, relying solely on textual labels to store visual information is insufficient for representing the diversity of visual objects. In this paper, we propose reversing the training process of CLIP and introducing the concept of Pseudo Visual Prompts. These prompts are initialized for each object category and pre-trained on large-scale, low-cost sentence data generated by large language models. This process mines the aligned visual information in CLIP and stores it in class-specific visual prompts. We then employ contrastive learning to transfer the stored visual information to the textual labels, enhancing their visual representation capacity. Additionally, we introduce a dual-adapter module that simultaneously leverages knowledge from the original CLIP and new learning knowledge derived from downstream datasets. Benefiting from the pseudo visual prompts, our method surpasses the state-of-the-art not only on clean annotated text data but also on pseudo text data generated by large language models.
Read more7/9/2024

0
Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval
Hanwen Su, Ge Song, Kai Huang, Jiyan Wang, Ming Yang
In this paper, we study the problem of zero-shot sketch-based image retrieval (ZS-SBIR). The prior methods tackle the problem in a two-modality setting with only category labels or even no textual information involved. However, the growing prevalence of Large-scale pre-trained Language Models (LLMs), which have demonstrated great knowledge learned from web-scale data, can provide us with an opportunity to conclude collective textual information. Our key innovation lies in the usage of text data as auxiliary information for images, thus leveraging the inherent zero-shot generalization ability that language offers. To this end, we propose an approach called Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval. The network consists of three components: (i) a Description Generation Module that generates textual descriptions for each training category by prompting an LLM with several interrogative sentences, (ii) a Feature Extraction Module that includes two ViTs for sketch and image data, a transformer for extracting tokens of sentences of each training category, finally (iii) a Cross-modal Alignment Module that exchanges the token features of both text-sketch and text-image using cross-attention mechanism, and align the tokens locally and globally. Extensive experiments on three benchmark datasets show our superior performances over the state-of-the-art ZS-SBIR methods.
Read more7/2/2024