Elevating All Zero-Shot Sketch-Based Image Retrieval Through Multimodal Prompt Learning

0
Sign in to get full access
Overview
- This paper proposes a novel approach to improve zero-shot sketch-based image retrieval performance by learning effective multimodal prompts.
- The key idea is to leverage both visual and textual information to generate prompts that can better align the sketch and image representations.
- The authors demonstrate significant improvements over state-of-the-art methods on multiple benchmark datasets.
Plain English Explanation
The paper addresses the challenge of zero-shot sketch-based image retrieval. This is a task where you have a sketch (a simple drawing) and you want to find the most similar image in a database, without having any example images for that specific sketch.
The authors found that the standard approach of just using the sketch alone to search the image database wasn't working very well. So they developed a new technique that combines the visual information from the sketch with some textual information, to create prompts that can better match the sketch to the most relevant images.
The key insight is that by using both the sketch and some related text, the system can learn to generate prompts that are much better at finding the right images. This leads to significant improvements in the accuracy of the image retrieval, compared to just using the sketch alone or other state-of-the-art methods.
Technical Explanation
The paper proposes a multimodal prompt learning approach to improve zero-shot sketch-based image retrieval. The core idea is to generate prompts that can effectively align the visual representations of sketches and images.
The authors first extract visual features from the sketches using a pre-trained sketch encoder. They also obtain text features from class labels or descriptions associated with the images. These visual and textual features are then used to train a prompt generator network, which learns to produce prompts that can better match the sketch and image representations.
During inference, the generated prompts are used to query a pre-trained CLIP model, which retrieves the most relevant images based on the similarity between the prompt and image features.
The authors evaluate their approach on multiple benchmark datasets for zero-shot sketch-based image retrieval, demonstrating substantial improvements over state-of-the-art methods.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear technical contribution in the form of the multimodal prompt learning approach. The authors have conducted extensive experiments to validate the effectiveness of their method.
However, the paper does not discuss potential limitations or caveats of the proposed technique. For example, it would be valuable to understand how the method performs on more complex or abstract sketches, or how sensitive it is to the quality and availability of the textual information used to generate the prompts.
Additionally, the authors could have explored the interpretability of the learned prompts, which could provide insights into the underlying mechanisms driving the improved retrieval performance.
Conclusion
This paper introduces a novel multimodal prompt learning approach to enhance zero-shot sketch-based image retrieval. By leveraging both visual and textual information, the method is able to generate effective prompts that significantly outperform state-of-the-art techniques on multiple benchmark datasets.
The proposed approach demonstrates the value of combining different modalities to improve the alignment between sketches and images, which has important implications for various applications, such as visual search, creative design, and human-computer interaction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Elevating All Zero-Shot Sketch-Based Image Retrieval Through Multimodal Prompt Learning
Mainak Singha, Ankit Jha, Divyam Gupta, Pranav Singla, Biplab Banerjee
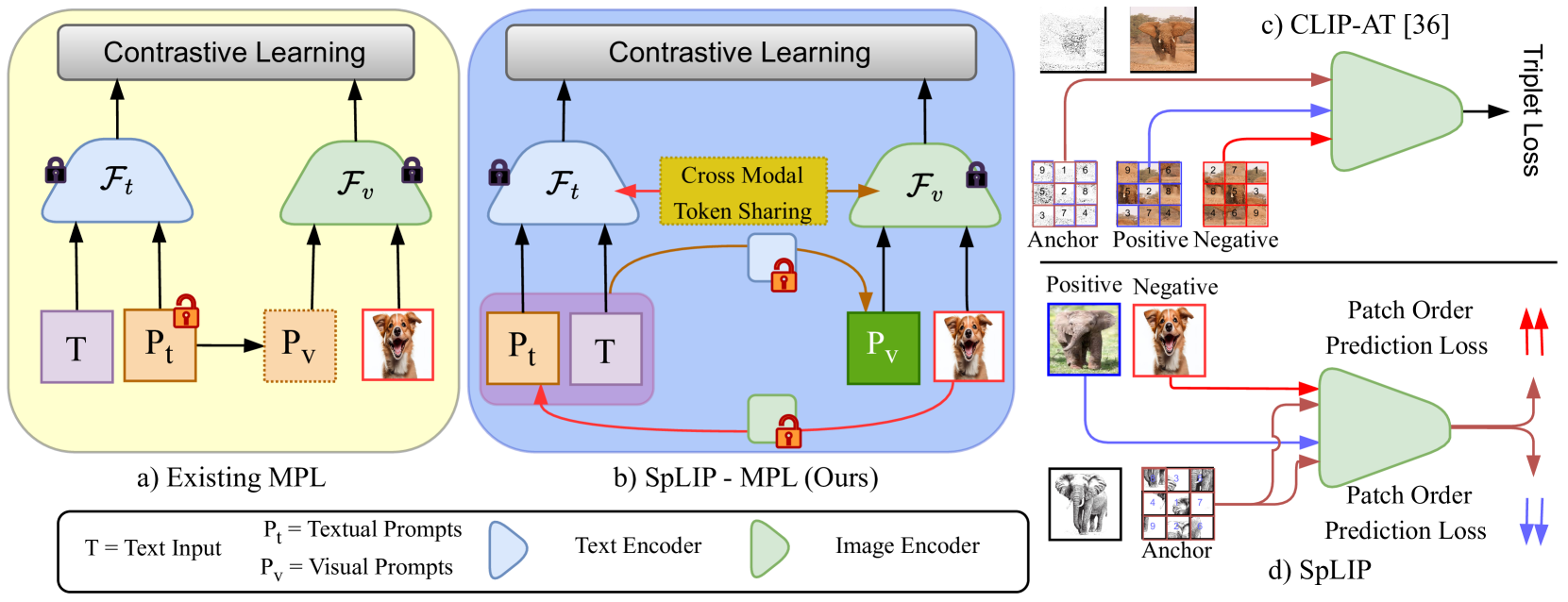
We address the challenges inherent in sketch-based image retrieval (SBIR) across various settings, including zero-shot SBIR, generalized zero-shot SBIR, and fine-grained zero-shot SBIR, by leveraging the vision-language foundation model CLIP. While recent endeavors have employed CLIP to enhance SBIR, these approaches predominantly follow uni-modal prompt processing and overlook to exploit CLIP's integrated visual and textual capabilities fully. To bridge this gap, we introduce SpLIP, a novel multi-modal prompt learning scheme designed to operate effectively with frozen CLIP backbones. We diverge from existing multi-modal prompting methods that treat visual and textual prompts independently or integrate them in a limited fashion, leading to suboptimal generalization. SpLIP implements a bi-directional prompt-sharing strategy that enables mutual knowledge exchange between CLIP's visual and textual encoders, fostering a more cohesive and synergistic prompt processing mechanism that significantly reduces the semantic gap between the sketch and photo embeddings. In addition to pioneering multi-modal prompt learning, we propose two innovative strategies for further refining the embedding space. The first is an adaptive margin generation for the sketch-photo triplet loss, regulated by CLIP's class textual embeddings. The second introduces a novel task, termed conditional cross-modal jigsaw, aimed at enhancing fine-grained sketch-photo alignment by implicitly modeling sketches' viable patch arrangement using knowledge of unshuffled photos. Our comprehensive experimental evaluations across multiple benchmarks demonstrate the superior performance of SpLIP in all three SBIR scenarios. Project page: https://mainaksingha01.github.io/SpLIP/ .
Read more7/24/2024
🖼️
0
Dual-Modal Prompting for Sketch-Based Image Retrieval
Liying Gao, Bingliang Jiao, Peng Wang, Shizhou Zhang, Hanwang Zhang, Yanning Zhang
Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
Read more4/30/2024
0
Towards Alleviating Text-to-Image Retrieval Hallucination for CLIP in Zero-shot Learning
Hanyao Wang, Yibing Zhan, Liu Liu, Liang Ding, Yan Yang, Jun Yu
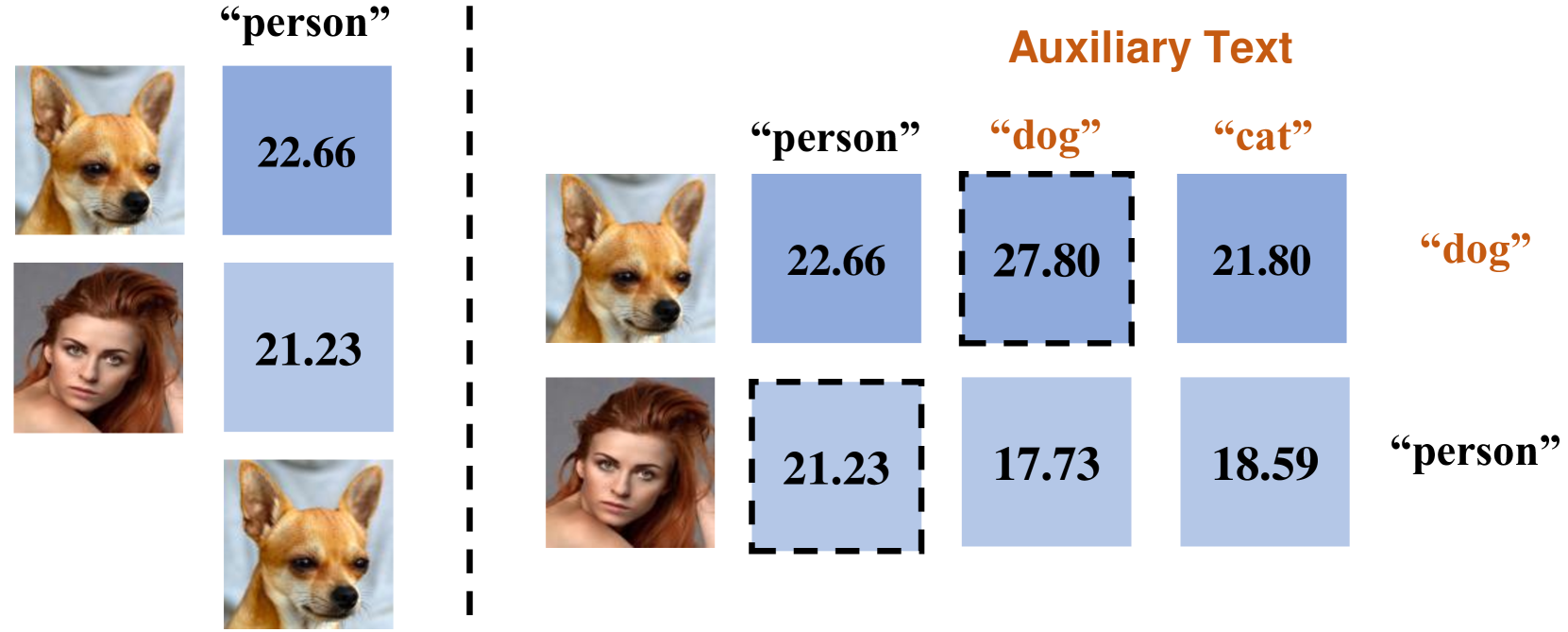
Pretrained cross-modal models, for instance, the most representative CLIP, have recently led to a boom in using pre-trained models for cross-modal zero-shot tasks, considering the generalization properties. However, we analytically discover that CLIP suffers from the text-to-image retrieval hallucination, adversely limiting its capabilities under zero-shot learning: CLIP would select the image with the highest score when asked to figure out which image perfectly matches one given query text among several candidate images even though CLIP knows contents in the image. Accordingly, we propose a Balanced Score with Auxiliary Prompts (BSAP) to mitigate the CLIP's text-to-image retrieval hallucination under zero-shot learning. Specifically, we first design auxiliary prompts to provide multiple reference outcomes for every single image retrieval, then the outcomes derived from each retrieved image in conjunction with the target text are normalized to obtain the final similarity, which alleviates hallucinations in the model. Additionally, we can merge CLIP's original results and BSAP to obtain a more robust hybrid outcome (BSAP-H). Extensive experiments on two typical zero-shot learning tasks, i.e., Referring Expression Comprehension (REC) and Referring Image Segmentation (RIS), are conducted to demonstrate the effectiveness of our BSAP. Specifically, when evaluated on the validation dataset of RefCOCO in REC, BSAP increases CLIP's performance by 20.6%. Further, we validate that our strategy could be applied in other types of pretrained cross-modal models, such as ALBEF and BLIP.
Read more6/28/2024

0
Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval
Hanwen Su, Ge Song, Kai Huang, Jiyan Wang, Ming Yang
In this paper, we study the problem of zero-shot sketch-based image retrieval (ZS-SBIR). The prior methods tackle the problem in a two-modality setting with only category labels or even no textual information involved. However, the growing prevalence of Large-scale pre-trained Language Models (LLMs), which have demonstrated great knowledge learned from web-scale data, can provide us with an opportunity to conclude collective textual information. Our key innovation lies in the usage of text data as auxiliary information for images, thus leveraging the inherent zero-shot generalization ability that language offers. To this end, we propose an approach called Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval. The network consists of three components: (i) a Description Generation Module that generates textual descriptions for each training category by prompting an LLM with several interrogative sentences, (ii) a Feature Extraction Module that includes two ViTs for sketch and image data, a transformer for extracting tokens of sentences of each training category, finally (iii) a Cross-modal Alignment Module that exchanges the token features of both text-sketch and text-image using cross-attention mechanism, and align the tokens locally and globally. Extensive experiments on three benchmark datasets show our superior performances over the state-of-the-art ZS-SBIR methods.
Read more7/2/2024