Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval

0

Sign in to get full access
Overview
- This paper presents a novel cross-modal attention alignment network with auxiliary text description for zero-shot sketch-based image retrieval.
- The proposed approach leverages the complementary information between sketches and text descriptions to improve the performance of zero-shot sketch-based image retrieval.
- The key innovation is the introduction of an auxiliary text description branch that aligns the cross-modal attention maps between sketches and images.
Plain English Explanation
The paper explores a new way to match sketches to images, even for objects that the model hasn't seen before. Typically, sketch-based image retrieval systems struggle when the sketches are of things the model hasn't been trained on. This paper's insight is to use the written descriptions of images, in addition to the sketches and images themselves, to help the model make these cross-modal connections.
The core idea is to have the model learn how the attention it pays to different parts of a sketch corresponds to the attention it pays to different parts of the related image. By also incorporating the text descriptions, the model can better understand how the visual and textual information aligns, which helps it match sketches to images it hasn't seen before. This zero-shot sketch-based image retrieval approach allows the model to generalize to new object categories.
Technical Explanation
The proposed Cross-Modal Attention Alignment Network (CMAN) has three key components:
- A sketch encoder and an image encoder to extract visual features.
- A text encoder to extract textual features from the image descriptions.
- An attention alignment module that aligns the cross-modal attention maps between the sketch and image features, guided by the text features.
The text encoder helps the model understand the semantic relationships between the sketches and images, which allows it to better match them, even for object categories it hasn't seen before. This zero-shot learning approach improves upon prior sketch-based retrieval methods that struggled with unseen object categories.
The authors evaluate their model on several sketch-based image retrieval benchmarks and show significant improvements over state-of-the-art methods, particularly in the zero-shot setting. This demonstrates the benefits of their cross-modal attention alignment approach combined with auxiliary text descriptions.
Critical Analysis
The paper makes a compelling case for the advantages of incorporating textual information to improve zero-shot sketch-based image retrieval. However, there are a few potential limitations worth considering:
-
The model relies on having access to high-quality text descriptions for the images, which may not always be available in real-world scenarios. Exploring ways to leverage more readily available textual information, such as image captions, could be an area for future research.
-
The performance improvements, while significant, may still not be sufficient for certain practical applications that require very high retrieval accuracy. Further research is needed to explore ways to enhance the model's zero-shot generalization capabilities.
-
The computational complexity of the proposed model, due to the additional text encoder and attention alignment module, may limit its applicability in resource-constrained environments. [Investigating more efficient architectural designs or knowledge distillation techniques could help address this concern.
Overall, this paper presents a promising approach to leveraging cross-modal information for zero-shot sketch-based image retrieval, but there are still opportunities for further improvements and refinements.
Conclusion
This paper introduces a novel cross-modal attention alignment network with auxiliary text descriptions to address the challenge of zero-shot sketch-based image retrieval. By aligning the attention maps between sketches and images, and incorporating textual information, the proposed model can more effectively match sketches to images of unseen object categories.
The results demonstrate significant improvements over state-of-the-art methods, highlighting the benefits of leveraging complementary cross-modal information. While the approach has some limitations, it represents an important step forward in improving the generalization capabilities of sketch-based image retrieval systems, which could have various applications in areas like visual search and creative tools.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval
Hanwen Su, Ge Song, Kai Huang, Jiyan Wang, Ming Yang
In this paper, we study the problem of zero-shot sketch-based image retrieval (ZS-SBIR). The prior methods tackle the problem in a two-modality setting with only category labels or even no textual information involved. However, the growing prevalence of Large-scale pre-trained Language Models (LLMs), which have demonstrated great knowledge learned from web-scale data, can provide us with an opportunity to conclude collective textual information. Our key innovation lies in the usage of text data as auxiliary information for images, thus leveraging the inherent zero-shot generalization ability that language offers. To this end, we propose an approach called Cross-Modal Attention Alignment Network with Auxiliary Text Description for zero-shot sketch-based image retrieval. The network consists of three components: (i) a Description Generation Module that generates textual descriptions for each training category by prompting an LLM with several interrogative sentences, (ii) a Feature Extraction Module that includes two ViTs for sketch and image data, a transformer for extracting tokens of sentences of each training category, finally (iii) a Cross-modal Alignment Module that exchanges the token features of both text-sketch and text-image using cross-attention mechanism, and align the tokens locally and globally. Extensive experiments on three benchmark datasets show our superior performances over the state-of-the-art ZS-SBIR methods.
Read more7/2/2024
🖼️
0
Zero-shot sketch-based remote sensing image retrieval based on multi-level and attention-guided tokenization
Bo Yang, Chen Wang, Xiaoshuang Ma, Beiping Song, Zhuang Liu, Fangde Sun
Effectively and efficiently retrieving images from remote sensing databases is a critical challenge in the realm of remote sensing big data. Utilizing hand-drawn sketches as retrieval inputs offers intuitive and user-friendly advantages, yet the potential of multi-level feature integration from sketches remains underexplored, leading to suboptimal retrieval performance. To address this gap, our study introduces a novel zero-shot, sketch-based retrieval method for remote sensing images, leveraging multi-level feature extraction, self-attention-guided tokenization and filtering, and cross-modality attention update. This approach employs only vision information and does not require semantic knowledge concerning the sketch and image. It starts by employing multi-level self-attention guided feature extraction to tokenize the query sketches, as well as self-attention feature extraction to tokenize the candidate images. It then employs cross-attention mechanisms to establish token correspondence between these two modalities, facilitating the computation of sketch-to-image similarity. Our method significantly outperforms existing sketch-based remote sensing image retrieval techniques, as evidenced by tests on multiple datasets. Notably, it also exhibits robust zero-shot learning capabilities and strong generalizability in handling unseen categories and novel remote sensing data. The method's scalability can be further enhanced by the pre-calculation of retrieval tokens for all candidate images in a database. This research underscores the significant potential of multi-level, attention-guided tokenization in cross-modal remote sensing image retrieval. For broader accessibility and research facilitation, we have made the code and dataset used in this study publicly available online. Code and dataset are available at https://github.com/Snowstormfly/Cross-modal-retrieval-MLAGT.
Read more5/17/2024
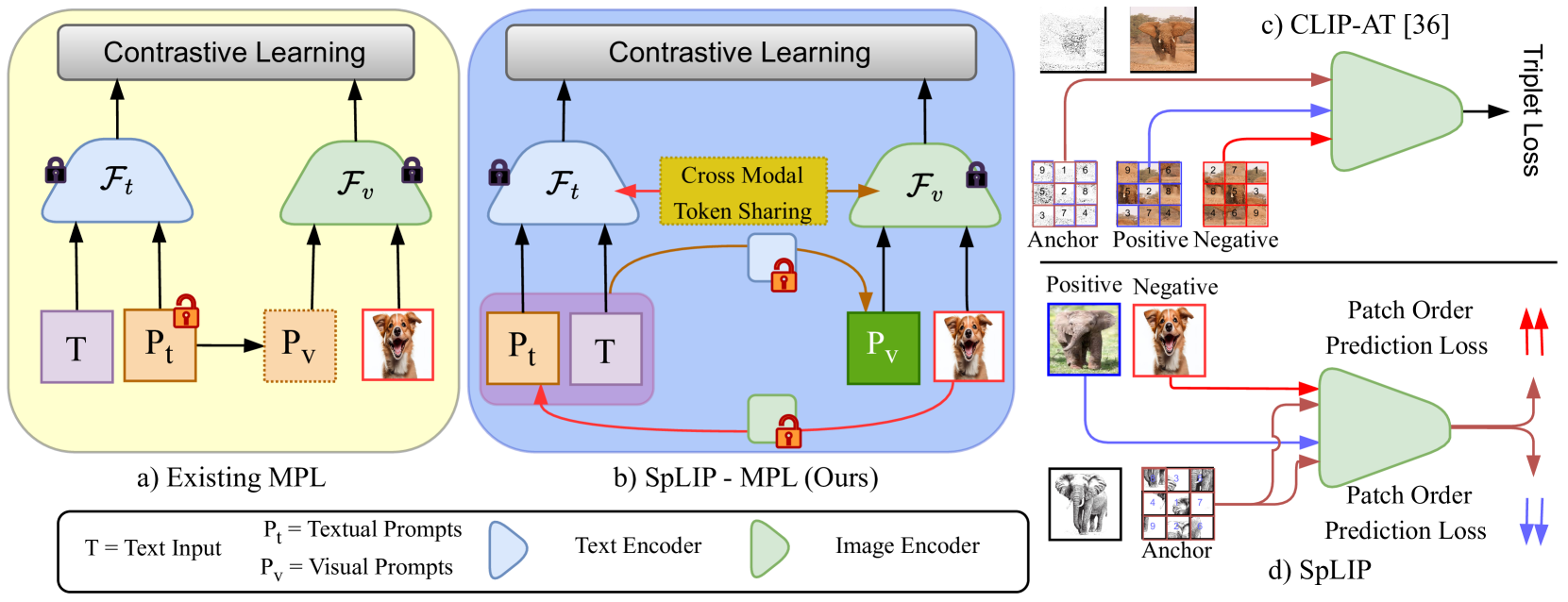
0
Elevating All Zero-Shot Sketch-Based Image Retrieval Through Multimodal Prompt Learning
Mainak Singha, Ankit Jha, Divyam Gupta, Pranav Singla, Biplab Banerjee
We address the challenges inherent in sketch-based image retrieval (SBIR) across various settings, including zero-shot SBIR, generalized zero-shot SBIR, and fine-grained zero-shot SBIR, by leveraging the vision-language foundation model CLIP. While recent endeavors have employed CLIP to enhance SBIR, these approaches predominantly follow uni-modal prompt processing and overlook to exploit CLIP's integrated visual and textual capabilities fully. To bridge this gap, we introduce SpLIP, a novel multi-modal prompt learning scheme designed to operate effectively with frozen CLIP backbones. We diverge from existing multi-modal prompting methods that treat visual and textual prompts independently or integrate them in a limited fashion, leading to suboptimal generalization. SpLIP implements a bi-directional prompt-sharing strategy that enables mutual knowledge exchange between CLIP's visual and textual encoders, fostering a more cohesive and synergistic prompt processing mechanism that significantly reduces the semantic gap between the sketch and photo embeddings. In addition to pioneering multi-modal prompt learning, we propose two innovative strategies for further refining the embedding space. The first is an adaptive margin generation for the sketch-photo triplet loss, regulated by CLIP's class textual embeddings. The second introduces a novel task, termed conditional cross-modal jigsaw, aimed at enhancing fine-grained sketch-photo alignment by implicitly modeling sketches' viable patch arrangement using knowledge of unshuffled photos. Our comprehensive experimental evaluations across multiple benchmarks demonstrate the superior performance of SpLIP in all three SBIR scenarios. Project page: https://mainaksingha01.github.io/SpLIP/ .
Read more7/24/2024
🖼️
0
Dual-Modal Prompting for Sketch-Based Image Retrieval
Liying Gao, Bingliang Jiao, Peng Wang, Shizhou Zhang, Hanwang Zhang, Yanning Zhang
Sketch-based image retrieval (SBIR) associates hand-drawn sketches with their corresponding realistic images. In this study, we aim to tackle two major challenges of this task simultaneously: i) zero-shot, dealing with unseen categories, and ii) fine-grained, referring to intra-category instance-level retrieval. Our key innovation lies in the realization that solely addressing this cross-category and fine-grained recognition task from the generalization perspective may be inadequate since the knowledge accumulated from limited seen categories might not be fully valuable or transferable to unseen target categories. Inspired by this, in this work, we propose a dual-modal prompting CLIP (DP-CLIP) network, in which an adaptive prompting strategy is designed. Specifically, to facilitate the adaptation of our DP-CLIP toward unpredictable target categories, we employ a set of images within the target category and the textual category label to respectively construct a set of category-adaptive prompt tokens and channel scales. By integrating the generated guidance, DP-CLIP could gain valuable category-centric insights, efficiently adapting to novel categories and capturing unique discriminative clues for effective retrieval within each target category. With these designs, our DP-CLIP outperforms the state-of-the-art fine-grained zero-shot SBIR method by 7.3% in Acc.@1 on the Sketchy dataset. Meanwhile, in the other two category-level zero-shot SBIR benchmarks, our method also achieves promising performance.
Read more4/30/2024