DualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion

0

Sign in to get full access
Overview
- This paper presents DualVC 3, a system that leverages language model-generated pseudo context to enable end-to-end low-latency streaming voice conversion.
- The key idea is to use a pre-trained language model to generate plausible context during voice conversion, which can help maintain the coherence and naturalness of the converted speech.
- The proposed approach aims to address the challenges of low-latency voice conversion, where the limited input information can lead to less natural-sounding results.
Plain English Explanation
The paper describes a voice conversion system called DualVC 3 that tries to improve the quality of converted speech in real-time, low-latency scenarios. In traditional voice conversion, the system only has access to the current audio input, which can make the converted speech sound unnatural or disjointed. To address this, DualVC 3 uses a language model to generate "pseudo context" - plausible text that could go along with the current audio. This additional context information helps the voice conversion model produce more coherent and natural-sounding output, even when working with a limited amount of input. The researchers believe this approach can lead to higher quality voice conversion in real-time applications where low latency is important.
Technical Explanation
The key innovation in DualVC 3 is the use of a pre-trained language model to generate pseudo context information that can be leveraged by the voice conversion model. Traditionally, voice conversion systems only have access to the current audio input, which can make it challenging to maintain coherence and naturalness in the converted speech, especially in low-latency scenarios.
To address this, the DualVC 3 system consists of two main components: a language model and a voice conversion model. The language model takes the partial input text (e.g., the current words being spoken) and generates plausible future context. This pseudo context is then used as an additional input to the voice conversion model, along with the current audio. By incorporating this language model-generated context, the voice conversion model can produce more coherent and natural-sounding output, even when working with limited input.
The researchers evaluate DualVC 3 on both objective and subjective metrics, comparing it to baseline voice conversion models and real-time accent conversion approaches. The results show that DualVC 3 outperforms these alternatives, demonstrating the benefits of leveraging language model-generated pseudo context for low-latency voice conversion.
Critical Analysis
The key strength of the DualVC 3 system is its ability to maintain coherence and naturalness in voice conversion, even when working with limited input data in real-time scenarios. By incorporating language model-generated pseudo context, the system is able to produce more natural-sounding output compared to traditional approaches.
However, the paper does not address the potential limitations of this approach. For example, the accuracy and appropriateness of the language model-generated pseudo context could be a potential issue, as any errors or biases in the language model could be reflected in the voice conversion output. Additionally, the computational complexity and latency introduced by the language model component is not discussed in detail.
Further research could explore ways to improve the robustness and efficiency of the DualVC 3 system, such as improving the audio codec to enable zero-shot text-to-speech translation. Additionally, incorporating user-specific or context-aware language models could potentially improve the relevance and accuracy of the generated pseudo context.
Conclusion
The DualVC 3 system presented in this paper demonstrates a novel approach to improving the quality of real-time, low-latency voice conversion by leveraging language model-generated pseudo context. This additional context information helps the voice conversion model maintain coherence and naturalness, even when working with limited input data.
While the results are promising, further research is needed to address potential limitations and optimize the system's performance. Nonetheless, the core idea of using language models to enhance voice conversion is a significant contribution that could have important implications for a wide range of real-time speech-based applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion
Ziqian Ning, Shuai Wang, Pengcheng Zhu, Zhichao Wang, Jixun Yao, Lei Xie, Mengxiao Bi
Streaming voice conversion has become increasingly popular for its potential in real-time applications. The recently proposed DualVC 2 has achieved robust and high-quality streaming voice conversion with a latency of about 180ms. Nonetheless, the recognition-synthesis framework hinders end-to-end optimization, and the instability of automatic speech recognition (ASR) model with short chunks makes it challenging to further reduce latency. To address these issues, we propose an end-to-end model, DualVC 3. With speaker-independent semantic tokens to guide the training of the content encoder, the dependency on ASR is removed and the model can operate under extremely small chunks, with cascading errors eliminated. A language model is trained on the content encoder output to produce pseudo context by iteratively predicting future frames, providing more contextual information for the decoder to improve conversion quality. Experimental results demonstrate that DualVC 3 achieves comparable performance to DualVC 2 in subjective and objective metrics, with a latency of only 50 ms.
Read more6/13/2024

0
StreamVoice+: Evolving into End-to-end Streaming Zero-shot Voice Conversion
Zhichao Wang, Yuanzhe Chen, Xinsheng Wang, Lei Xie, Yuping Wang
StreamVoice has recently pushed the boundaries of zero-shot voice conversion (VC) in the streaming domain. It uses a streamable language model (LM) with a context-aware approach to convert semantic features from automatic speech recognition (ASR) into acoustic features with the desired speaker timbre. Despite its innovations, StreamVoice faces challenges due to its dependency on a streaming ASR within a cascaded framework, which complicates system deployment and optimization, affects VC system's design and performance based on the choice of ASR, and struggles with conversion stability when faced with low-quality semantic inputs. To overcome these limitations, we introduce StreamVoice+, an enhanced LM-based end-to-end streaming framework that operates independently of streaming ASR. StreamVoice+ integrates a semantic encoder and a connector with the original StreamVoice framework, now trained using a non-streaming ASR. This model undergoes a two-stage training process: initially, the StreamVoice backbone is pre-trained for voice conversion and the semantic encoder for robust semantic extraction. Subsequently, the system is fine-tuned end-to-end, incorporating a LoRA matrix to activate comprehensive streaming functionality. Furthermore, StreamVoice+ mainly introduces two strategic enhancements to boost conversion quality: a residual compensation mechanism in the connector to ensure effective semantic transmission and a self-refinement strategy that leverages pseudo-parallel speech pairs generated by the conversion backbone to improve speech decoupling. Experiments demonstrate that StreamVoice+ not only achieves higher naturalness and speaker similarity in voice conversion than its predecessor but also provides versatile support for both streaming and non-streaming conversion scenarios.
Read more8/6/2024

0
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
Zhichao Wang, Yuanzhe Chen, Xinsheng Wang, Lei Xie, Yuping Wang
Recent language model (LM) advancements have showcased impressive zero-shot voice conversion (VC) performance. However, existing LM-based VC models usually apply offline conversion from source semantics to acoustic features, demanding the complete source speech and limiting their deployment to real-time applications. In this paper, we introduce StreamVoice, a novel streaming LM-based model for zero-shot VC, facilitating real-time conversion given arbitrary speaker prompts and source speech. Specifically, to enable streaming capability, StreamVoice employs a fully causal context-aware LM with a temporal-independent acoustic predictor, while alternately processing semantic and acoustic features at each time step of autoregression which eliminates the dependence on complete source speech. To address the potential performance degradation from the incomplete context in streaming processing, we enhance the context-awareness of the LM through two strategies: 1) teacher-guided context foresight, using a teacher model to summarize the present and future semantic context during training to guide the model's forecasting for missing context; 2) semantic masking strategy, promoting acoustic prediction from preceding corrupted semantic and acoustic input, enhancing context-learning ability. Notably, StreamVoice is the first LM-based streaming zero-shot VC model without any future look-ahead. Experiments demonstrate StreamVoice's streaming conversion capability while achieving zero-shot performance comparable to non-streaming VC systems.
Read more7/22/2024
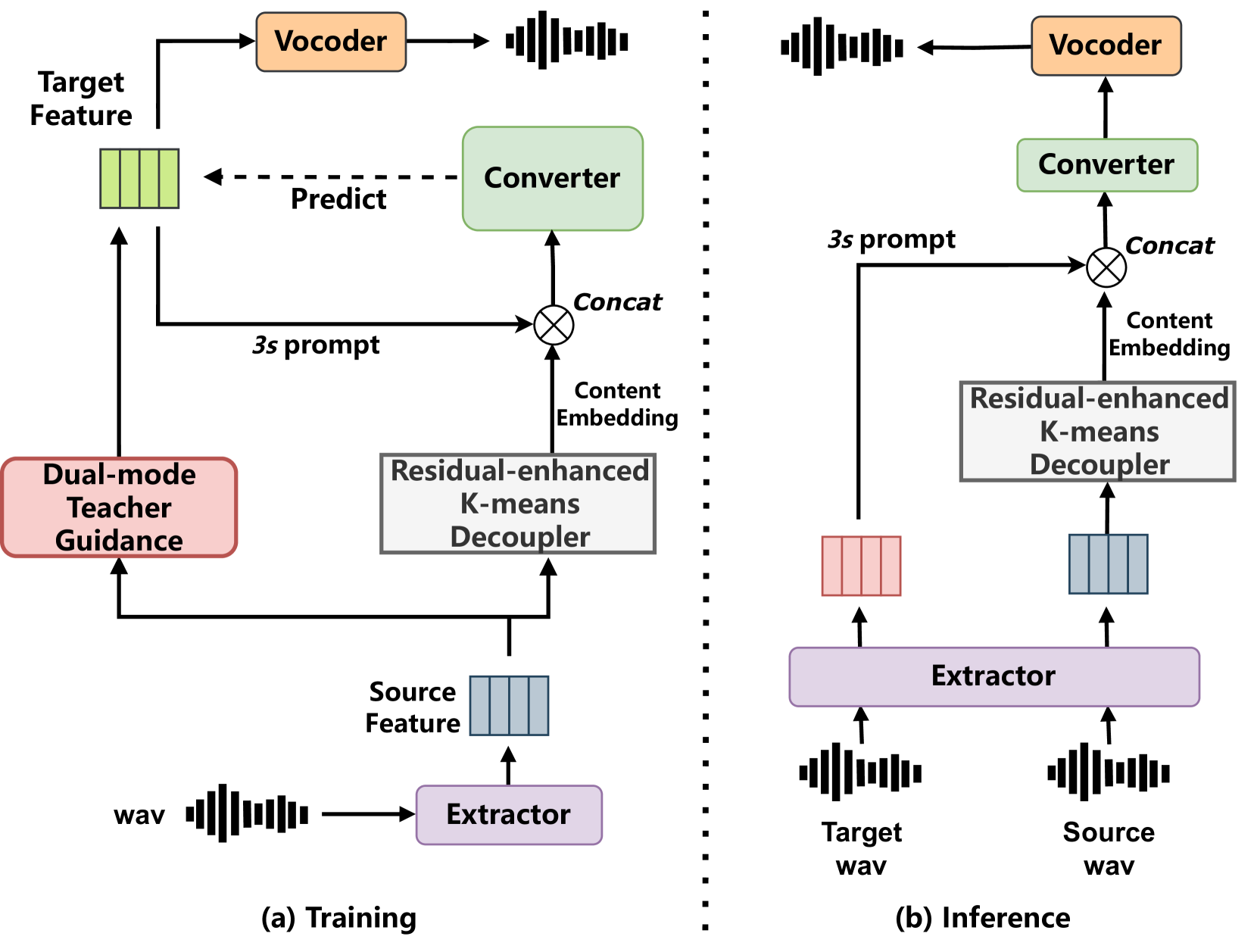
0
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Linhan Ma, Xinfa Zhu, Yuanjun Lv, Zhichao Wang, Ziqian Wang, Wendi He, Hongbin Zhou, Lei Xie
Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
Read more6/17/2024