Multi-level Temporal-channel Speaker Retrieval for Zero-shot Voice Conversion

0
🐍
Sign in to get full access
Overview
- The paper presents a novel zero-shot voice conversion (VC) model called MTCR-VC that can convert a source speech into the voice of any desired speaker using only a single utterance of the target speaker.
- Existing VC methods often use a speaker representation from a pre-trained speaker verification (SV) model or learn the speaker representation during VC training.
- However, these methods overlook the variations of speaker information in the temporal and frequency channel dimensions of speech, which limits their ability to accurately represent unseen speakers.
- MTCR-VC addresses this issue by introducing a fine-grained speaker modeling method called temporal-channel retrieval (TCR) to capture speaker characteristics from both the temporal and channel dimensions of speech.
Plain English Explanation
The paper describes a new voice conversion system that can transform a person's voice to sound like any other person, even if it has never heard the target person's voice before. This is called "zero-shot" voice conversion.
Typically, voice conversion systems use a pre-trained speaker verification model or learn the speaker's voice characteristics during training to achieve this zero-shot capability. However, these existing methods have a limitation - they don't fully capture the way a person's voice varies over time and across different frequency ranges in the speech signal.
To address this, the researchers developed a new speaker modeling technique called "temporal-channel retrieval" (TCR). This allows their system, called MTCR-VC, to more accurately represent the unique voice characteristics of speakers it's never encountered before. The TCR module looks at both the temporal (time-based) and channel (frequency-based) aspects of the speech to extract a rich speaker representation.
Additionally, MTCR-VC uses a "cycle-based training strategy" inspired by how humans produce speech. This helps the system better separate the content, style, and speaker identity when converting the voice. The end result is a voice conversion system that can model the target speaker's voice more accurately while maintaining natural-sounding speech.
Technical Explanation
The key innovation in MTCR-VC is the temporal-channel retrieval (TCR) module, which extracts a flexible speaker representation from both the temporal and frequency channel dimensions of the speech signal. This addresses a limitation of prior zero-shot VC methods that relied on speaker representations from pre-trained models or learned during training, which overlooked these dynamic variations in the speech.
The TCR module retrieves variable-length speaker representations guided by a pre-trained speaker verification (SV) model. This allows it to capture when and where speaker-specific information appears in the speech. The MTCR-VC model then stacks multiple TCR blocks to extract speaker representations at different granularity levels, inspired by the hierarchical process of human speech production.
To achieve better speech disentanglement and reconstruction, MTCR-VC also employs a cycle-based training strategy. This simulates the zero-shot inference process recurrently, using perceptual constraints on the content, style, and speaker identity to drive the training.
The experiments demonstrate that MTCR-VC outperforms previous zero-shot VC methods in modeling the target speaker's voice quality while maintaining good speech naturalness. This is attributed to the model's ability to flexibly adapt to the dynamic variation of speaker characteristics in the speech signal.
Critical Analysis
The paper presents a compelling approach to zero-shot voice conversion by addressing limitations in how existing methods model speaker information. The TCR module's ability to capture speaker characteristics from both temporal and frequency dimensions is a key strength, as it allows the model to better represent unseen speakers.
However, the paper does not provide detailed analysis on the robustness of the TCR module. It would be helpful to understand how it performs on a wider range of speakers, accents, and speaking styles, especially those that may differ significantly from the training data.
Additionally, the cycle-based training strategy is an interesting technique, but the paper could benefit from a deeper exploration of how this impacts the disentanglement of content, style, and speaker identity. Further analysis on failure cases or potential weaknesses of this approach would also strengthen the critical assessment.
Overall, the MTCR-VC model represents an important advancement in zero-shot voice conversion, but further research is needed to fully understand its capabilities and limitations in real-world applications.
Conclusion
The MTCR-VC model presented in this paper introduces a novel approach to zero-shot voice conversion that addresses limitations in how existing methods model speaker characteristics. By leveraging a fine-grained temporal-channel retrieval mechanism, the model can more accurately represent the dynamic variations of speaker information in speech, leading to improved voice conversion performance.
This research contributes to the ongoing efforts to develop more advanced and versatile voice conversion systems that can adapt to a wider range of speakers and applications. The insights gained from the MTCR-VC model may also inspire further innovations in speech representation learning and voice conversion technologies, ultimately enhancing our ability to manipulate and personalize speech in natural and compelling ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Multi-level Temporal-channel Speaker Retrieval for Zero-shot Voice Conversion
Zhichao Wang, Liumeng Xue, Qiuqiang Kong, Lei Xie, Yuanzhe Chen, Qiao Tian, Yuping Wang
Zero-shot voice conversion (VC) converts source speech into the voice of any desired speaker using only one utterance of the speaker without requiring additional model updates. Typical methods use a speaker representation from a pre-trained speaker verification (SV) model or learn speaker representation during VC training to achieve zero-shot VC. However, existing speaker modeling methods overlook the variation of speaker information richness in temporal and frequency channel dimensions of speech. This insufficient speaker modeling hampers the ability of the VC model to accurately represent unseen speakers who are not in the training dataset. In this study, we present a robust zero-shot VC model with multi-level temporal-channel retrieval, referred to as MTCR-VC. Specifically, to flexibly adapt to the dynamic-variant speaker characteristic in the temporal and channel axis of the speech, we propose a novel fine-grained speaker modeling method, called temporal-channel retrieval (TCR), to find out when and where speaker information appears in speech. It retrieves variable-length speaker representation from both temporal and channel dimensions under the guidance of a pre-trained SV model. Besides, inspired by the hierarchical process of human speech production, the MTCR speaker module stacks several TCR blocks to extract speaker representations from multi-granularity levels. Furthermore, to achieve better speech disentanglement and reconstruction, we introduce a cycle-based training strategy to simulate zero-shot inference recurrently. We adopt perpetual constraints on three aspects, including content, style, and speaker, to drive this process. Experiments demonstrate that MTCR-VC is superior to the previous zero-shot VC methods in modeling speaker timbre while maintaining good speech naturalness.
Read more5/21/2024
0
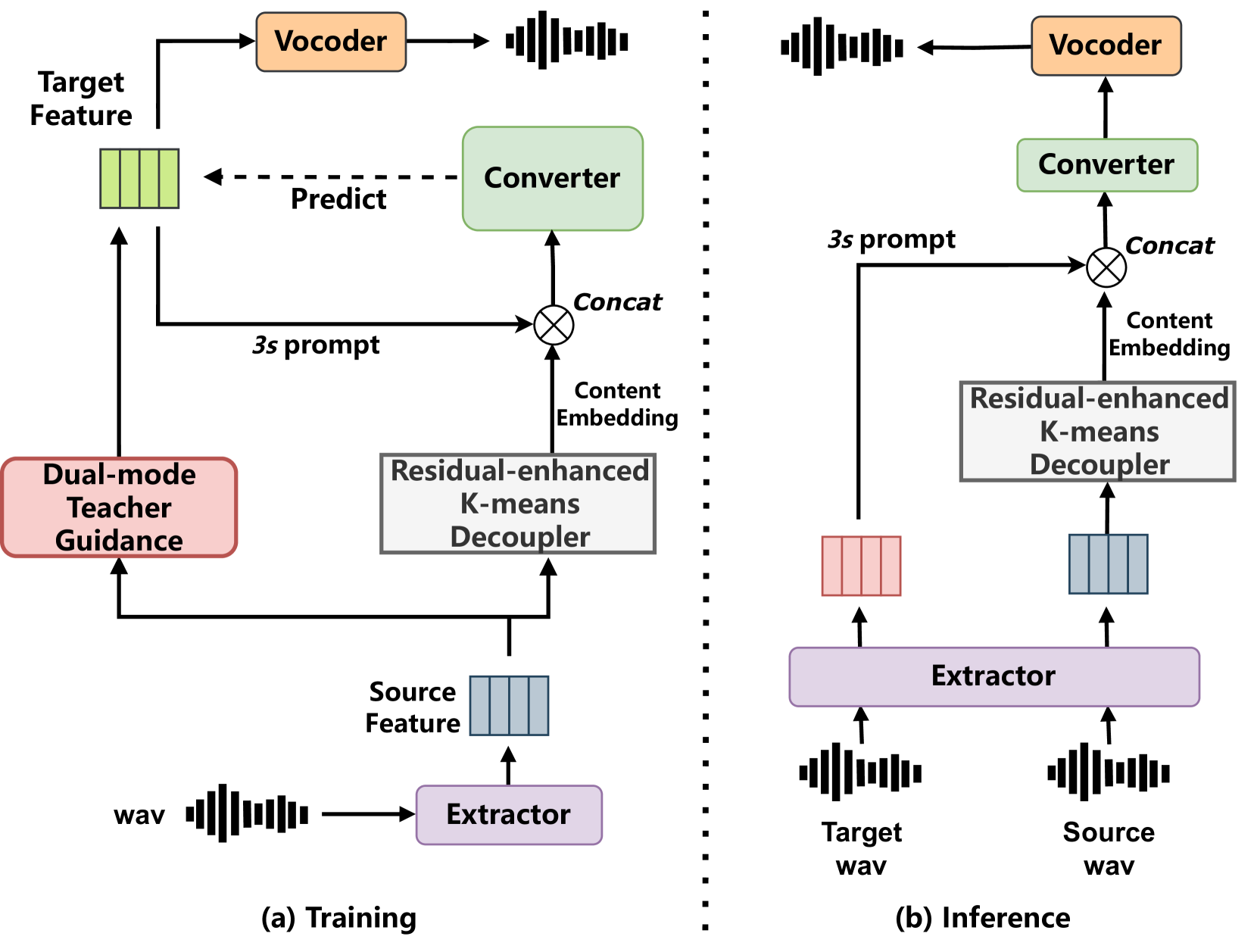
Vec-Tok-VC+: Residual-enhanced Robust Zero-shot Voice Conversion with Progressive Constraints in a Dual-mode Training Strategy
Linhan Ma, Xinfa Zhu, Yuanjun Lv, Zhichao Wang, Ziqian Wang, Wendi He, Hongbin Zhou, Lei Xie
Zero-shot voice conversion (VC) aims to transform source speech into arbitrary unseen target voice while keeping the linguistic content unchanged. Recent VC methods have made significant progress, but semantic losses in the decoupling process as well as training-inference mismatch still hinder conversion performance. In this paper, we propose Vec-Tok-VC+, a novel prompt-based zero-shot VC model improved from Vec-Tok Codec, achieving voice conversion given only a 3s target speaker prompt. We design a residual-enhanced K-Means decoupler to enhance the semantic content extraction with a two-layer clustering process. Besides, we employ teacher-guided refinement to simulate the conversion process to eliminate the training-inference mismatch, forming a dual-mode training strategy. Furthermore, we design a multi-codebook progressive loss function to constrain the layer-wise output of the model from coarse to fine to improve speaker similarity and content accuracy. Objective and subjective evaluations demonstrate that Vec-Tok-VC+ outperforms the strong baselines in naturalness, intelligibility, and speaker similarity.
Read more6/17/2024

0
Improvement Speaker Similarity for Zero-Shot Any-to-Any Voice Conversion of Whispered and Regular Speech
Anastasia Avdeeva, Aleksei Gusev
Zero-shot voice conversion aims to transfer the voice of a source speaker to that of a speaker unseen during training, while preserving the content information. Although various methods have been proposed to reconstruct speaker information in generated speech, there is still room for improvement in achieving high similarity between generated and ground truth recordings. Furthermore, zero-shot voice conversion for speech in specific domains, such as whispered, remains an unexplored area. To address this problem, we propose a SpeakerVC model that can effectively perform zero-shot speech conversion in both voiced and whispered domains, while being lightweight and capable of running in streaming mode without significant quality degradation. In addition, we explore methods to improve the quality of speaker identity transfer and demonstrate their effectiveness for a variety of voice conversion systems.
Read more8/22/2024

0
StreamVoice: Streamable Context-Aware Language Modeling for Real-time Zero-Shot Voice Conversion
Zhichao Wang, Yuanzhe Chen, Xinsheng Wang, Lei Xie, Yuping Wang
Recent language model (LM) advancements have showcased impressive zero-shot voice conversion (VC) performance. However, existing LM-based VC models usually apply offline conversion from source semantics to acoustic features, demanding the complete source speech and limiting their deployment to real-time applications. In this paper, we introduce StreamVoice, a novel streaming LM-based model for zero-shot VC, facilitating real-time conversion given arbitrary speaker prompts and source speech. Specifically, to enable streaming capability, StreamVoice employs a fully causal context-aware LM with a temporal-independent acoustic predictor, while alternately processing semantic and acoustic features at each time step of autoregression which eliminates the dependence on complete source speech. To address the potential performance degradation from the incomplete context in streaming processing, we enhance the context-awareness of the LM through two strategies: 1) teacher-guided context foresight, using a teacher model to summarize the present and future semantic context during training to guide the model's forecasting for missing context; 2) semantic masking strategy, promoting acoustic prediction from preceding corrupted semantic and acoustic input, enhancing context-learning ability. Notably, StreamVoice is the first LM-based streaming zero-shot VC model without any future look-ahead. Experiments demonstrate StreamVoice's streaming conversion capability while achieving zero-shot performance comparable to non-streaming VC systems.
Read more7/22/2024