TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation
2405.17809
0
0

Abstract
There is a rising interest and trend in research towards directly translating speech from one language to another, known as end-to-end speech-to-speech translation. However, most end-to-end models struggle to outperform cascade models, i.e., a pipeline framework by concatenating speech recognition, machine translation and text-to-speech models. The primary challenges stem from the inherent complexities involved in direct translation tasks and the scarcity of data. In this study, we introduce a novel model framework TransVIP that leverages diverse datasets in a cascade fashion yet facilitates end-to-end inference through joint probability. Furthermore, we propose two separated encoders to preserve the speaker's voice characteristics and isochrony from the source speech during the translation process, making it highly suitable for scenarios such as video dubbing. Our experiments on the French-English language pair demonstrate that our model outperforms the current state-of-the-art speech-to-speech translation model.
Create account to get full access
Overview
- This paper introduces TransVIP, a speech-to-speech translation system that preserves the voice characteristics and timing of the original speech during translation.
- The system aims to maintain the original speaker's voice and natural speaking rhythm, which can be important for maintaining emotional expressiveness and intelligibility.
- The authors propose novel neural network architectures and training techniques to achieve this goal of voice and isochrony (consistent timing) preservation.
Plain English Explanation
The TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation paper presents a new way to translate spoken language while keeping the original speaker's voice and natural rhythm.
When translating speech, it's important not just to get the words right, but also to preserve the speaker's unique voice qualities and the timing of their speech. This can help maintain the emotional expression and intelligibility of the original message. The authors of this paper have developed a system called TransVIP that aims to do this.
TransVIP uses novel neural network architectures and training techniques to translate speech while keeping the original speaker's voice and the natural timing of their speech. This means the translated speech will sound like it's coming from the same person, with the same speaking rhythm, even though the words are in a different language.
This could be particularly useful in scenarios like international video calls or dubbing of foreign media, where preserving the personality and naturalness of the original speech is important. By maintaining the voice and timing, TransVIP helps ensure the translated speech sounds as natural and expressive as possible.
Technical Explanation
The TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation paper presents a novel speech-to-speech translation system that aims to preserve the voice characteristics and timing of the original speech during translation.
The key innovation is the use of novel neural network architectures and training techniques to achieve this voice and isochrony (consistent timing) preservation. The system consists of several components:
- A speech recognition module to transcribe the input speech into text.
- A translation module to translate the text into the target language.
- A text-to-speech (TTS) module to generate the translated speech.
Crucially, the TTS module is designed to maintain the voice characteristics and timing of the original speech. This is achieved through:
- Voice conversion techniques to preserve the original speaker's voice.
- Non-autoregressive speech generation to preserve the timing and rhythm of the original speech.
The authors also introduce novel training techniques, such as few-shot voice conversion and zero-shot text-to-speech, to further enhance the performance of the system.
The proposed TransVIP system is evaluated on various language pairs and shows promising results in preserving the original speaker's voice and timing during translation, which can be important for maintaining emotional expressiveness and intelligibility.
Critical Analysis
The TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation paper presents a compelling approach to speech-to-speech translation that addresses an important problem in the field.
One potential limitation is the reliance on specific neural network architectures and training techniques, which may limit the generalizability of the system. The authors acknowledge that further research is needed to explore the robustness of the approach across a wider range of languages and speaker characteristics.
Additionally, the paper does not provide a detailed analysis of the computational costs or latency of the TransVIP system, which could be an important practical consideration for real-world deployment.
It would also be valuable to see more extensive user testing and qualitative evaluation to assess the system's performance in terms of preserving the emotional expressiveness and intelligibility of the translated speech.
Overall, the TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation paper presents an innovative approach that addresses an important challenge in speech translation. Further research and development could help refine the system and explore its broader applicability.
Conclusion
The TransVIP: Speech to Speech Translation System with Voice and Isochrony Preservation paper introduces a novel speech-to-speech translation system that aims to preserve the voice characteristics and timing of the original speech during translation.
By using specialized neural network architectures and training techniques, the TransVIP system is able to maintain the unique voice of the speaker and the natural rhythm of their speech, even when translating into a different language. This can help to preserve the emotional expressiveness and intelligibility of the original message, which is an important consideration for many real-world applications of speech translation.
While the paper identifies some potential limitations and areas for further research, the TransVIP approach represents an important step forward in the field of speech translation, with the potential to significantly improve the user experience and practical utility of these systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
CrossVoice: Crosslingual Prosody Preserving Cascade-S2ST using Transfer Learning
Medha Hira, Arnav Goel, Anubha Gupta
0
0
This paper presents CrossVoice, a novel cascade-based Speech-to-Speech Translation (S2ST) system employing advanced ASR, MT, and TTS technologies with cross-lingual prosody preservation through transfer learning. We conducted comprehensive experiments comparing CrossVoice with direct-S2ST systems, showing improved BLEU scores on tasks such as Fisher Es-En, VoxPopuli Fr-En and prosody preservation on benchmark datasets CVSS-T and IndicTTS. With an average mean opinion score of 3.75 out of 4, speech synthesized by CrossVoice closely rivals human speech on the benchmark, highlighting the efficacy of cascade-based systems and transfer learning in multilingual S2ST with prosody transfer.
6/19/2024
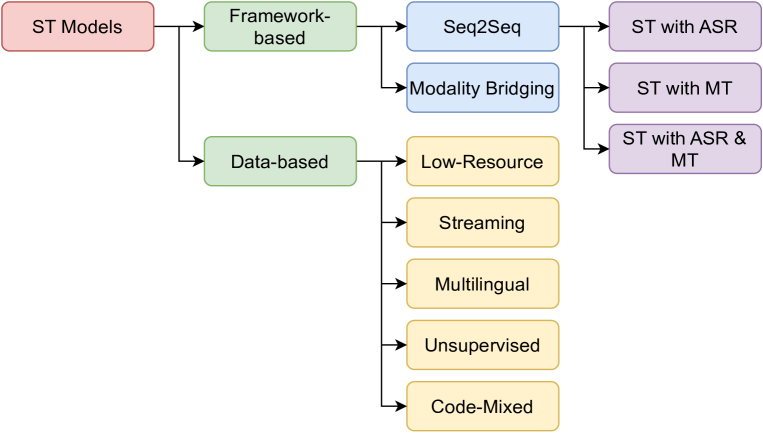
End-to-End Speech-to-Text Translation: A Survey
Nivedita Sethiya, Chandresh Kumar Maurya
0
0
Speech-to-text translation pertains to the task of converting speech signals in a language to text in another language. It finds its application in various domains, such as hands-free communication, dictation, video lecture transcription, and translation, to name a few. Automatic Speech Recognition (ASR), as well as Machine Translation(MT) models, play crucial roles in traditional ST translation, enabling the conversion of spoken language in its original form to written text and facilitating seamless cross-lingual communication. ASR recognizes spoken words, while MT translates the transcribed text into the target language. Such disintegrated models suffer from cascaded error propagation and high resource and training costs. As a result, researchers have been exploring end-to-end (E2E) models for ST translation. However, to our knowledge, there is no comprehensive review of existing works on E2E ST. The present survey, therefore, discusses the work in this direction. Our attempt has been to provide a comprehensive review of models employed, metrics, and datasets used for ST tasks, providing challenges and future research direction with new insights. We believe this review will be helpful to researchers working on various applications of ST models.
6/11/2024

Can We Achieve High-quality Direct Speech-to-Speech Translation without Parallel Speech Data?
Qingkai Fang, Shaolei Zhang, Zhengrui Ma, Min Zhang, Yang Feng
0
0
Recently proposed two-pass direct speech-to-speech translation (S2ST) models decompose the task into speech-to-text translation (S2TT) and text-to-speech (TTS) within an end-to-end model, yielding promising results. However, the training of these models still relies on parallel speech data, which is extremely challenging to collect. In contrast, S2TT and TTS have accumulated a large amount of data and pretrained models, which have not been fully utilized in the development of S2ST models. Inspired by this, in this paper, we first introduce a composite S2ST model named ComSpeech, which can seamlessly integrate any pretrained S2TT and TTS models into a direct S2ST model. Furthermore, to eliminate the reliance on parallel speech data, we propose a novel training method ComSpeech-ZS that solely utilizes S2TT and TTS data. It aligns representations in the latent space through contrastive learning, enabling the speech synthesis capability learned from the TTS data to generalize to S2ST in a zero-shot manner. Experimental results on the CVSS dataset show that when the parallel speech data is available, ComSpeech surpasses previous two-pass models like UnitY and Translatotron 2 in both translation quality and decoding speed. When there is no parallel speech data, ComSpeech-ZS lags behind name by only 0.7 ASR-BLEU and outperforms the cascaded models.
6/12/2024

DualVC 3: Leveraging Language Model Generated Pseudo Context for End-to-end Low Latency Streaming Voice Conversion
Ziqian Ning, Shuai Wang, Pengcheng Zhu, Zhichao Wang, Jixun Yao, Lei Xie, Mengxiao Bi
0
0
Streaming voice conversion has become increasingly popular for its potential in real-time applications. The recently proposed DualVC 2 has achieved robust and high-quality streaming voice conversion with a latency of about 180ms. Nonetheless, the recognition-synthesis framework hinders end-to-end optimization, and the instability of automatic speech recognition (ASR) model with short chunks makes it challenging to further reduce latency. To address these issues, we propose an end-to-end model, DualVC 3. With speaker-independent semantic tokens to guide the training of the content encoder, the dependency on ASR is removed and the model can operate under extremely small chunks, with cascading errors eliminated. A language model is trained on the content encoder output to produce pseudo context by iteratively predicting future frames, providing more contextual information for the decoder to improve conversion quality. Experimental results demonstrate that DualVC 3 achieves comparable performance to DualVC 2 in subjective and objective metrics, with a latency of only 50 ms.
6/13/2024