DyFADet: Dynamic Feature Aggregation for Temporal Action Detection

0
Sign in to get full access
Overview
- Presents a dynamic feature aggregation approach for temporal action detection
- Proposes a novel network architecture called DyFADet that dynamically adjusts the feature aggregation process during inference
- Aims to improve the performance of temporal action detection models on untrimmed videos
Plain English Explanation
The paper introduces a new method called DyFADet for detecting actions in untrimmed video clips. Temporal action detection is the task of identifying when specific actions occur in a video, which is an important problem for applications like video understanding and surveillance.
The key idea behind DyFADet is to dynamically adjust how the model aggregates features over time during inference. Previous approaches used fixed feature aggregation, but DyFADet learns to change the aggregation process based on the input video. This allows the model to better handle the varied temporal structure of different actions.
The paper on one-stage open-vocabulary temporal action detection and the paper on end-to-end temporal action detection are related works that also tackle temporal action detection, but with different approaches.
Overall, DyFADet aims to improve the accuracy and robustness of temporal action detection models, which could have applications in areas like video analysis and surveillance.
Technical Explanation
The core contribution of the paper is the DyFADet network architecture, which dynamically adjusts the feature aggregation process during inference. Typical temporal action detection models use a fixed feature aggregation module, such as average pooling or max pooling, to combine features over the temporal dimension.
In contrast, DyFADet learns a dynamically-adjusted feature aggregation module. This module takes in the current video features and outputs a set of weights that are applied to aggregate the features over time. The aggregation weights are predicted individually for each action class, allowing the model to focus on the relevant temporal regions for each action.
The paper on TE-TAD: Towards Full End-to-End Temporal Action Detection and the paper on Adapting Short-Term Transformers for Temporal Action Detection in Untrimmed Videos explore alternative architectural approaches for temporal action detection.
DyFADet is evaluated on standard temporal action detection benchmarks, where it outperforms previous state-of-the-art methods. The authors also provide ablation studies to demonstrate the importance of the dynamic feature aggregation module.
Critical Analysis
The paper presents a novel and well-designed approach for temporal action detection. The dynamic feature aggregation module is a clever idea that allows the model to adapt its temporal reasoning to the characteristics of each action class.
However, the paper does not provide much discussion of the limitations or potential issues with the proposed method. For example, it's unclear how DyFADet would perform on very long videos with many actions, or how it might handle actions with complex temporal dependencies.
Additionally, the paper on An Effective and Efficient Approach for Dense Multi-Label Action Recognition explores a related problem of dense multi-label action recognition, which could provide useful insights for extending DyFADet to handle more complex video understanding tasks.
Overall, the technical details of DyFADet are well-explained, and the experimental results are promising. However, a more thorough discussion of the method's limitations and future research directions would help readers better understand the strengths and weaknesses of the approach.
Conclusion
The DyFADet paper presents a novel dynamic feature aggregation approach for temporal action detection in untrimmed videos. By learning to adjust the feature aggregation process during inference, the model can better handle the varied temporal structures of different actions.
The experimental results demonstrate that DyFADet outperforms previous state-of-the-art methods on standard benchmarks. While the paper does not explore the limitations of the approach in-depth, the dynamic feature aggregation concept is a promising direction for improving the performance and robustness of temporal action detection models.
Overall, the DyFADet paper contributes a novel and effective solution to the important problem of temporal action detection, which has applications in areas like video understanding and surveillance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DyFADet: Dynamic Feature Aggregation for Temporal Action Detection
Le Yang, Ziwei Zheng, Yizeng Han, Hao Cheng, Shiji Song, Gao Huang, Fan Li
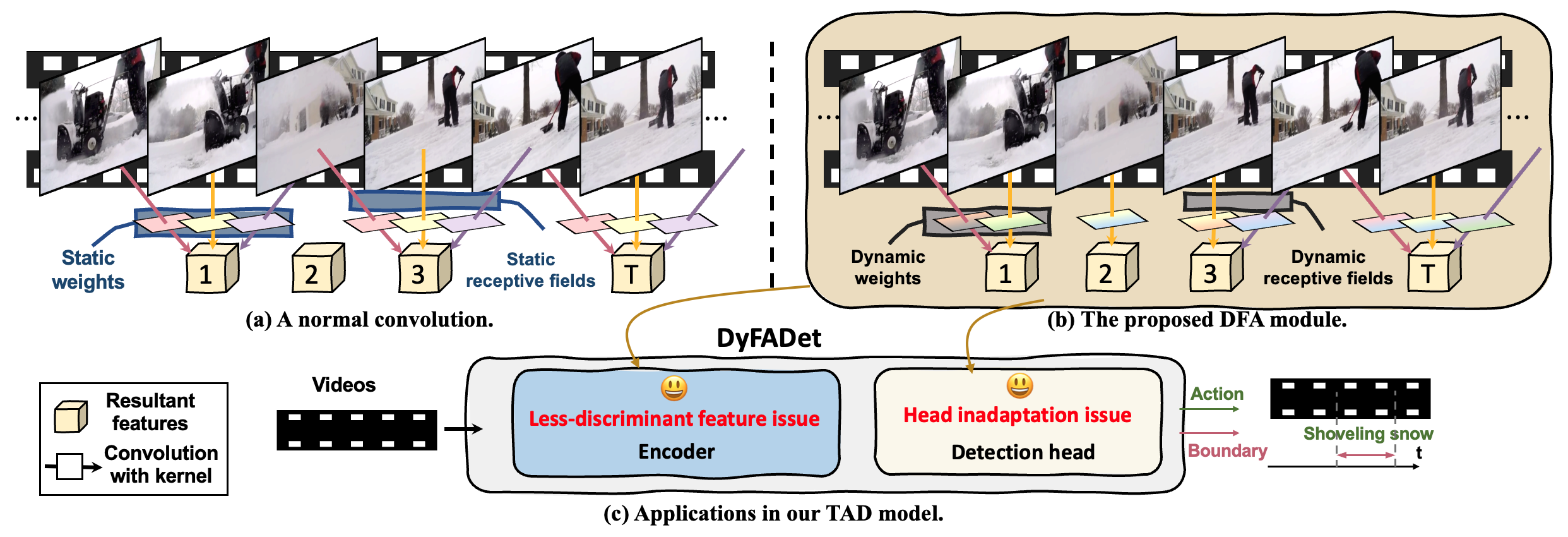
Recent proposed neural network-based Temporal Action Detection (TAD) models are inherently limited to extracting the discriminative representations and modeling action instances with various lengths from complex scenes by shared-weights detection heads. Inspired by the successes in dynamic neural networks, in this paper, we build a novel dynamic feature aggregation (DFA) module that can simultaneously adapt kernel weights and receptive fields at different timestamps. Based on DFA, the proposed dynamic encoder layer aggregates the temporal features within the action time ranges and guarantees the discriminability of the extracted representations. Moreover, using DFA helps to develop a Dynamic TAD head (DyHead), which adaptively aggregates the multi-scale features with adjusted parameters and learned receptive fields better to detect the action instances with diverse ranges from videos. With the proposed encoder layer and DyHead, a new dynamic TAD model, DyFADet, achieves promising performance on a series of challenging TAD benchmarks, including HACS-Segment, THUMOS14, ActivityNet-1.3, Epic-Kitchen 100, Ego4D-Moment QueriesV1.0, and FineAction. Code is released to https://github.com/yangle15/DyFADet-pytorch.
Read more7/4/2024

0
Harnessing Temporal Causality for Advanced Temporal Action Detection
Shuming Liu, Lin Sui, Chen-Lin Zhang, Fangzhou Mu, Chen Zhao, Bernard Ghanem
As a fundamental task in long-form video understanding, temporal action detection (TAD) aims to capture inherent temporal relations in untrimmed videos and identify candidate actions with precise boundaries. Over the years, various networks, including convolutions, graphs, and transformers, have been explored for effective temporal modeling for TAD. However, these modules typically treat past and future information equally, overlooking the crucial fact that changes in action boundaries are essentially causal events. Inspired by this insight, we propose leveraging the temporal causality of actions to enhance TAD representation by restricting the model's access to only past or future context. We introduce CausalTAD, which combines causal attention and causal Mamba to achieve state-of-the-art performance on multiple benchmarks. Notably, with CausalTAD, we ranked 1st in the Action Recognition, Action Detection, and Audio-Based Interaction Detection tracks at the EPIC-Kitchens Challenge 2024, as well as 1st in the Moment Queries track at the Ego4D Challenge 2024. Our code is available at https://github.com/sming256/OpenTAD/.
Read more7/29/2024

0
Introducing Gating and Context into Temporal Action Detection
Aglind Reka, Diana Laura Borza, Dominick Reilly, Michal Balazia, Francois Bremond
Temporal Action Detection (TAD), the task of localizing and classifying actions in untrimmed video, remains challenging due to action overlaps and variable action durations. Recent findings suggest that TAD performance is dependent on the structural design of transformers rather than on the self-attention mechanism. Building on this insight, we propose a refined feature extraction process through lightweight, yet effective operations. First, we employ a local branch that employs parallel convolutions with varying window sizes to capture both fine-grained and coarse-grained temporal features. This branch incorporates a gating mechanism to select the most relevant features. Second, we introduce a context branch that uses boundary frames as key-value pairs to analyze their relationship with the central frame through cross-attention. The proposed method captures temporal dependencies and improves contextual understanding. Evaluations of the gating mechanism and context branch on challenging datasets (THUMOS14 and EPIC-KITCHEN 100) show a consistent improvement over the baseline and existing methods.
Read more9/9/2024

0
One-Stage Open-Vocabulary Temporal Action Detection Leveraging Temporal Multi-scale and Action Label Features
Trung Thanh Nguyen, Yasutomo Kawanishi, Takahiro Komamizu, Ichiro Ide
Open-vocabulary Temporal Action Detection (Open-vocab TAD) is an advanced video analysis approach that expands Closed-vocabulary Temporal Action Detection (Closed-vocab TAD) capabilities. Closed-vocab TAD is typically confined to localizing and classifying actions based on a predefined set of categories. In contrast, Open-vocab TAD goes further and is not limited to these predefined categories. This is particularly useful in real-world scenarios where the variety of actions in videos can be vast and not always predictable. The prevalent methods in Open-vocab TAD typically employ a 2-stage approach, which involves generating action proposals and then identifying those actions. However, errors made during the first stage can adversely affect the subsequent action identification accuracy. Additionally, existing studies face challenges in handling actions of different durations owing to the use of fixed temporal processing methods. Therefore, we propose a 1-stage approach consisting of two primary modules: Multi-scale Video Analysis (MVA) and Video-Text Alignment (VTA). The MVA module captures actions at varying temporal resolutions, overcoming the challenge of detecting actions with diverse durations. The VTA module leverages the synergy between visual and textual modalities to precisely align video segments with corresponding action labels, a critical step for accurate action identification in Open-vocab scenarios. Evaluations on widely recognized datasets THUMOS14 and ActivityNet-1.3, showed that the proposed method achieved superior results compared to the other methods in both Open-vocab and Closed-vocab settings. This serves as a strong demonstration of the effectiveness of the proposed method in the TAD task.
Read more5/1/2024