Inconsistency-Aware Cross-Attention for Audio-Visual Fusion in Dimensional Emotion Recognition
2405.12853
0
0
👁️
Abstract
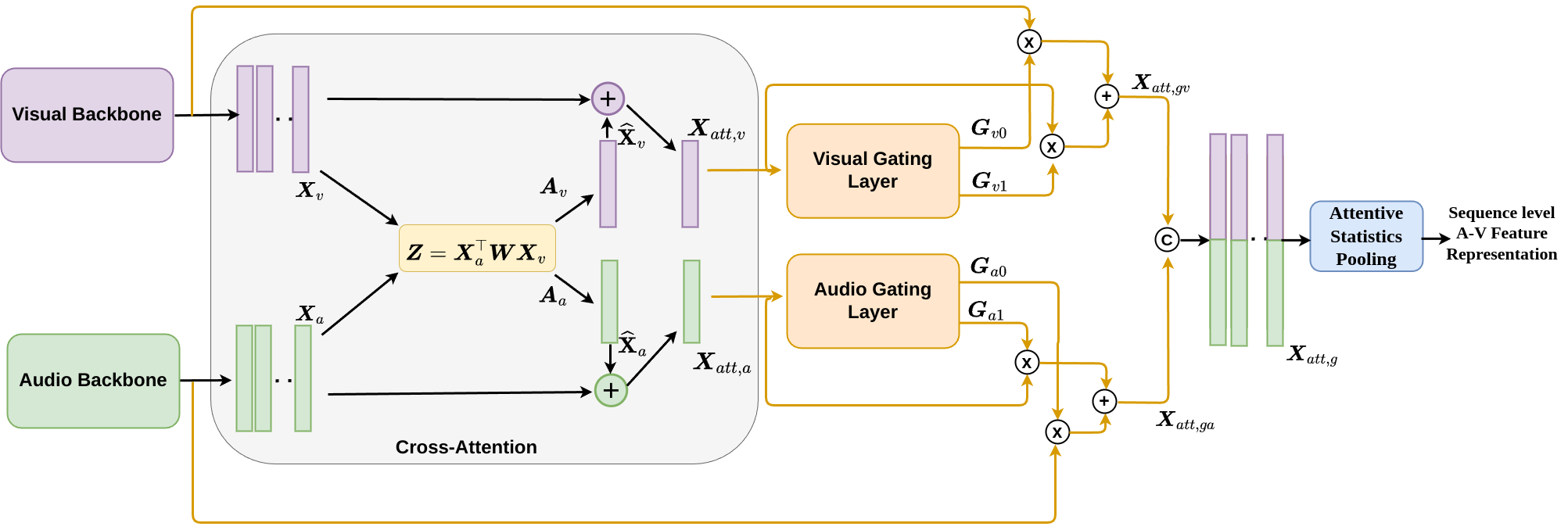
Leveraging complementary relationships across modalities has recently drawn a lot of attention in multimodal emotion recognition. Most of the existing approaches explored cross-attention to capture the complementary relationships across the modalities. However, the modalities may also exhibit weak complementary relationships, which may deteriorate the cross-attended features, resulting in poor multimodal feature representations. To address this problem, we propose Inconsistency-Aware Cross-Attention (IACA), which can adaptively select the most relevant features on-the-fly based on the strong or weak complementary relationships across audio and visual modalities. Specifically, we design a two-stage gating mechanism that can adaptively select the appropriate relevant features to deal with weak complementary relationships. Extensive experiments are conducted on the challenging Aff-Wild2 dataset to show the robustness of the proposed model.
Create account to get full access
Overview
- Multimodal emotion recognition has gained significant attention, often using cross-attention to capture complementary relationships across modalities.
- However, weak complementary relationships between modalities can deteriorate the cross-attended features, leading to poor multimodal feature representations.
- The paper proposes a novel approach called Inconsistency-Aware Cross-Attention (IACA) to adaptively select the most relevant features based on the strength of complementary relationships between audio and visual modalities.
Plain English Explanation
Emotion recognition is an important task in artificial intelligence, and researchers are increasingly using information from multiple sources (like audio and video) to improve its accuracy. One common approach is to use cross-attention, where the model learns to highlight the most relevant parts of each modality to recognize emotions.
However, the audio and video signals don't always complement each other perfectly. When the relationship between them is weak, the cross-attention mechanism can actually hurt the model's performance by focusing on the wrong features. To address this, the researchers developed a new method called Inconsistency-Aware Cross-Attention (IACA).
IACA uses a two-stage gating mechanism to adaptively select the most relevant features from the audio and video, depending on how well they complement each other. This allows the model to focus on the strong relationships and downplay the weak ones, leading to better emotion recognition.
The researchers tested IACA on a challenging emotion dataset and found that it outperformed other state-of-the-art approaches, demonstrating the benefits of their adaptive cross-attention strategy.
Technical Explanation
The paper proposes a novel Inconsistency-Aware Cross-Attention (IACA) mechanism to address the problem of weak complementary relationships between audio and visual modalities in multimodal emotion recognition.
Existing approaches often use cross-attention to capture the complementary relationships between modalities. However, when the relationships are weak, the cross-attended features can deteriorate, leading to poor multimodal feature representations.
To overcome this, the authors design a two-stage gating mechanism in IACA. The first stage adaptively selects the most relevant features from each modality based on their individual salience. The second stage then further refines the selection based on the strength of the complementary relationship between the modalities.
This adaptive selection process allows IACA to focus on the strong complementary relationships and downplay the weak ones, resulting in more robust multimodal feature representations. The authors evaluate IACA on the challenging Aff-Wild2 dataset for emotion recognition and demonstrate its superiority over existing audio-visual fusion and cross-attention approaches.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed IACA method, including extensive experiments on the Aff-Wild2 dataset. The authors acknowledge the potential limitations of their approach, such as its applicability to only audio-visual modalities and the need for further exploration of the gating mechanism's interpretability.
One area for further research could be exploring the generalization of IACA to other multimodal tasks beyond emotion recognition, such as audio-visual person verification or multimodal sentiment analysis. Additionally, investigating the impact of different types of weak complementary relationships on the model's performance could provide valuable insights.
Overall, the paper presents a compelling solution to the problem of weak complementary relationships in multimodal learning, and the IACA method demonstrates the potential of adaptive cross-attention mechanisms to improve multimodal feature representations.
Conclusion
The Inconsistency-Aware Cross-Attention (IACA) method proposed in this paper addresses a key challenge in multimodal emotion recognition: the deterioration of cross-attended features due to weak complementary relationships between modalities. By adaptively selecting the most relevant features based on the strength of the complementary relationships, IACA can produce more robust multimodal feature representations, leading to improved emotion recognition performance.
The authors' thorough evaluation and discussion of the method's strengths and limitations provide a solid foundation for future research in this area. As multimodal learning continues to gain traction in various applications, adaptive approaches like IACA could play a crucial role in unlocking the full potential of complementary information across modalities.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Dynamic Cross Attention for Audio-Visual Person Verification
R. Gnana Praveen, Jahangir Alam
0
0
Although person or identity verification has been predominantly explored using individual modalities such as face and voice, audio-visual fusion has recently shown immense potential to outperform unimodal approaches. Audio and visual modalities are often expected to pose strong complementary relationships, which plays a crucial role in effective audio-visual fusion. However, they may not always strongly complement each other, they may also exhibit weak complementary relationships, resulting in poor audio-visual feature representations. In this paper, we propose a Dynamic Cross-Attention (DCA) model that can dynamically select the cross-attended or unattended features on the fly based on the strong or weak complementary relationships, respectively, across audio and visual modalities. In particular, a conditional gating layer is designed to evaluate the contribution of the cross-attention mechanism and choose cross-attended features only when they exhibit strong complementary relationships, otherwise unattended features. Extensive experiments are conducted on the Voxceleb1 dataset to demonstrate the robustness of the proposed model. Results indicate that the proposed model consistently improves the performance on multiple variants of cross-attention while outperforming the state-of-the-art methods.
4/23/2024
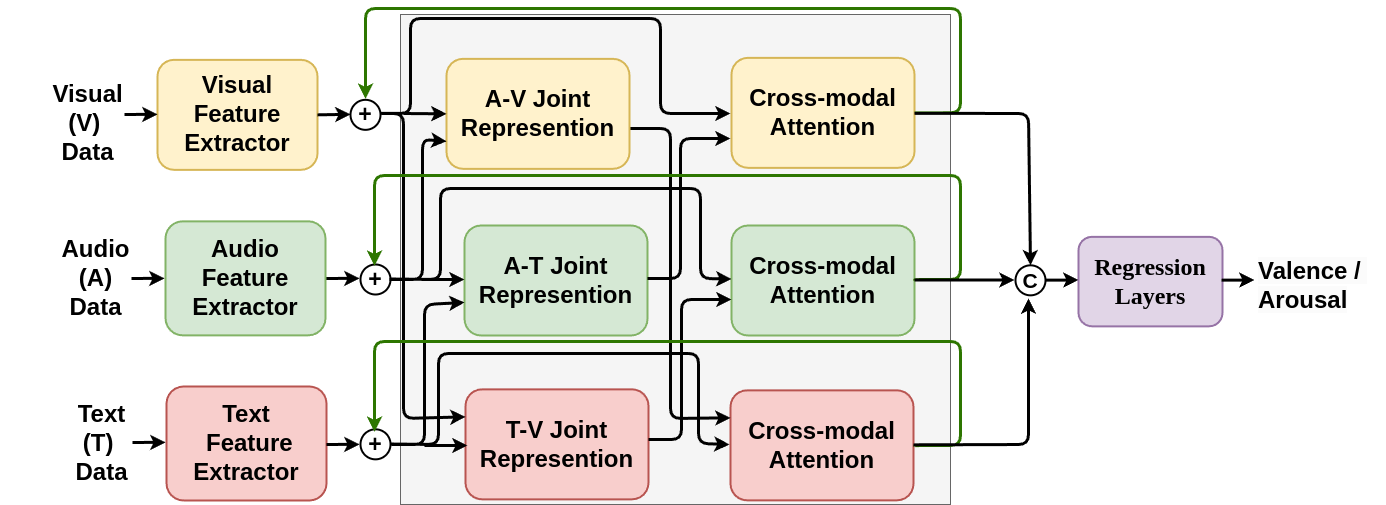
Recursive Joint Cross-Modal Attention for Multimodal Fusion in Dimensional Emotion Recognition
R. Gnana Praveen, Jahangir Alam
0
0
Though multimodal emotion recognition has achieved significant progress over recent years, the potential of rich synergic relationships across the modalities is not fully exploited. In this paper, we introduce Recursive Joint Cross-Modal Attention (RJCMA) to effectively capture both intra- and inter-modal relationships across audio, visual, and text modalities for dimensional emotion recognition. In particular, we compute the attention weights based on cross-correlation between the joint audio-visual-text feature representations and the feature representations of individual modalities to simultaneously capture intra- and intermodal relationships across the modalities. The attended features of the individual modalities are again fed as input to the fusion model in a recursive mechanism to obtain more refined feature representations. We have also explored Temporal Convolutional Networks (TCNs) to improve the temporal modeling of the feature representations of individual modalities. Extensive experiments are conducted to evaluate the performance of the proposed fusion model on the challenging Affwild2 dataset. By effectively capturing the synergic intra- and inter-modal relationships across audio, visual, and text modalities, the proposed fusion model achieves a Concordance Correlation Coefficient (CCC) of 0.585 (0.542) and 0.674 (0.619) for valence and arousal respectively on the validation set(test set). This shows a significant improvement over the baseline of 0.240 (0.211) and 0.200 (0.191) for valence and arousal, respectively, in the validation set (test set), achieving second place in the valence-arousal challenge of the 6th Affective Behavior Analysis in-the-Wild (ABAW) competition.
4/16/2024

Audio-Visual Person Verification based on Recursive Fusion of Joint Cross-Attention
R. Gnana Praveen, Jahangir Alam
0
0
Person or identity verification has been recently gaining a lot of attention using audio-visual fusion as faces and voices share close associations with each other. Conventional approaches based on audio-visual fusion rely on score-level or early feature-level fusion techniques. Though existing approaches showed improvement over unimodal systems, the potential of audio-visual fusion for person verification is not fully exploited. In this paper, we have investigated the prospect of effectively capturing both the intra- and inter-modal relationships across audio and visual modalities, which can play a crucial role in significantly improving the fusion performance over unimodal systems. In particular, we introduce a recursive fusion of a joint cross-attentional model, where a joint audio-visual feature representation is employed in the cross-attention framework in a recursive fashion to progressively refine the feature representations that can efficiently capture the intra-and inter-modal relationships. To further enhance the audio-visual feature representations, we have also explored BLSTMs to improve the temporal modeling of audio-visual feature representations. Extensive experiments are conducted on the Voxceleb1 dataset to evaluate the proposed model. Results indicate that the proposed model shows promising improvement in fusion performance by adeptly capturing the intra-and inter-modal relationships across audio and visual modalities.
4/29/2024

Detail-Enhanced Intra- and Inter-modal Interaction for Audio-Visual Emotion Recognition
Tong Shi, Xuri Ge, Joemon M. Jose, Nicolas Pugeault, Paul Henderson
0
0
Capturing complex temporal relationships between video and audio modalities is vital for Audio-Visual Emotion Recognition (AVER). However, existing methods lack attention to local details, such as facial state changes between video frames, which can reduce the discriminability of features and thus lower recognition accuracy. In this paper, we propose a Detail-Enhanced Intra- and Inter-modal Interaction network(DE-III) for AVER, incorporating several novel aspects. We introduce optical flow information to enrich video representations with texture details that better capture facial state changes. A fusion module integrates the optical flow estimation with the corresponding video frames to enhance the representation of facial texture variations. We also design attentive intra- and inter-modal feature enhancement modules to further improve the richness and discriminability of video and audio representations. A detailed quantitative evaluation shows that our proposed model outperforms all existing methods on three benchmark datasets for both concrete and continuous emotion recognition. To encourage further research and ensure replicability, we will release our full code upon acceptance.
5/28/2024