DynaMMo: Dynamic Model Merging for Efficient Class Incremental Learning for Medical Images

0
Sign in to get full access
Overview
- This paper introduces DynaMMo, a dynamic model merging approach for efficient class incremental learning in medical image classification.
- Class incremental learning allows a model to learn new classes without forgetting previously learned ones, a key challenge in medical imaging applications.
- DynaMMo dynamically merges new and old model parameters to retain knowledge while efficiently incorporating new classes.
Plain English Explanation
Medical image classification is an important task in healthcare, but it can be challenging for AI models to learn new types of medical images without forgetting what they've learned before. DynaMMo: Dynamic Model Merging for Efficient Class Incremental Learning for Medical Images proposes a new approach called DynaMMo to address this problem.
The key idea is that when the model needs to learn new types of medical images, instead of starting from scratch, DynaMMo dynamically merges the new knowledge with what the model has already learned. This allows the model to efficiently incorporate new information without forgetting the old. The researchers show that DynaMMo outperforms other incremental learning methods on standard medical imaging benchmarks, demonstrating its potential to improve real-world medical AI systems.
Technical Explanation
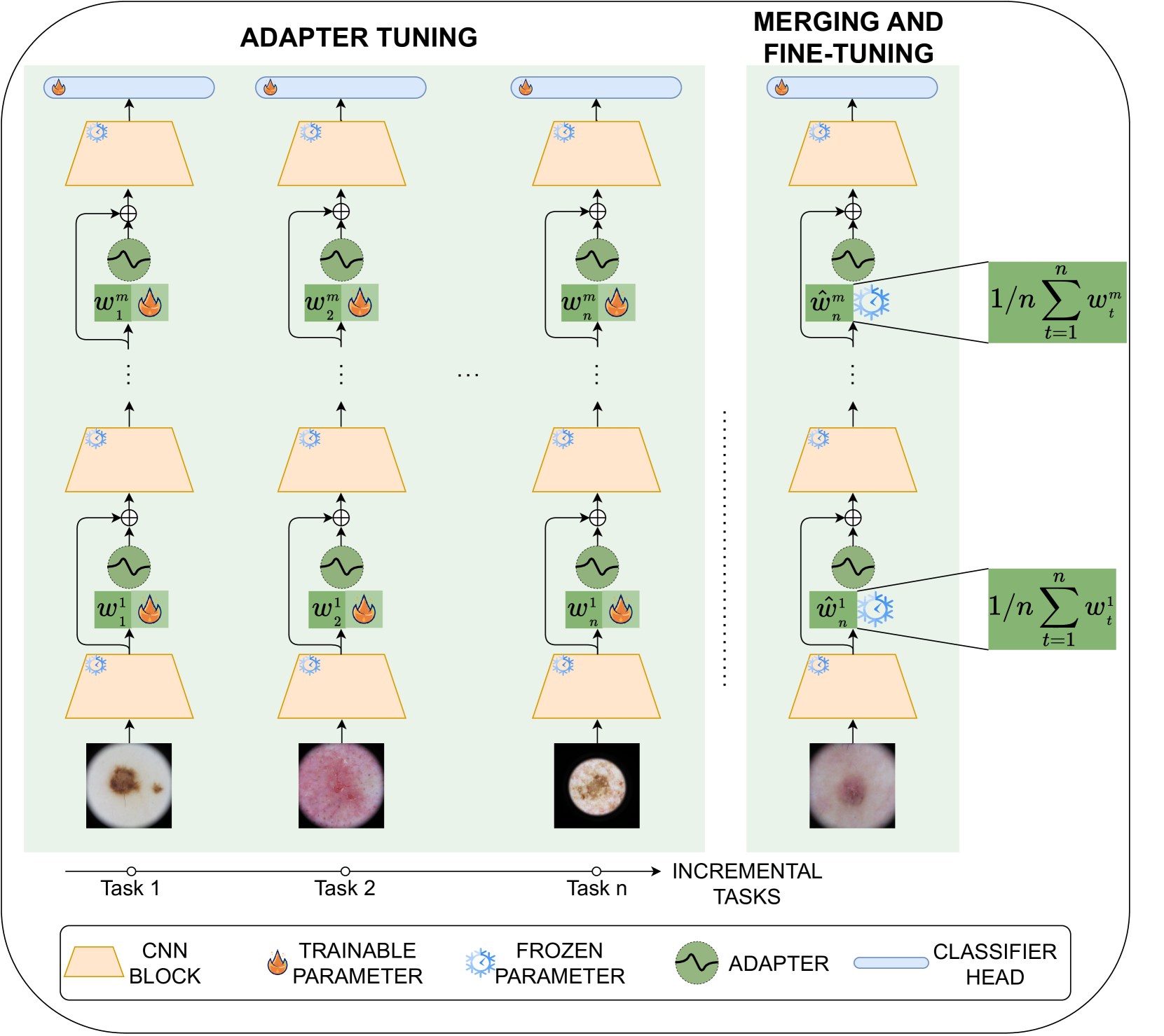
The paper introduces DynaMMo, a dynamic model merging approach for efficient class incremental learning in medical image classification. Class incremental learning is the ability to learn new classes without forgetting previously learned ones, a key challenge in medical imaging applications.
DynaMMo works by dynamically merging new and old model parameters to retain knowledge while efficiently incorporating new classes. Specifically, the model maintains two sets of parameters - a static set that encodes general image features, and a dynamic set that adapts to new classes. When a new class is introduced, DynaMMo selectively updates the dynamic parameters to learn the new class, while preserving the static parameters that encode general knowledge.
The researchers evaluate DynaMMo on standard medical imaging benchmarks, including FusionMaMba: Dynamic Feature Enhancement for Multimodal Image Fusion and Multi-Label Continual Learning in the Medical Domain: A Novel Approach. They show that DynaMMo outperforms other incremental learning methods, demonstrating its potential to improve the performance and efficiency of real-world medical AI systems.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the DynaMMo approach, including comparisons to state-of-the-art continual learning methods on challenging medical imaging benchmarks. The authors acknowledge limitations, such as the need to further investigate the impact of class imbalance and the scalability of DynaMMo to larger-scale medical datasets.
One potential concern is the reliance on a specific neural network architecture (ResNet) and training procedure. It would be valuable to see how DynaMMo performs with different model architectures and training regimes, as well as its robustness to different types of medical imaging data and tasks, such as Dynamic Pre-training: Towards Efficient and Scalable All-in-One Medical Imaging AI or Missing U: Efficient Diffusion Models for Semantic 3D Brain MRI.
Additionally, the paper does not provide much insight into the underlying mechanisms that enable DynaMMo's performance gains, such as the specific dynamics of the parameter merging process or the characteristics of the learned static and dynamic representations. Further analysis in this direction could lead to a deeper understanding of the approach and potential avenues for improvement.
Conclusion
The DynaMMo paper presents a novel and promising approach to class incremental learning for medical image classification. By dynamically merging new and old model parameters, DynaMMo can efficiently incorporate new classes while preserving previously learned knowledge. The strong performance on standard benchmarks suggests that DynaMMo could have a significant impact on the development of practical and robust medical AI systems, particularly in Conditional Diffusion Models for Semantic 3D Brain MRI and other medical imaging applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
DynaMMo: Dynamic Model Merging for Efficient Class Incremental Learning for Medical Images
Mohammad Areeb Qazi, Ibrahim Almakky, Anees Ur Rehman Hashmi, Santosh Sanjeev, Mohammad Yaqub
Continual learning, the ability to acquire knowledge from new data while retaining previously learned information, is a fundamental challenge in machine learning. Various approaches, including memory replay, knowledge distillation, model regularization, and dynamic network expansion, have been proposed to address this issue. Thus far, dynamic network expansion methods have achieved state-of-the-art performance at the cost of incurring significant computational overhead. This is due to the need for additional model buffers, which makes it less feasible in resource-constrained settings, particularly in the medical domain. To overcome this challenge, we propose Dynamic Model Merging, DynaMMo, a method that merges multiple networks at different stages of model training to achieve better computational efficiency. Specifically, we employ lightweight learnable modules for each task and combine them into a unified model to minimize computational overhead. DynaMMo achieves this without compromising performance, offering a cost-effective solution for continual learning in medical applications. We evaluate DynaMMo on three publicly available datasets, demonstrating its effectiveness compared to existing approaches. DynaMMo offers around 10-fold reduction in GFLOPS with a small drop of 2.76 in average accuracy when compared to state-of-the-art dynamic-based approaches. The code implementation of this work will be available upon the acceptance of this work at https://github.com/BioMedIA-MBZUAI/DynaMMo.
Read more4/23/2024

0
MMDRFuse: Distilled Mini-Model with Dynamic Refresh for Multi-Modality Image Fusion
Yanglin Deng, Tianyang Xu, Chunyang Cheng, Xiao-Jun Wu, Josef Kittler
In recent years, Multi-Modality Image Fusion (MMIF) has been applied to many fields, which has attracted many scholars to endeavour to improve the fusion performance. However, the prevailing focus has predominantly been on the architecture design, rather than the training strategies. As a low-level vision task, image fusion is supposed to quickly deliver output images for observation and supporting downstream tasks. Thus, superfluous computational and storage overheads should be avoided. In this work, a lightweight Distilled Mini-Model with a Dynamic Refresh strategy (MMDRFuse) is proposed to achieve this objective. To pursue model parsimony, an extremely small convolutional network with a total of 113 trainable parameters (0.44 KB) is obtained by three carefully designed supervisions. First, digestible distillation is constructed by emphasising external spatial feature consistency, delivering soft supervision with balanced details and saliency for the target network. Second, we develop a comprehensive loss to balance the pixel, gradient, and perception clues from the source images. Third, an innovative dynamic refresh training strategy is used to collaborate history parameters and current supervision during training, together with an adaptive adjust function to optimise the fusion network. Extensive experiments on several public datasets demonstrate that our method exhibits promising advantages in terms of model efficiency and complexity, with superior performance in multiple image fusion tasks and downstream pedestrian detection application. The code of this work is publicly available at https://github.com/yanglinDeng/MMDRFuse.
Read more8/29/2024

0
FusionMamba: Dynamic Feature Enhancement for Multimodal Image Fusion with Mamba
Xinyu Xie, Yawen Cui, Chio-In Ieong, Tao Tan, Xiaozhi Zhang, Xubin Zheng, Zitong Yu
Multi-modal image fusion aims to combine information from different modes to create a single image with comprehensive information and detailed textures. However, fusion models based on convolutional neural networks encounter limitations in capturing global image features due to their focus on local convolution operations. Transformer-based models, while excelling in global feature modeling, confront computational challenges stemming from their quadratic complexity. Recently, the Selective Structured State Space Model has exhibited significant potential for long-range dependency modeling with linear complexity, offering a promising avenue to address the aforementioned dilemma. In this paper, we propose FusionMamba, a novel dynamic feature enhancement method for multimodal image fusion with Mamba. Specifically, we devise an improved efficient Mamba model for image fusion, integrating efficient visual state space model with dynamic convolution and channel attention. This refined model not only upholds the performance of Mamba and global modeling capability but also diminishes channel redundancy while enhancing local enhancement capability. Additionally, we devise a dynamic feature fusion module (DFFM) comprising two dynamic feature enhancement modules (DFEM) and a cross modality fusion mamba module (CMFM). The former serves for dynamic texture enhancement and dynamic difference perception, whereas the latter enhances correlation features between modes and suppresses redundant intermodal information. FusionMamba has yielded state-of-the-art (SOTA) performance across various multimodal medical image fusion tasks (CT-MRI, PET-MRI, SPECT-MRI), infrared and visible image fusion task (IR-VIS) and multimodal biomedical image fusion dataset (GFP-PC), which is proved that our model has generalization ability. The code for FusionMamba is available at https://github.com/millieXie/FusionMamba.
Read more4/23/2024

0
Twin-Merging: Dynamic Integration of Modular Expertise in Model Merging
Zhenyi Lu, Chenghao Fan, Wei Wei, Xiaoye Qu, Dangyang Chen, Yu Cheng
In the era of large language models, model merging is a promising way to combine multiple task-specific models into a single multitask model without extra training. However, two challenges remain: (a) interference between different models and (b) heterogeneous data during testing. Traditional model merging methods often show significant performance gaps compared to fine-tuned models due to these issues. Additionally, a one-size-fits-all model lacks flexibility for diverse test data, leading to performance degradation. We show that both shared and exclusive task-specific knowledge are crucial for merging performance, but directly merging exclusive knowledge hinders overall performance. In view of this, we propose Twin-Merging, a method that encompasses two principal stages: (1) modularizing knowledge into shared and exclusive components, with compression to reduce redundancy and enhance efficiency; (2) dynamically merging shared and task-specific knowledge based on the input. This approach narrows the performance gap between merged and fine-tuned models and improves adaptability to heterogeneous data. Extensive experiments on $12$ datasets for both discriminative and generative tasks demonstrate the effectiveness of our method, showing an average improvement of $28.34%$ in absolute normalized score for discriminative tasks and even surpassing the fine-tuned upper bound on the generative tasks. (Our implementation is available in https://github.com/LZY-the-boys/Twin-Mergin.)
Read more6/26/2024