EALD-MLLM: Emotion Analysis in Long-sequential and De-identity videos with Multi-modal Large Language Model
2405.00574
0
0

Abstract
Emotion AI is the ability of computers to understand human emotional states. Existing works have achieved promising progress, but two limitations remain to be solved: 1) Previous studies have been more focused on short sequential video emotion analysis while overlooking long sequential video. However, the emotions in short sequential videos only reflect instantaneous emotions, which may be deliberately guided or hidden. In contrast, long sequential videos can reveal authentic emotions; 2) Previous studies commonly utilize various signals such as facial, speech, and even sensitive biological signals (e.g., electrocardiogram). However, due to the increasing demand for privacy, developing Emotion AI without relying on sensitive signals is becoming important. To address the aforementioned limitations, in this paper, we construct a dataset for Emotion Analysis in Long-sequential and De-identity videos called EALD by collecting and processing the sequences of athletes' post-match interviews. In addition to providing annotations of the overall emotional state of each video, we also provide the Non-Facial Body Language (NFBL) annotations for each player. NFBL is an inner-driven emotional expression and can serve as an identity-free clue to understanding the emotional state. Moreover, we provide a simple but effective baseline for further research. More precisely, we evaluate the Multimodal Large Language Models (MLLMs) with de-identification signals (e.g., visual, speech, and NFBLs) to perform emotion analysis. Our experimental results demonstrate that: 1) MLLMs can achieve comparable, even better performance than the supervised single-modal models, even in a zero-shot scenario; 2) NFBL is an important cue in long sequential emotion analysis. EALD will be available on the open-source platform.
Create account to get full access
Overview
- Introduces a novel method called EALD-MLLM for emotion analysis in long-sequential and de-identity videos using a multi-modal large language model
- Aims to address challenges in affective computing and human-computer interaction by leveraging large language models and multi-modal data
- Focuses on understanding emotions in long videos and scenarios where identity information is not available
Plain English Explanation
The paper presents a new approach called EALD-MLLM for analyzing emotions in long videos and videos where the identities of the people are hidden or removed. This is an important problem in the field of affective computing, which is the study of how computers can recognize, interpret, and respond to human emotions.
One of the key challenges in this area is dealing with long videos, where emotions can change over time. Traditional emotion recognition methods often struggle with these types of videos. The researchers behind EALD-MLLM believe that using large language models, which are powerful AI systems trained on vast amounts of text data, can help address this challenge.
Another challenge is when the identities of the people in the videos are not available, such as in situations where the faces or other identifying information has been removed or obscured. This can happen for privacy or security reasons. The EALD-MLLM approach aims to still be able to analyze emotions in these types of "de-identity" videos.
By combining large language models with multi-modal data (e.g., video, audio, and text), the researchers believe EALD-MLLM can provide more accurate and nuanced emotion analysis than previous methods. This could have important applications in areas like human-computer interaction, where understanding user emotions can help create more engaging and personalized experiences.
Technical Explanation
The EALD-MLLM approach leverages a multi-modal large language model (MLLM) to perform emotion analysis on long-sequential and de-identity videos. The researchers hypothesize that the MLLM's ability to model complex semantic and affective relationships across different modalities can lead to more accurate emotion recognition compared to traditional methods.
The proposed system takes in video, audio, and any available text data as input. It then uses the MLLM to extract relevant features and capture the temporal dynamics of the emotions expressed in the long-form video. The MLLM is trained on a diverse dataset of multimodal emotional data, allowing it to learn robust representations of emotions and their manifestations across different modalities.
To address the de-identity challenge, the EALD-MLLM approach leverages techniques for removing or obscuring identifying information while preserving the emotional cues in the video. This allows the system to analyze emotions without relying on person-specific information.
The researchers evaluate EALD-MLLM on several benchmark datasets for emotion recognition, including long-form videos and de-identity scenarios. They compare the performance of their approach to state-of-the-art methods and demonstrate significant improvements in emotion analysis accuracy, particularly for challenging long-sequential and de-identity settings.
Critical Analysis
The EALD-MLLM approach represents an important step forward in addressing the challenges of emotion analysis in long-form and de-identity videos. The researchers' use of a powerful multi-modal large language model is a promising direction, as it allows the system to capture complex emotional patterns and dynamics that may be difficult to model using traditional methods.
However, the paper does not provide a detailed analysis of the limitations of the EALD-MLLM approach. For example, it would be valuable to understand how the system performs in scenarios with noisy or incomplete data, or how it handles cultural and individual differences in emotional expression. Additionally, the paper does not discuss potential biases that may arise from the training data or the language model itself, which is an important consideration in affective computing.
Further research is also needed to explore the real-world applications and implications of the EALD-MLLM system. For instance, how might this technology be used in human-computer interaction scenarios, and what ethical considerations need to be addressed when deploying emotion recognition systems in sensitive contexts?
Overall, the EALD-MLLM approach represents a promising step forward in the field of long video understanding, but more research is needed to fully understand its limitations and potential implications.
Conclusion
The EALD-MLLM paper presents a novel method for emotion analysis in long-sequential and de-identity videos using a multi-modal large language model. This work addresses important challenges in affective computing and human-computer interaction, where traditional emotion recognition methods often struggle with long-form and identity-obscured data.
By leveraging the powerful semantic and affective modeling capabilities of large language models, the EALD-MLLM approach demonstrates significant improvements in emotion analysis accuracy compared to state-of-the-art methods. This could have important implications for a wide range of applications, from enhancing human-computer interactions to improving our understanding of human behavior and social dynamics.
However, the paper also highlights the need for further research to address the limitations and potential biases of the EALD-MLLM system. As emotion recognition technology becomes increasingly prominent, it will be crucial to consider the ethical implications and ensure that these systems are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Emotion-LLaMA: Multimodal Emotion Recognition and Reasoning with Instruction Tuning
Zebang Cheng, Zhi-Qi Cheng, Jun-Yan He, Jingdong Sun, Kai Wang, Yuxiang Lin, Zheng Lian, Xiaojiang Peng, Alexander Hauptmann
0
0
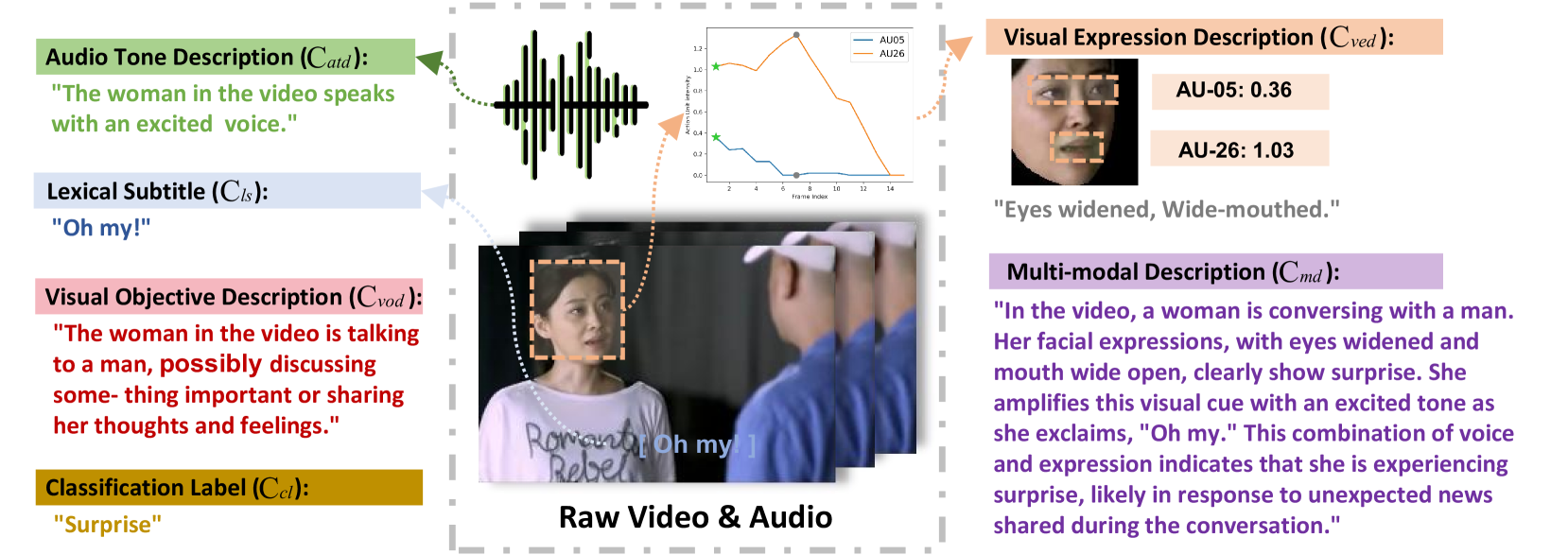
Accurate emotion perception is crucial for various applications, including human-computer interaction, education, and counseling. However, traditional single-modality approaches often fail to capture the complexity of real-world emotional expressions, which are inherently multimodal. Moreover, existing Multimodal Large Language Models (MLLMs) face challenges in integrating audio and recognizing subtle facial micro-expressions. To address this, we introduce the MERR dataset, containing 28,618 coarse-grained and 4,487 fine-grained annotated samples across diverse emotional categories. This dataset enables models to learn from varied scenarios and generalize to real-world applications. Furthermore, we propose Emotion-LLaMA, a model that seamlessly integrates audio, visual, and textual inputs through emotion-specific encoders. By aligning features into a shared space and employing a modified LLaMA model with instruction tuning, Emotion-LLaMA significantly enhances both emotional recognition and reasoning capabilities. Extensive evaluations show Emotion-LLaMA outperforms other MLLMs, achieving top scores in Clue Overlap (7.83) and Label Overlap (6.25) on EMER, an F1 score of 0.9036 on MER2023 challenge, and the highest UAR (45.59) and WAR (59.37) in zero-shot evaluations on DFEW dataset.
6/18/2024
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
0
0
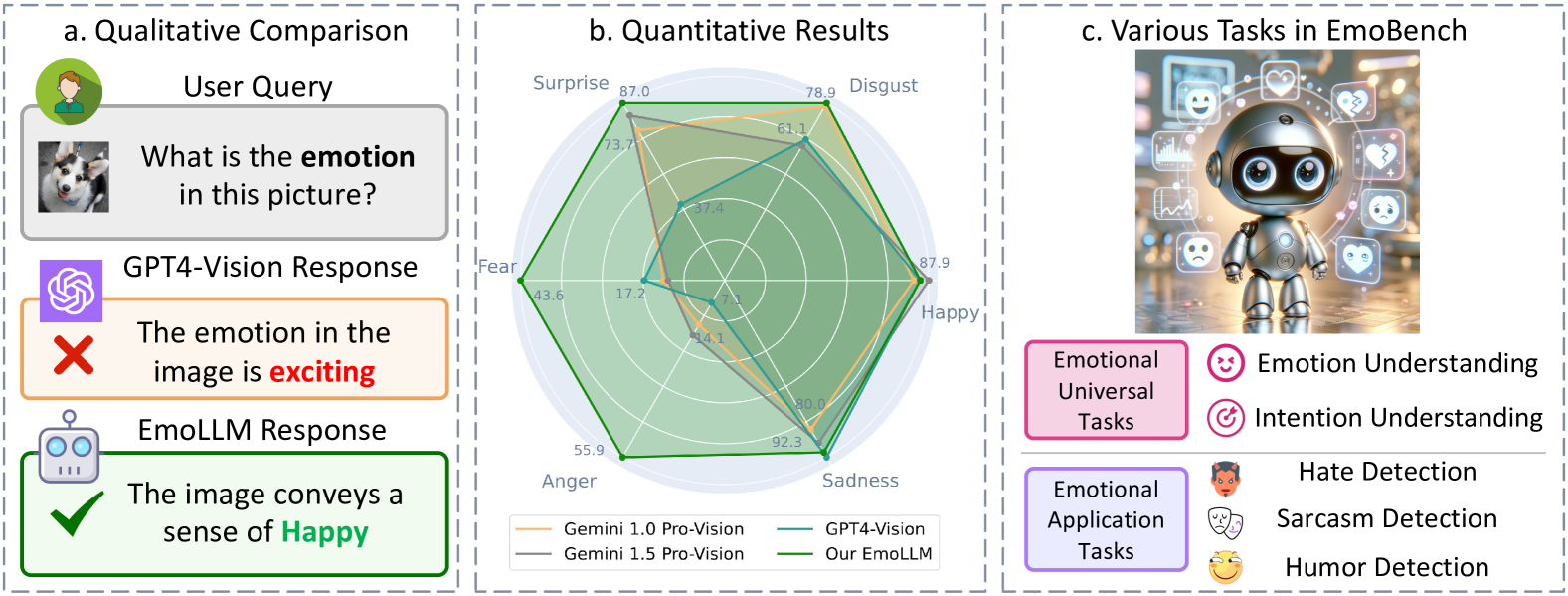
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
6/26/2024
TEII: Think, Explain, Interact and Iterate with Large Language Models to Solve Cross-lingual Emotion Detection
Long Cheng, Qihao Shao, Christine Zhao, Sheng Bi, Gina-Anne Levow
0
0
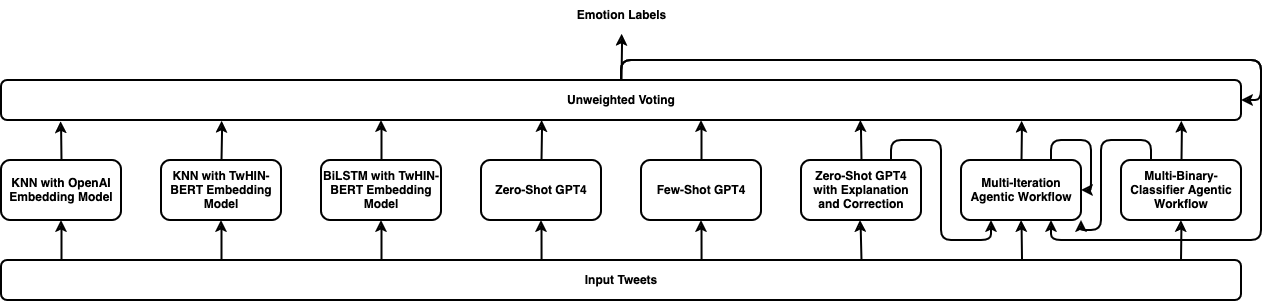
Cross-lingual emotion detection allows us to analyze global trends, public opinion, and social phenomena at scale. We participated in the Explainability of Cross-lingual Emotion Detection (EXALT) shared task, achieving an F1-score of 0.6046 on the evaluation set for the emotion detection sub-task. Our system outperformed the baseline by more than 0.16 F1-score absolute, and ranked second amongst competing systems. We conducted experiments using fine-tuning, zero-shot learning, and few-shot learning for Large Language Model (LLM)-based models as well as embedding-based BiLSTM and KNN for non-LLM-based techniques. Additionally, we introduced two novel methods: the Multi-Iteration Agentic Workflow and the Multi-Binary-Classifier Agentic Workflow. We found that LLM-based approaches provided good performance on multilingual emotion detection. Furthermore, ensembles combining all our experimented models yielded higher F1-scores than any single approach alone.
5/28/2024
💬
EmoLLMs: A Series of Emotional Large Language Models and Annotation Tools for Comprehensive Affective Analysis
Zhiwei Liu, Kailai Yang, Tianlin Zhang, Qianqian Xie, Sophia Ananiadou
0
0
Sentiment analysis and emotion detection are important research topics in natural language processing (NLP) and benefit many downstream tasks. With the widespread application of LLMs, researchers have started exploring the application of LLMs based on instruction-tuning in the field of sentiment analysis. However, these models only focus on single aspects of affective classification tasks (e.g. sentimental polarity or categorical emotions), and overlook the regression tasks (e.g. sentiment strength or emotion intensity), which leads to poor performance in downstream tasks. The main reason is the lack of comprehensive affective instruction tuning datasets and evaluation benchmarks, which cover various affective classification and regression tasks. Moreover, although emotional information is useful for downstream tasks, existing downstream datasets lack high-quality and comprehensive affective annotations. In this paper, we propose EmoLLMs, the first series of open-sourced instruction-following LLMs for comprehensive affective analysis based on fine-tuning various LLMs with instruction data, the first multi-task affective analysis instruction dataset (AAID) with 234K data samples based on various classification and regression tasks to support LLM instruction tuning, and a comprehensive affective evaluation benchmark (AEB) with 14 tasks from various sources and domains to test the generalization ability of LLMs. We propose a series of EmoLLMs by fine-tuning LLMs with AAID to solve various affective instruction tasks. We compare our model with a variety of LLMs on AEB, where our models outperform all other open-sourced LLMs, and surpass ChatGPT and GPT-4 in most tasks, which shows that the series of EmoLLMs achieve the ChatGPT-level and GPT-4-level generalization capabilities on affective analysis tasks, and demonstrates our models can be used as affective annotation tools.
6/19/2024