On Early Detection of Hallucinations in Factual Question Answering

1

Sign in to get full access
Overview
- This paper explores methods for early detection of hallucinations in factual question answering systems.
- Hallucinations refer to the generation of incorrect or nonsensical information by language models.
- The researchers propose several approaches to identify hallucinations before they are output as answers.
Plain English Explanation
The paper focuses on a critical issue with large language models - their tendency to [object Object] or generate incorrect information that appears factual. This can be particularly problematic in question answering systems, where users rely on the system to provide accurate answers.
The researchers explore ways to [object Object] in the generation process, before the incorrect information is returned as an answer. By identifying when the model is at risk of hallucinating, the system can either refine its response or provide a clear indication that it is unsure.
The approaches examined include analyzing the [object Object] to detect signs of hallucination, as well as using additional [object Object] to assess the plausibility of the generated text. The goal is to create more [object Object] that can better distinguish factual information from hallucinations.
Technical Explanation
The paper proposes several methods for early detection of hallucinations in factual question answering systems:
-
Hallucination Probability Estimation: The researchers develop a specialized model that predicts the probability of hallucination for each generated token. This allows the system to identify high-risk tokens and either refine the response or flag it as uncertain.
-
Hallucination Score Ranking: In addition to the probability estimate, the researchers create a scoring system that ranks the generated tokens based on their hallucination risk. This provides a more granular assessment of the response.
-
Hallucination Detection via Internal States: The paper explores analyzing the internal states of the language model, such as attention patterns and hidden representations, to detect signs of hallucination. This approach aims to identify hallucination at an earlier stage in the generation process.
-
Ensemble Modeling: The researchers combine multiple hallucination detection approaches, including the probability estimation and internal state analysis, to create a more robust and reliable system.
The experimental results show that these techniques can effectively identify hallucinations in factual question answering, with the ensemble model achieving the best performance. The researchers also discuss the trade-offs between detection accuracy, computational cost, and the impact on the overall system performance.
Critical Analysis
The paper presents a compelling approach to addressing the critical issue of hallucinations in large language models used for factual question answering. The proposed methods seem promising in their ability to detect hallucinations early in the generation process, which is crucial for maintaining user trust and the integrity of the system's outputs.
However, the paper does not fully address the potential limitations of these techniques. For example, the researchers do not discuss the scalability of the approaches, particularly in terms of computational resources and the impact on the overall system latency. Additionally, the paper does not explore the generalization of these methods to other types of language tasks beyond factual question answering.
Furthermore, the paper could have delved deeper into the root causes of hallucinations in language models, and whether the proposed detection methods address the underlying issues or simply provide a band-aid solution. Exploring ways to mitigate hallucinations more fundamentally, perhaps through improved model architecture or training techniques, could have provided a more holistic perspective on the problem.
Conclusion
This paper presents a valuable contribution to the ongoing efforts to address the hallucination problem in large language models used for factual question answering. The proposed detection methods, particularly the ensemble approach, demonstrate the potential to improve the reliability and trustworthiness of these systems.
While the paper does not fully explore the limitations and broader implications of the research, it highlights the importance of developing robust mechanisms to identify and handle hallucinations. As language models continue to play an increasingly prominent role in various applications, the ability to [object Object] will be crucial for ensuring the integrity and trustworthiness of the systems that rely on them.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
1
On Early Detection of Hallucinations in Factual Question Answering
Ben Snyder, Marius Moisescu, Muhammad Bilal Zafar
While large language models (LLMs) have taken great strides towards helping humans with a plethora of tasks, hallucinations remain a major impediment towards gaining user trust. The fluency and coherence of model generations even when hallucinating makes detection a difficult task. In this work, we explore if the artifacts associated with the model generations can provide hints that the generation will contain hallucinations. Specifically, we probe LLMs at 1) the inputs via Integrated Gradients based token attribution, 2) the outputs via the Softmax probabilities, and 3) the internal state via self-attention and fully-connected layer activations for signs of hallucinations on open-ended question answering tasks. Our results show that the distributions of these artifacts tend to differ between hallucinated and non-hallucinated generations. Building on this insight, we train binary classifiers that use these artifacts as input features to classify model generations into hallucinations and non-hallucinations. These hallucination classifiers achieve up to $0.80$ AUROC. We also show that tokens preceding a hallucination can already predict the subsequent hallucination even before it occurs.
Read more8/23/2024
0
On Large Language Models' Hallucination with Regard to Known Facts
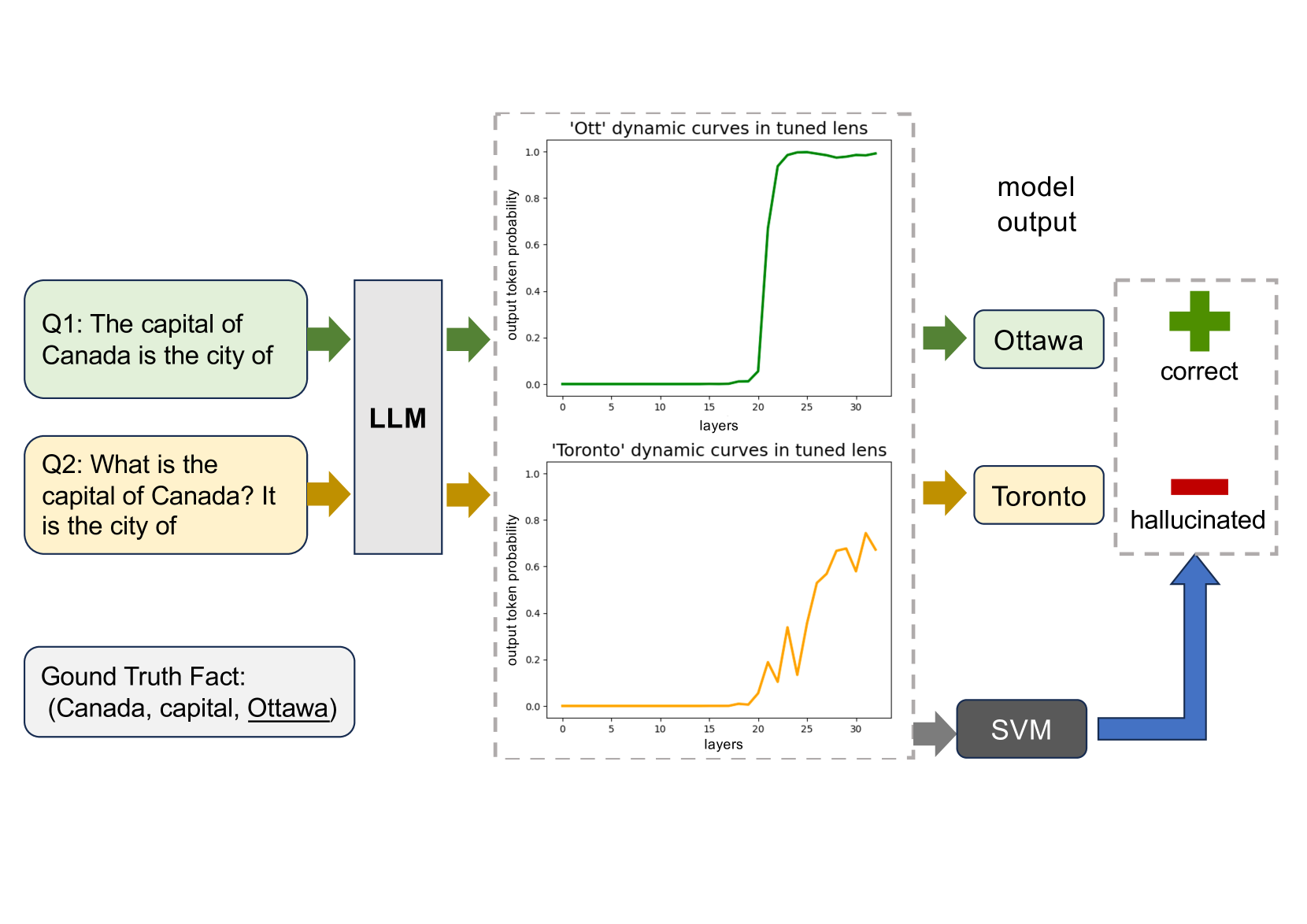
Che Jiang, Biqing Qi, Xiangyu Hong, Dayuan Fu, Yang Cheng, Fandong Meng, Mo Yu, Bowen Zhou, Jie Zhou
Large language models are successful in answering factoid questions but are also prone to hallucination.We investigate the phenomenon of LLMs possessing correct answer knowledge yet still hallucinating from the perspective of inference dynamics, an area not previously covered in studies on hallucinations.We are able to conduct this analysis via two key ideas.First, we identify the factual questions that query the same triplet knowledge but result in different answers. The difference between the model behaviors on the correct and incorrect outputs hence suggests the patterns when hallucinations happen. Second, to measure the pattern, we utilize mappings from the residual streams to vocabulary space. We reveal the different dynamics of the output token probabilities along the depths of layers between the correct and hallucinated cases. In hallucinated cases, the output token's information rarely demonstrates abrupt increases and consistent superiority in the later stages of the model. Leveraging the dynamic curve as a feature, we build a classifier capable of accurately detecting hallucinatory predictions with an 88% success rate. Our study shed light on understanding the reasons for LLMs' hallucinations on their known facts, and more importantly, on accurately predicting when they are hallucinating.
Read more4/1/2024
💬
0
Towards Reliable Medical Question Answering: Techniques and Challenges in Mitigating Hallucinations in Language Models
Duy Khoa Pham, Bao Quoc Vo
The rapid advancement of large language models (LLMs) has significantly impacted various domains, including healthcare and biomedicine. However, the phenomenon of hallucination, where LLMs generate outputs that deviate from factual accuracy or context, poses a critical challenge, especially in high-stakes domains. This paper conducts a scoping study of existing techniques for mitigating hallucinations in knowledge-based task in general and especially for medical domains. Key methods covered in the paper include Retrieval-Augmented Generation (RAG)-based techniques, iterative feedback loops, supervised fine-tuning, and prompt engineering. These techniques, while promising in general contexts, require further adaptation and optimization for the medical domain due to its unique demands for up-to-date, specialized knowledge and strict adherence to medical guidelines. Addressing these challenges is crucial for developing trustworthy AI systems that enhance clinical decision-making and patient safety as well as accuracy of biomedical scientific research.
Read more8/27/2024

0
Cost-Effective Hallucination Detection for LLMs
Simon Valentin, Jinmiao Fu, Gianluca Detommaso, Shaoyuan Xu, Giovanni Zappella, Bryan Wang
Large language models (LLMs) can be prone to hallucinations - generating unreliable outputs that are unfaithful to their inputs, external facts or internally inconsistent. In this work, we address several challenges for post-hoc hallucination detection in production settings. Our pipeline for hallucination detection entails: first, producing a confidence score representing the likelihood that a generated answer is a hallucination; second, calibrating the score conditional on attributes of the inputs and candidate response; finally, performing detection by thresholding the calibrated score. We benchmark a variety of state-of-the-art scoring methods on different datasets, encompassing question answering, fact checking, and summarization tasks. We employ diverse LLMs to ensure a comprehensive assessment of performance. We show that calibrating individual scoring methods is critical for ensuring risk-aware downstream decision making. Based on findings that no individual score performs best in all situations, we propose a multi-scoring framework, which combines different scores and achieves top performance across all datasets. We further introduce cost-effective multi-scoring, which can match or even outperform more expensive detection methods, while significantly reducing computational overhead.
Read more8/12/2024