Early-exit Convolutional Neural Networks

0
Sign in to get full access
Overview
- Early-exit convolutional neural networks (CNNs) are a type of deep learning model that can terminate the inference process early for some inputs, improving efficiency.
- The key idea is to add multiple exit points in the CNN, allowing the model to exit and produce a prediction as soon as it is confident enough, without running the full network.
- This can lead to significant computational savings for easy-to-classify inputs, while maintaining high accuracy for more challenging inputs.
Plain English Explanation
Early-exit CNNs are a clever way to make deep learning models more efficient. Typical deep learning models, like CNNs, run all the way through a complex neural network to make a prediction. But the authors of this paper wondered, "Do we really need to run the full network for every single input?"
The insight is that some inputs are easier to classify than others. For simple inputs, the model can often make an accurate prediction after just a few layers of the network. So why waste computational resources running the entire network?
To address this, the researchers added "exit points" at different layers of the CNN. This allows the model to stop early and provide a prediction as soon as it's confident enough, without needing to run the full network. This can save a lot of computation for easy-to-classify inputs, while still maintaining high accuracy overall.
It's kind of like having a fast lane at a toll booth. Drivers who are ready to pay can exit quickly, while those who need more processing time can continue through the full lane. This early-exit approach makes the deep learning model more efficient and flexible.
Technical Explanation
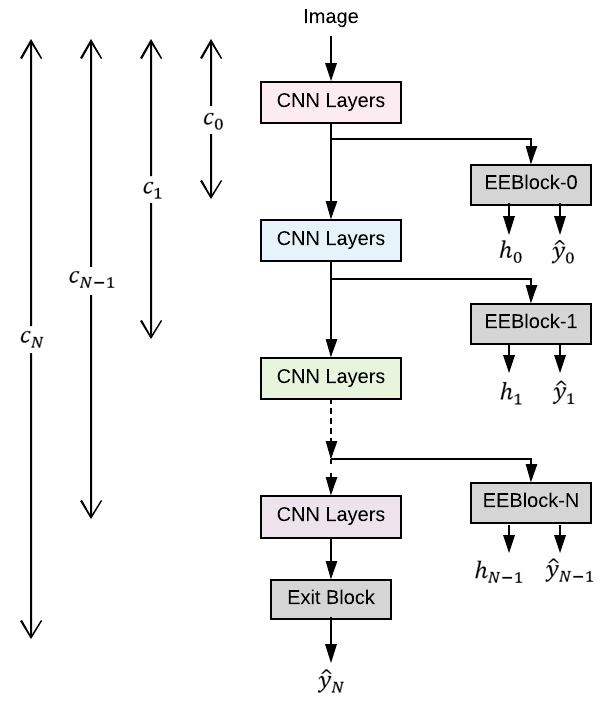
Early-exit CNNs work by adding multiple classification layers, or "exit points," at different depths of the convolutional neural network. During inference, the model can choose to exit and provide a prediction at any of these intermediate layers, rather than always running the full network.
The key components are:
- Exit Classifiers: Additional fully-connected layers are added after various convolutional blocks, which can independently classify the input.
- Confidence Estimation: The model estimates its confidence in the prediction at each exit point, using techniques like temperature scaling.
- Early Exiting: At inference time, the model continuously evaluates its confidence. As soon as the confidence exceeds a predefined threshold, the model exits and returns the prediction, without running the full network.
This allows the model to adaptively determine the optimal depth required for each input, saving computation for easy-to-classify examples while maintaining high overall accuracy. The authors demonstrate this approach on standard CNN architectures like ResNet and MobileNet, achieving substantial inference speedups with minimal accuracy degradation.
Critical Analysis
The early-exit CNN approach is a clever and promising technique for improving the efficiency of deep learning models. By allowing the model to exit early when confident, it can achieve significant computational savings without sacrificing too much accuracy.
However, the paper does not explore some potential limitations and caveats:
- The method relies on accurately estimating the model's confidence, which can be challenging, especially for edge cases or out-of-distribution inputs.
- There may be architectural constraints or tradeoffs in terms of model size and complexity when adding multiple exit classifiers.
- The optimal early-exit thresholds may depend on the specific task, dataset, and deployment constraints, requiring careful tuning.
- The paper only evaluates this approach on standard image classification benchmarks - further research is needed to see how it performs on more diverse or real-world applications.
Despite these potential issues, the core idea of early exiting is compelling and warrants further exploration. Researchers and practitioners should think critically about the limitations and consider ways to address them, to unlock the full potential of this efficient deep learning technique.
Conclusion
Early-exit CNNs present an innovative approach to improving the efficiency of deep learning models by allowing them to exit and provide a prediction as soon as they are confident, without running the full network.
This can lead to significant computational savings for easy-to-classify inputs, while maintaining high overall accuracy. The key technical components are the addition of multiple exit classifiers, confidence estimation, and dynamic early exiting during inference.
While the paper demonstrates promising results on standard benchmarks, further research is needed to explore the limitations and potential tradeoffs of this approach, as well as its applicability to more diverse real-world scenarios. Nonetheless, the core concept of early exiting is a compelling direction for making deep learning models more efficient and accessible, with wide-ranging implications for a variety of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Early-exit Convolutional Neural Networks
Edanur Demir, Emre Akbas
This paper is aimed at developing a method that reduces the computational cost of convolutional neural networks (CNN) during inference. Conventionally, the input data pass through a fixed neural network architecture. However, easy examples can be classified at early stages of processing and conventional networks do not take this into account. In this paper, we introduce 'Early-exit CNNs', EENets for short, which adapt their computational cost based on the input by stopping the inference process at certain exit locations. In EENets, there are a number of exit blocks each of which consists of a confidence branch and a softmax branch. The confidence branch computes the confidence score of exiting (i.e. stopping the inference process) at that location; while the softmax branch outputs a classification probability vector. Both branches are learnable and their parameters are separate. During training of EENets, in addition to the classical classification loss, the computational cost of inference is taken into account as well. As a result, the network adapts its many confidence branches to the inputs so that less computation is spent for easy examples. Inference works as in conventional feed-forward networks, however, when the output of a confidence branch is larger than a certain threshold, the inference stops for that specific example. The idea of EENets is applicable to available CNN architectures such as ResNets. Through comprehensive experiments on MNIST, SVHN, CIFAR10 and Tiny-ImageNet datasets, we show that early-exit (EE) ResNets achieve similar accuracy with their non-EE versions while reducing the computational cost to 20% of the original. Code is available at https://github.com/eksuas/eenets.pytorch
Read more9/10/2024

0
Fast yet Safe: Early-Exiting with Risk Control
Metod Jazbec, Alexander Timans, Tin Hadv{z}i Veljkovi'c, Kaspar Sakmann, Dan Zhang, Christian A. Naesseth, Eric Nalisnick
Scaling machine learning models significantly improves their performance. However, such gains come at the cost of inference being slow and resource-intensive. Early-exit neural networks (EENNs) offer a promising solution: they accelerate inference by allowing intermediate layers to exit and produce a prediction early. Yet a fundamental issue with EENNs is how to determine when to exit without severely degrading performance. In other words, when is it 'safe' for an EENN to go 'fast'? To address this issue, we investigate how to adapt frameworks of risk control to EENNs. Risk control offers a distribution-free, post-hoc solution that tunes the EENN's exiting mechanism so that exits only occur when the output is of sufficient quality. We empirically validate our insights on a range of vision and language tasks, demonstrating that risk control can produce substantial computational savings, all the while preserving user-specified performance goals.
Read more6/3/2024
🏋️
0
Hierarchical Training of Deep Neural Networks Using Early Exiting
Yamin Sepehri, Pedram Pad, Ahmet Caner Yuzuguler, Pascal Frossard, L. Andrea Dunbar
Deep neural networks provide state-of-the-art accuracy for vision tasks but they require significant resources for training. Thus, they are trained on cloud servers far from the edge devices that acquire the data. This issue increases communication cost, runtime and privacy concerns. In this study, a novel hierarchical training method for deep neural networks is proposed that uses early exits in a divided architecture between edge and cloud workers to reduce the communication cost, training runtime and privacy concerns. The method proposes a brand-new use case for early exits to separate the backward pass of neural networks between the edge and the cloud during the training phase. We address the issues of most available methods that due to the sequential nature of the training phase, cannot train the levels of hierarchy simultaneously or they do it with the cost of compromising privacy. In contrast, our method can use both edge and cloud workers simultaneously, does not share the raw input data with the cloud and does not require communication during the backward pass. Several simulations and on-device experiments for different neural network architectures demonstrate the effectiveness of this method. It is shown that the proposed method reduces the training runtime for VGG-16 and ResNet-18 architectures by 29% and 61% in CIFAR-10 classification and by 25% and 81% in Tiny ImageNet classification when the communication with the cloud is done over a low bit rate channel. This gain in the runtime is achieved whilst the accuracy drop is negligible. This method is advantageous for online learning of high-accuracy deep neural networks on sensor-holding low-resource devices such as mobile phones or robots as a part of an edge-cloud system, making them more flexible in facing new tasks and classes of data.
Read more5/22/2024
🤯
0
Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN
Florence Regol, Joud Chataoui, Mark Coates
Large pretrained models, coupled with fine-tuning, are slowly becoming established as the dominant architecture in machine learning. Even though these models offer impressive performance, their practical application is often limited by the prohibitive amount of resources required for every inference. Early-exiting dynamic neural networks (EDNN) circumvent this issue by allowing a model to make some of its predictions from intermediate layers (i.e., early-exit). Training an EDNN architecture is challenging as it consists of two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations. As a result, most existing approaches rely on thresholding confidence metrics for the gating mechanism and strive to improve the underlying backbone network and the inference modules. Although successful, this approach has two fundamental shortcomings: 1) the GMs and the IMs are decoupled during training, leading to a train-test mismatch; and 2) the thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to readily extract uncertainty information. We propose a novel architecture that connects these two modules. This leads to significant performance improvements on classification datasets and enables better uncertainty characterization capabilities.
Read more5/13/2024