Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN

0
🤯
Sign in to get full access
Overview
- Large pretrained models with fine-tuning have become the dominant architecture in machine learning.
- These models offer impressive performance, but their practical application is often limited by the high resource requirements for inference.
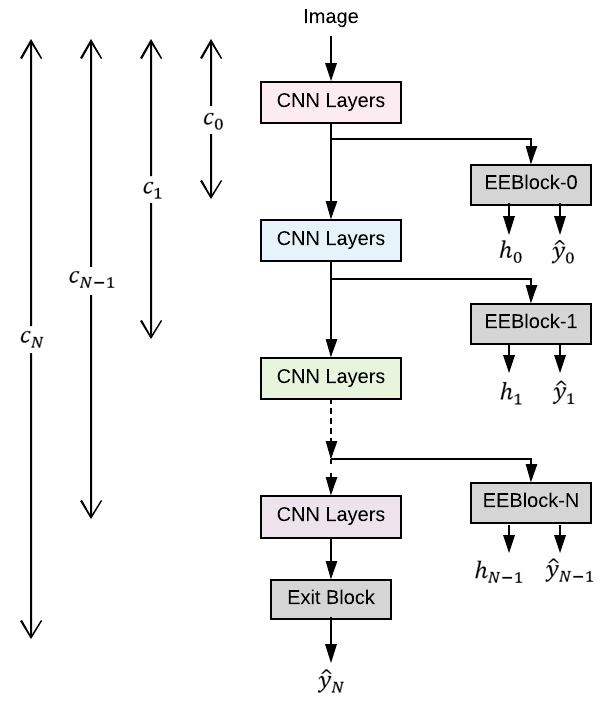
- Early-exiting dynamic neural networks (EDNN) aim to address this by allowing the model to make some predictions from intermediate layers (early-exit).
- Training an EDNN is challenging as it involves two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations.
Plain English Explanation
Large language models like GPT-3 have become very powerful at tasks like generating human-like text. However, using these models for real-world applications can be expensive and resource-intensive because they require a lot of computing power to make predictions (known as "inference").
To address this issue, researchers have developed a new type of neural network called an early-exiting dynamic neural network (EDNN). EDNNs are designed to be more efficient by allowing the model to make some of its predictions using intermediate layers, rather than always running the full model.
This works by having two key components: a gating mechanism (GM) that decides when the model should exit early, and intermediate inference modules (IMs) that can make predictions from the intermediate layers. The challenge is that training these two components together is difficult, as they are strongly connected.
Most existing approaches try to improve the individual components, like making the backbone network better or fine-tuning the gating mechanism. However, this can lead to issues where the training and testing of the model don't quite match up, and it can also make it hard to get reliable uncertainty information from the model's predictions.
The paper proposes a new architecture that better connects the gating mechanism and inference modules during training. This leads to significant performance improvements on classification tasks and also allows the model to provide better estimates of its own uncertainty.
Technical Explanation
The key technical innovation in this paper is a novel architecture for training early-exiting dynamic neural networks (EDNNs) that better integrates the gating mechanism (GM) and intermediate inference modules (IMs).
Most existing approaches to training EDNNs rely on thresholding confidence metrics for the gating mechanism, while trying to improve the underlying backbone network and the inference modules. However, this has two main shortcomings:
- The GMs and IMs are decoupled during training, leading to a "train-test mismatch" where the model behaves differently at inference time compared to how it was trained.
- The thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to reliably extract uncertainty information.
To address these issues, the proposed architecture tightly couples the GM and IM components during training. Specifically, the GM is trained to minimize the difference between the early-exiting prediction and the final model prediction, rather than relying on confidence thresholds.
This approach leads to several key benefits:
- Improved performance: The authors show significant accuracy improvements on standard classification benchmarks compared to previous EDNN methods.
- Better uncertainty characterization: The tight coupling between GM and IM allows the model to provide more reliable estimates of its own uncertainty, which is important for many real-world applications.
The technical details of the architecture and training process are described in depth in the paper, including the specific loss functions and optimization procedures used.
Critical Analysis
The proposed EDNN architecture represents an interesting and potentially impactful advance in the field of dynamic neural networks. By more tightly integrating the gating mechanism and inference modules, the authors are able to address some of the key limitations of prior EDNN approaches.
That said, the paper does not explore some potential caveats and limitations of the proposed method:
- Computational overhead: While the early-exiting mechanism aims to reduce inference costs, the tight coupling between GM and IM may introduce additional computational overhead during training. The authors do not provide a detailed analysis of the training time or memory requirements.
- Generalization to other tasks: The experiments in the paper are limited to image classification tasks. It's unclear how well the approach would generalize to other domains, such as natural language processing or graph-based learning.
- Robustness and out-of-distribution performance: The paper does not examine how the EDNN model might behave on data that deviates from the training distribution, which is an important consideration for real-world deployment.
Overall, the proposed EDNN architecture represents a promising step forward, but further research is needed to fully understand its capabilities, limitations, and potential impact on the field of efficient deep learning.
Conclusion
This paper introduces a novel architecture for training early-exiting dynamic neural networks (EDNNs) that better integrates the gating mechanism (GM) and intermediate inference modules (IMs). By tightly coupling these two components during training, the authors are able to achieve significant performance improvements on classification tasks while also enabling better uncertainty characterization capabilities.
The key innovation is moving away from the traditional confidence thresholding approach for the gating mechanism, and instead training the GM to minimize the difference between early-exiting and final model predictions. This helps to address the "train-test mismatch" and positive bias issues that have plagued previous EDNN methods.
While the paper demonstrates the potential of this approach, further research is needed to fully understand its limitations and generalization capabilities. Nonetheless, this work represents an important step forward in the development of efficient and reliable deep learning models for real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Jointly-Learned Exit and Inference for a Dynamic Neural Network : JEI-DNN
Florence Regol, Joud Chataoui, Mark Coates
Large pretrained models, coupled with fine-tuning, are slowly becoming established as the dominant architecture in machine learning. Even though these models offer impressive performance, their practical application is often limited by the prohibitive amount of resources required for every inference. Early-exiting dynamic neural networks (EDNN) circumvent this issue by allowing a model to make some of its predictions from intermediate layers (i.e., early-exit). Training an EDNN architecture is challenging as it consists of two intertwined components: the gating mechanism (GM) that controls early-exiting decisions and the intermediate inference modules (IMs) that perform inference from intermediate representations. As a result, most existing approaches rely on thresholding confidence metrics for the gating mechanism and strive to improve the underlying backbone network and the inference modules. Although successful, this approach has two fundamental shortcomings: 1) the GMs and the IMs are decoupled during training, leading to a train-test mismatch; and 2) the thresholding gating mechanism introduces a positive bias into the predictive probabilities, making it difficult to readily extract uncertainty information. We propose a novel architecture that connects these two modules. This leads to significant performance improvements on classification datasets and enables better uncertainty characterization capabilities.
Read more5/13/2024

0
Early-Exit meets Model-Distributed Inference at Edge Networks
Marco Colocrese, Erdem Koyuncu, Hulya Seferoglu
Distributed inference techniques can be broadly classified into data-distributed and model-distributed schemes. In data-distributed inference (DDI), each worker carries the entire deep neural network (DNN) model but processes only a subset of the data. However, feeding the data to workers results in high communication costs, especially when the data is large. An emerging paradigm is model-distributed inference (MDI), where each worker carries only a subset of DNN layers. In MDI, a source device that has data processes a few layers of DNN and sends the output to a neighboring device, i.e., offloads the rest of the layers. This process ends when all layers are processed in a distributed manner. In this paper, we investigate the design and development of MDI with early-exit, which advocates that there is no need to process all the layers of a model for some data to reach the desired accuracy, i.e., we can exit the model without processing all the layers if target accuracy is reached. We design a framework MDI-Exit that adaptively determines early-exit and offloading policies as well as data admission at the source. Experimental results on a real-life testbed of NVIDIA Nano edge devices show that MDI-Exit processes more data when accuracy is fixed and results in higher accuracy for the fixed data rate.
Read more8/13/2024
0
Early-exit Convolutional Neural Networks
Edanur Demir, Emre Akbas
This paper is aimed at developing a method that reduces the computational cost of convolutional neural networks (CNN) during inference. Conventionally, the input data pass through a fixed neural network architecture. However, easy examples can be classified at early stages of processing and conventional networks do not take this into account. In this paper, we introduce 'Early-exit CNNs', EENets for short, which adapt their computational cost based on the input by stopping the inference process at certain exit locations. In EENets, there are a number of exit blocks each of which consists of a confidence branch and a softmax branch. The confidence branch computes the confidence score of exiting (i.e. stopping the inference process) at that location; while the softmax branch outputs a classification probability vector. Both branches are learnable and their parameters are separate. During training of EENets, in addition to the classical classification loss, the computational cost of inference is taken into account as well. As a result, the network adapts its many confidence branches to the inputs so that less computation is spent for easy examples. Inference works as in conventional feed-forward networks, however, when the output of a confidence branch is larger than a certain threshold, the inference stops for that specific example. The idea of EENets is applicable to available CNN architectures such as ResNets. Through comprehensive experiments on MNIST, SVHN, CIFAR10 and Tiny-ImageNet datasets, we show that early-exit (EE) ResNets achieve similar accuracy with their non-EE versions while reducing the computational cost to 20% of the original. Code is available at https://github.com/eksuas/eenets.pytorch
Read more9/10/2024

0
Joint or Disjoint: Mixing Training Regimes for Early-Exit Models
Bart{l}omiej Krzepkowski, Monika Michaluk, Franciszek Szarwacki, Piotr Kubaty, Jary Pomponi, Tomasz Trzci'nski, Bartosz W'ojcik, Kamil Adamczewski
Early exits are an important efficiency mechanism integrated into deep neural networks that allows for the termination of the network's forward pass before processing through all its layers. By allowing early halting of the inference process for less complex inputs that reached high confidence, early exits significantly reduce the amount of computation required. Early exit methods add trainable internal classifiers which leads to more intricacy in the training process. However, there is no consistent verification of the approaches of training of early exit methods, and no unified scheme of training such models. Most early exit methods employ a training strategy that either simultaneously trains the backbone network and the exit heads or trains the exit heads separately. We propose a training approach where the backbone is initially trained on its own, followed by a phase where both the backbone and the exit heads are trained together. Thus, we advocate for organizing early-exit training strategies into three distinct categories, and then validate them for their performance and efficiency. In this benchmark, we perform both theoretical and empirical analysis of early-exit training regimes. We study the methods in terms of information flow, loss landscape and numerical rank of activations and gauge the suitability of regimes for various architectures and datasets.
Read more7/22/2024