EchoSight: Advancing Visual-Language Models with Wiki Knowledge

0

Sign in to get full access
Overview
- This paper introduces EchoSight, a novel approach to advancing visual-language models by leveraging knowledge from Wikipedia.
- EchoSight aims to enhance the performance of visual-language models on various tasks, including visual question answering, by incorporating relevant background knowledge from Wikipedia.
- The paper presents the technical details of the EchoSight model and its evaluation on multiple benchmark datasets, demonstrating its effectiveness in improving the state-of-the-art in visual-language understanding.
Plain English Explanation
EchoSight is a new way of improving visual-language models, which are AI systems that can understand and process both images and text. The key idea behind EchoSight is to give these models access to a vast amount of information from Wikipedia, the online encyclopedia. By tapping into this knowledge, the models can become better at tasks like answering questions about images.
Imagine you're looking at a picture of a famous landmark, like the Eiffel Tower in Paris. A visual-language model might be able to recognize the Eiffel Tower, but it might not know much about the history or significance of this landmark. With EchoSight, the model can draw upon the wealth of information about the Eiffel Tower available on Wikipedia, such as when it was built, who designed it, and why it's an important symbol of France. This additional knowledge can help the model better understand the context and provide more informative and accurate answers to questions about the image.
The researchers behind EchoSight have developed a technical approach to integrate this Wikipedia knowledge into the visual-language models, and they've tested it on various benchmarks to demonstrate its effectiveness. By bridging the gap between visual understanding and broad, contextual knowledge, EchoSight represents an important step forward in the field of visual-language models.
Technical Explanation
The core of the EchoSight approach is to augment existing visual-language models with knowledge from Wikipedia. The researchers first build a knowledge base by extracting relevant information from Wikipedia, including textual descriptions, images, and entity relationships. They then integrate this knowledge into the visual-language model through a multi-task training process, where the model is trained not only on the primary task (e.g., visual question answering) but also on related tasks that leverage the Wikipedia knowledge.
Specifically, the EchoSight model consists of two main components: a vision-language encoder and a knowledge-aware reasoning module. The vision-language encoder takes in both the image and the question, and produces a joint representation. The knowledge-aware reasoning module then retrieves relevant information from the Wikipedia knowledge base and uses it to enhance the model's understanding and generate more informed answers.
The researchers evaluate EchoSight on several benchmark datasets for visual question answering, including CLEVR, VQAv2, and NLVR2. The results show that EchoSight outperforms state-of-the-art visual-language models on these tasks, demonstrating the value of incorporating broad, contextual knowledge from sources like Wikipedia.
Critical Analysis
The EchoSight paper presents a compelling approach to enhancing visual-language models, but it also acknowledges several limitations and areas for further research. One key limitation is the reliance on Wikipedia as the sole knowledge source. While Wikipedia is a vast and comprehensive resource, it may not cover all the relevant background knowledge needed for certain types of images or questions.
Additionally, the paper does not deeply explore the potential biases or inaccuracies that may be present in the Wikipedia data, and how these might affect the performance of the EchoSight model. Further research could investigate ways to identify and mitigate such issues, perhaps by incorporating additional knowledge sources or developing more sophisticated techniques for knowledge curation and integration.
Another area for potential improvement is the model's ability to reason about and apply the retrieved knowledge in a more flexible and contextual manner. The current approach relies on a specific knowledge-aware reasoning module, which may limit the model's ability to dynamically combine and reason with the retrieved information. Exploring alternative knowledge integration or reasoning approaches could lead to further advancements in the field.
Conclusion
The EchoSight paper presents a promising step forward in the development of visual-language models by leveraging knowledge from Wikipedia. By incorporating broad, contextual information into these models, the researchers have demonstrated significant improvements in visual question answering and related tasks. While the current approach has some limitations, the overall concept of bridging the gap between visual understanding and broad, external knowledge represents an important direction for the field of visual-language AI.
As visual-language models continue to advance, the ability to seamlessly integrate and reason with diverse sources of information will be crucial for achieving human-like understanding and reasoning capabilities. The EchoSight paper serves as an inspiring example of how to leverage the wealth of knowledge available on the internet to push the boundaries of what is possible in the world of visual-language AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
EchoSight: Advancing Visual-Language Models with Wiki Knowledge
Yibin Yan, Weidi Xie
Knowledge-based Visual Question Answering (KVQA) tasks require answering questions about images using extensive background knowledge. Despite significant advancements, generative models often struggle with these tasks due to the limited integration of external knowledge. In this paper, we introduce EchoSight, a novel multimodal Retrieval-Augmented Generation (RAG) framework that enables large language models (LLMs) to answer visual questions requiring fine-grained encyclopedic knowledge. To strive for high-performing retrieval, EchoSight first searches wiki articles by using visual-only information, subsequently, these candidate articles are further reranked according to their relevance to the combined text-image query. This approach significantly improves the integration of multimodal knowledge, leading to enhanced retrieval outcomes and more accurate VQA responses. Our experimental results on the Encyclopedic VQA and InfoSeek datasets demonstrate that EchoSight establishes new state-of-the-art results in knowledge-based VQA, achieving an accuracy of 41.8% on Encyclopedic VQA and 31.3% on InfoSeek.
Read more7/18/2024

0
Precision Empowers, Excess Distracts: Visual Question Answering With Dynamically Infused Knowledge In Language Models
Manas Jhalani, Annervaz K M, Pushpak Bhattacharyya
In the realm of multimodal tasks, Visual Question Answering (VQA) plays a crucial role by addressing natural language questions grounded in visual content. Knowledge-Based Visual Question Answering (KBVQA) advances this concept by adding external knowledge along with images to respond to questions. We introduce an approach for KBVQA, augmenting the existing vision-language transformer encoder-decoder (OFA) model. Our main contribution involves enhancing questions by incorporating relevant external knowledge extracted from knowledge graphs, using a dynamic triple extraction method. We supply a flexible number of triples from the knowledge graph as context, tailored to meet the requirements for answering the question. Our model, enriched with knowledge, demonstrates an average improvement of 4.75% in Exact Match Score over the state-of-the-art on three different KBVQA datasets. Through experiments and analysis, we demonstrate that furnishing variable triples for each question improves the reasoning capabilities of the language model in contrast to supplying a fixed number of triples. This is illustrated even for recent large language models. Additionally, we highlight the model's generalization capability by showcasing its SOTA-beating performance on a small dataset, achieved through straightforward fine-tuning.
Read more6/17/2024

0
Visual Haystacks: Answering Harder Questions About Sets of Images
Tsung-Han Wu, Giscard Biamby, Jerome Quenum, Ritwik Gupta, Joseph E. Gonzalez, Trevor Darrell, David M. Chan
Recent advancements in Large Multimodal Models (LMMs) have made significant progress in the field of single-image visual question answering. However, these models face substantial challenges when tasked with queries that span extensive collections of images, similar to real-world scenarios like searching through large photo albums, finding specific information across the internet, or monitoring environmental changes through satellite imagery. This paper explores the task of Multi-Image Visual Question Answering (MIQA): given a large set of images and a natural language query, the task is to generate a relevant and grounded response. We propose a new public benchmark, dubbed Visual Haystacks (VHs), specifically designed to evaluate LMMs' capabilities in visual retrieval and reasoning over sets of unrelated images, where we perform comprehensive evaluations demonstrating that even robust closed-source models struggle significantly. Towards addressing these shortcomings, we introduce MIRAGE (Multi-Image Retrieval Augmented Generation), a novel retrieval/QA framework tailored for LMMs that confronts the challenges of MIQA with marked efficiency and accuracy improvements over baseline methods. Our evaluation shows that MIRAGE surpasses closed-source GPT-4o models by up to 11% on the VHs benchmark and offers up to 3.4x improvements in efficiency over text-focused multi-stage approaches.
Read more7/19/2024
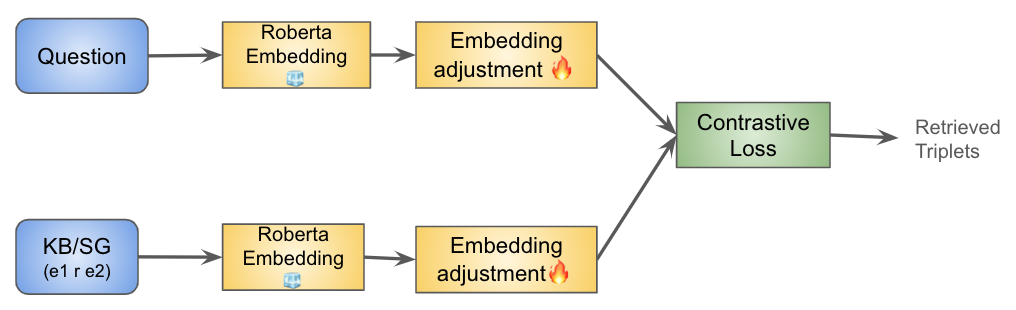
0
Find The Gap: Knowledge Base Reasoning For Visual Question Answering
Elham J. Barezi, Parisa Kordjamshidi
We analyze knowledge-based visual question answering, for which given a question, the models need to ground it into the visual modality and retrieve the relevant knowledge from a given large knowledge base (KB) to be able to answer. Our analysis has two folds, one based on designing neural architectures and training them from scratch, and another based on large pre-trained language models (LLMs). Our research questions are: 1) Can we effectively augment models by explicit supervised retrieval of the relevant KB information to solve the KB-VQA problem? 2) How do task-specific and LLM-based models perform in the integration of visual and external knowledge, and multi-hop reasoning over both sources of information? 3) Is the implicit knowledge of LLMs sufficient for KB-VQA and to what extent it can replace the explicit KB? Our results demonstrate the positive impact of empowering task-specific and LLM models with supervised external and visual knowledge retrieval models. Our findings show that though LLMs are stronger in 1-hop reasoning, they suffer in 2-hop reasoning in comparison with our fine-tuned NN model even if the relevant information from both modalities is available to the model. Moreover, we observed that LLM models outperform the NN model for KB-related questions which confirms the effectiveness of implicit knowledge in LLMs however, they do not alleviate the need for external KB.
Read more4/17/2024