The Effect of Data Partitioning Strategy on Model Generalizability: A Case Study of Morphological Segmentation
2404.09371
0
0
Abstract
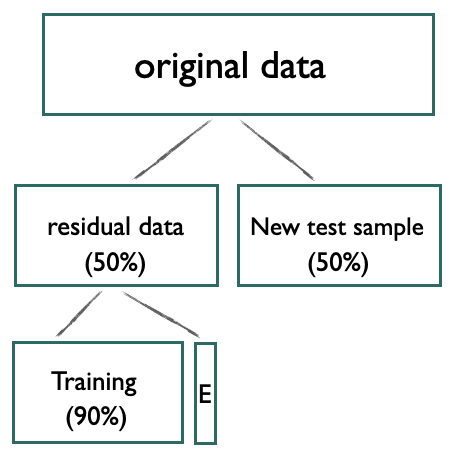
Recent work to enhance data partitioning strategies for more realistic model evaluation face challenges in providing a clear optimal choice. This study addresses these challenges, focusing on morphological segmentation and synthesizing limitations related to language diversity, adoption of multiple datasets and splits, and detailed model comparisons. Our study leverages data from 19 languages, including ten indigenous or endangered languages across 10 language families with diverse morphological systems (polysynthetic, fusional, and agglutinative) and different degrees of data availability. We conduct large-scale experimentation with varying sized combinations of training and evaluation sets as well as new test data. Our results show that, when faced with new test data: (1) models trained from random splits are able to achieve higher numerical scores; (2) model rankings derived from random splits tend to generalize more consistently.
Create account to get full access
Overview
- This paper investigates the effect of different data partitioning strategies on the generalizability of machine learning models, using morphological segmentation as a case study.
- The authors explore how splitting training and evaluation data can impact a model's ability to generalize to unseen data.
- They compare common partitioning approaches, such as random splits and temporal splits, and examine the trade-offs between them.
Plain English Explanation
When training machine learning models, researchers often split their dataset into separate portions for training the model and evaluating its performance. The way this data is partitioned can have a significant impact on how well the model generalizes to new, unseen data.
In this paper, the authors focus on the task of morphological segmentation - the process of breaking words down into their smallest meaningful parts. They investigate how different data partitioning strategies, such as randomly splitting the data or splitting it based on time, can affect the model's ability to accurately segment words it hasn't seen before.
The key idea is that the way the training and evaluation data are split can introduce biases or "data leakage" that make the model perform better on the evaluation set than it would on truly new data. By comparing common partitioning approaches, the authors aim to provide guidance on how to set up these data splits in a way that leads to more reliable and generalizable models.
Technical Explanation
The authors conduct experiments on the task of morphological segmentation, where the goal is to break down words into their smallest meaningful parts (e.g., "un-break-able" -> "un", "break", "able"). They compare the performance of models trained using different data partitioning strategies, including:
- Random splits: Randomly dividing the dataset into training and evaluation sets.
- Temporal splits: Splitting the data based on timestamp, with the earlier data used for training and the later data used for evaluation.
- Cross-validation: Repeatedly splitting the data into multiple folds for training and evaluation.
The authors train sequence-to-sequence models on the segmentation task using these different partitioning approaches and compare the models' performance on held-out test sets. They also investigate the impact of data imbalance and synthetic data on model generalizability.
The key findings are that the choice of data partitioning strategy can significantly impact a model's ability to generalize to new data, with temporal splits often leading to overly optimistic performance estimates. The authors also find that data leakage can occur when the training and evaluation sets are not properly separated, further emphasizing the need for careful data partitioning.
Critical Analysis
The authors acknowledge several limitations of their study. First, they focus on a single task (morphological segmentation) and may not be able to generalize their findings to other domains. Additionally, the authors only consider a few common data partitioning strategies and do not explore more sophisticated approaches, such as stratified sampling or domain-aware splits.
Another potential issue is that the authors do not delve deeply into the underlying reasons why certain partitioning strategies lead to better generalization. While they provide some hypotheses, a more thorough analysis of the mechanisms at play could help researchers better understand the tradeoffs and make more informed decisions about data partitioning.
Finally, the authors do not investigate the impact of model architecture or hyperparameter choices on generalizability, which could also play a significant role in the observed results. Incorporating these factors into the analysis could yield additional insights.
Conclusion
This paper highlights the critical importance of data partitioning in the development of generalizable machine learning models. By carefully examining the effects of different splitting strategies on morphological segmentation, the authors demonstrate that the way training and evaluation data are divided can have a substantial impact on a model's performance on new, unseen data.
The findings from this study provide valuable guidance for researchers and practitioners working on a wide range of machine learning tasks. By being mindful of the potential for data leakage and overly optimistic performance estimates, they can design more robust and reliable experiments, leading to models that are better equipped to generalize to real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Using Contextual Information for Sentence-level Morpheme Segmentation
Prabin Bhandari, Abhishek Paudel
0
0
Recent advancements in morpheme segmentation primarily emphasize word-level segmentation, often neglecting the contextual relevance within the sentence. In this study, we redefine the morpheme segmentation task as a sequence-to-sequence problem, treating the entire sentence as input rather than isolating individual words. Our findings reveal that the multilingual model consistently exhibits superior performance compared to monolingual counterparts. While our model did not surpass the performance of the current state-of-the-art, it demonstrated comparable efficacy with high-resource languages while revealing limitations in low-resource language scenarios.
5/15/2024
📊
Data Selection: A General Principle for Building Small Interpretable Models
Abhishek Ghose
0
0
We present convincing empirical evidence for an effective and general strategy for building accurate small models. Such models are attractive for interpretability and also find use in resource-constrained environments. The strategy is to learn the training distribution and sample accordingly from the provided training data. The distribution learning algorithm is not a contribution of this work; our contribution is a rigorous demonstration of the broad utility of this strategy in various practical settings. We apply it to the tasks of (1) building cluster explanation trees, (2) prototype-based classification, and (3) classification using Random Forests, and show that it improves the accuracy of decades-old weak traditional baselines to be competitive with specialized modern techniques. This strategy is also versatile wrt the notion of model size. In the first two tasks, model size is considered to be number of leaves in the tree and the number of prototypes respectively. In the final task involving Random Forests, the strategy is shown to be effective even when model size comprises of more than one factor: number of trees and their maximum depth. Positive results using multiple datasets are presented that are shown to be statistically significant.
4/30/2024
🏋️
The Curious Decline of Linguistic Diversity: Training Language Models on Synthetic Text
Yanzhu Guo, Guokan Shang, Michalis Vazirgiannis, Chlo'e Clavel
0
0
This study investigates the consequences of training language models on synthetic data generated by their predecessors, an increasingly prevalent practice given the prominence of powerful generative models. Diverging from the usual emphasis on performance metrics, we focus on the impact of this training methodology on linguistic diversity, especially when conducted recursively over time. To assess this, we adapt and develop a set of novel metrics targeting lexical, syntactic, and semantic diversity, applying them in recursive finetuning experiments across various natural language generation tasks in English. Our findings reveal a consistent decrease in the diversity of the model outputs through successive iterations, especially remarkable for tasks demanding high levels of creativity. This trend underscores the potential risks of training language models on synthetic text, particularly concerning the preservation of linguistic richness. Our study highlights the need for careful consideration of the long-term effects of such training approaches on the linguistic capabilities of language models.
4/17/2024
📊
Localization Is All You Evaluate: Data Leakage in Online Mapping Datasets and How to Fix It
Adam Lilja, Junsheng Fu, Erik Stenborg, Lars Hammarstrand
0
0
The task of online mapping is to predict a local map using current sensor observations, e.g. from lidar and camera, without relying on a pre-built map. State-of-the-art methods are based on supervised learning and are trained predominantly using two datasets: nuScenes and Argoverse 2. However, these datasets revisit the same geographic locations across training, validation, and test sets. Specifically, over $80$% of nuScenes and $40$% of Argoverse 2 validation and test samples are less than $5$ m from a training sample. At test time, the methods are thus evaluated more on how well they localize within a memorized implicit map built from the training data than on extrapolating to unseen locations. Naturally, this data leakage causes inflated performance numbers and we propose geographically disjoint data splits to reveal the true performance in unseen environments. Experimental results show that methods perform considerably worse, some dropping more than $45$ mAP, when trained and evaluated on proper data splits. Additionally, a reassessment of prior design choices reveals diverging conclusions from those based on the original split. Notably, the impact of lifting methods and the support from auxiliary tasks (e.g., depth supervision) on performance appears less substantial or follows a different trajectory than previously perceived. Splits can be found at https://github.com/LiljaAdam/geographical-splits
4/8/2024