On the Effect of Purely Synthetic Training Data for Different Automatic Speech Recognition Architectures

0
🏋️
Sign in to get full access
Overview
- This paper explores the impact of using purely synthetic training data on the performance of different automatic speech recognition (ASR) architectures.
- The researchers investigated how synthetic speech data generated by text-to-speech (TTS) models can be used to augment or replace real speech data for training ASR systems.
- They evaluated the effectiveness of this approach across various ASR architectures, including HMM-based, DNN-based, and end-to-end models.
Plain English Explanation
The paper looks at how well automatic speech recognition (ASR) systems can work when they're trained on synthetic speech data instead of real speech recordings. The researchers generated synthetic speech using text-to-speech (TTS) models and then used this data to train different types of ASR systems, like ones based on hidden Markov models (HMMs), deep neural networks (DNNs), and end-to-end models.
The key question they wanted to answer is: can these synthetic speech samples be used effectively to train ASR models, either on their own or combined with real speech data? If so, this could be a valuable technique for augmenting speech recognition datasets and improving ASR performance, especially in cases where it's difficult or expensive to collect real speech recordings.
Technical Explanation
The researchers evaluated the use of synthetic speech data for training different ASR architectures, including:
- HMM-based ASR: A traditional approach that models speech as a sequence of hidden Markov models.
- DNN-based ASR: Uses deep neural networks to learn acoustic and language models from data.
- End-to-end ASR: A more recent approach that directly maps audio to text transcripts without explicit modeling of intermediate representations.
They trained each of these ASR models using:
- Only real speech data
- Only synthetic speech data
- A combination of real and synthetic speech data
The results showed that using solely synthetic data tended to perform worse than using only real speech data across the different ASR architectures. However, combining synthetic and real data often led to improved performance compared to using real data alone, especially for the DNN-based and end-to-end ASR models.
The researchers hypothesize that the synthetic data can help expand the acoustic diversity of the training set, allowing the ASR models to generalize better. But the quality and fidelity of the synthetic speech compared to real speech still impacts the overall performance.
Critical Analysis
The paper provides a thorough evaluation of using synthetic speech data for training different ASR architectures. However, a few potential limitations or areas for further research are worth noting:
-
The experiments were conducted on a single, relatively small dataset. Testing the approach on a wider range of datasets, domains, and languages could help validate the generalizability of the findings.
-
The authors did not deeply explore the factors that influence the effectiveness of the synthetic data, such as the quality of the TTS model, the acoustic diversity of the synthetic samples, or the degree of mismatch between the synthetic and real speech.
-
While combining synthetic and real data showed benefits, the paper does not investigate techniques for intelligently mixing the two data sources, which could potentially lead to further performance improvements.
-
The analysis is focused on the overall ASR performance, but does not investigate the impact on specific error types or aspects of the recognition quality, which could provide additional insights.
Overall, the paper makes a valuable contribution by systematically evaluating the use of synthetic speech data for training different ASR architectures. The findings suggest this is a promising direction for data augmentation, but further research is needed to fully understand the limitations and best practices for leveraging synthetic data in speech recognition.
Conclusion
This paper explores the potential of using purely synthetic speech data generated by text-to-speech models to train automatic speech recognition (ASR) systems. The researchers evaluated the performance of HMM-based, DNN-based, and end-to-end ASR architectures when trained on synthetic data, real data, and a combination of the two.
The results indicate that while using only synthetic data tends to underperform compared to real data, combining synthetic and real data can lead to improved ASR performance, particularly for the more advanced DNN-based and end-to-end models. This suggests that synthetic speech data can be a useful tool for augmenting speech recognition datasets and enhancing the generalization capabilities of ASR systems. Further research is needed to fully understand the limitations and best practices for leveraging synthetic data in speech recognition.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
0
On the Effect of Purely Synthetic Training Data for Different Automatic Speech Recognition Architectures
Nick Rossenbach, Benedikt Hilmes, Ralf Schluter
In this work we evaluate the utility of synthetic data for training automatic speech recognition (ASR). We use the ASR training data to train a text-to-speech (TTS) system similar to FastSpeech-2. With this TTS we reproduce the original training data, training ASR systems solely on synthetic data. For ASR, we use three different architectures, attention-based encoder-decoder, hybrid deep neural network hidden Markov model and a Gaussian mixture hidden Markov model, showing the different sensitivity of the models to synthetic data generation. In order to extend previous work, we present a number of ablation studies on the effectiveness of synthetic vs. real training data for ASR. In particular we focus on how the gap between training on synthetic and real data changes by varying the speaker embedding or by scaling the model size. For the latter we show that the TTS models generalize well, even when training scores indicate overfitting.
Read more7/26/2024

0
On the Problem of Text-To-Speech Model Selection for Synthetic Data Generation in Automatic Speech Recognition
Nick Rossenbach, Ralf Schluter, Sakriani Sakti
The rapid development of neural text-to-speech (TTS) systems enabled its usage in other areas of natural language processing such as automatic speech recognition (ASR) or spoken language translation (SLT). Due to the large number of different TTS architectures and their extensions, selecting which TTS systems to use for synthetic data creation is not an easy task. We use the comparison of five different TTS decoder architectures in the scope of synthetic data generation to show the impact on CTC-based speech recognition training. We compare the recognition results to computable metrics like NISQA MOS and intelligibility, finding that there are no clear relations to the ASR performance. We also observe that for data generation auto-regressive decoding performs better than non-autoregressive decoding, and propose an approach to quantify TTS generalization capabilities.
Read more8/1/2024
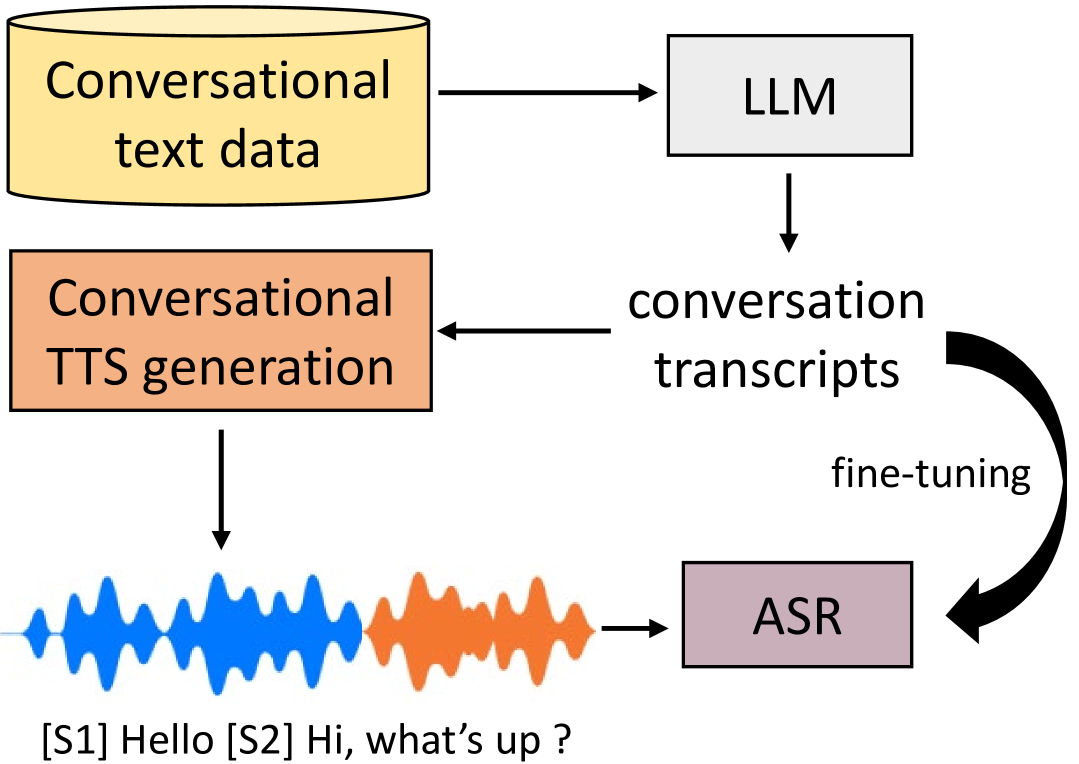
0
Generating Data with Text-to-Speech and Large-Language Models for Conversational Speech Recognition
Samuele Cornell, Jordan Darefsky, Zhiyao Duan, Shinji Watanabe
Currently, a common approach in many speech processing tasks is to leverage large scale pre-trained models by fine-tuning them on in-domain data for a particular application. Yet obtaining even a small amount of such data can be problematic, especially for sensitive domains and conversational speech scenarios, due to both privacy issues and annotation costs. To address this, synthetic data generation using single speaker datasets has been employed. Yet, for multi-speaker cases, such an approach often requires extensive manual effort and is prone to domain mismatches. In this work, we propose a synthetic data generation pipeline for multi-speaker conversational ASR, leveraging a large language model (LLM) for content creation and a conversational multi-speaker text-to-speech (TTS) model for speech synthesis. We conduct evaluation by fine-tuning the Whisper ASR model for telephone and distant conversational speech settings, using both in-domain data and generated synthetic data. Our results show that the proposed method is able to significantly outperform classical multi-speaker generation approaches that use external, non-conversational speech datasets.
Read more8/20/2024

0
Improving Accented Speech Recognition using Data Augmentation based on Unsupervised Text-to-Speech Synthesis
Cong-Thanh Do, Shuhei Imai, Rama Doddipatla, Thomas Hain
This paper investigates the use of unsupervised text-to-speech synthesis (TTS) as a data augmentation method to improve accented speech recognition. TTS systems are trained with a small amount of accented speech training data and their pseudo-labels rather than manual transcriptions, and hence unsupervised. This approach enables the use of accented speech data without manual transcriptions to perform data augmentation for accented speech recognition. Synthetic accented speech data, generated from text prompts by using the TTS systems, are then combined with available non-accented speech data to train automatic speech recognition (ASR) systems. ASR experiments are performed in a self-supervised learning framework using a Wav2vec2.0 model which was pre-trained on large amount of unsupervised accented speech data. The accented speech data for training the unsupervised TTS are read speech, selected from L2-ARCTIC and British Isles corpora, while spontaneous conversational speech from the Edinburgh international accents of English corpus are used as the evaluation data. Experimental results show that Wav2vec2.0 models which are fine-tuned to downstream ASR task with synthetic accented speech data, generated by the unsupervised TTS, yield up to 6.1% relative word error rate reductions compared to a Wav2vec2.0 baseline which is fine-tuned with the non-accented speech data from Librispeech corpus.
Read more7/8/2024