A Study on Incorporating Whisper for Robust Speech Assessment
2309.12766
0
0
🗣️
Abstract
This research introduces an enhanced version of the multi-objective speech assessment model--MOSA-Net+, by leveraging the acoustic features from Whisper, a large-scaled weakly supervised model. We first investigate the effectiveness of Whisper in deploying a more robust speech assessment model. After that, we explore combining representations from Whisper and SSL models. The experimental results reveal that Whisper's embedding features can contribute to more accurate prediction performance. Moreover, combining the embedding features from Whisper and SSL models only leads to marginal improvement. As compared to intrusive methods, MOSA-Net, and other SSL-based speech assessment models, MOSA-Net+ yields notable improvements in estimating subjective quality and intelligibility scores across all evaluation metrics in Taiwan Mandarin Hearing In Noise test - Quality & Intelligibility (TMHINT-QI) dataset. To further validate its robustness, MOSA-Net+ was tested in the noisy-and-enhanced track of the VoiceMOS Challenge 2023, where it obtained the top-ranked performance among nine systems.
Create account to get full access
Overview
- This research introduces an enhanced version of the multi-objective speech assessment model, MOSA-Net+, by leveraging the acoustic features from Whisper, a large-scaled weakly supervised model.
- The researchers investigate the effectiveness of Whisper in deploying a more robust speech assessment model and explore combining representations from Whisper and SSL (self-supervised learning) models.
- The experimental results reveal that Whisper's embedding features can contribute to more accurate prediction performance, while combining the embedding features from Whisper and SSL models only leads to marginal improvement.
- MOSA-Net+ outperforms intrusive methods, MOSA-Net, and other SSL-based speech assessment models in estimating subjective quality and intelligibility scores across all evaluation metrics in the Taiwan Mandarin Hearing In Noise test - Quality & Intelligibility (TMHINT-QI) dataset.
- MOSA-Net+ also obtained top-ranked performance among nine systems in the noisy-and-enhanced track of the VoiceMOS Challenge 2023, further validating its robustness.
Plain English Explanation
The researchers have developed an improved version of a speech assessment model called MOSA-Net+. This new model uses features extracted from Whisper, a large-scale AI model trained on a vast amount of speech data. By incorporating Whisper's acoustic features, the researchers aim to create a more robust and accurate speech assessment system.
The key idea is that Whisper's extensive training on a wide range of speech data can provide valuable information to help assess speech quality and intelligibility more effectively. The researchers found that using Whisper's features alone can lead to better prediction performance compared to other methods.
They also explored combining Whisper's features with those from other self-supervised learning (SSL) models, but this did not result in a significant further improvement. Nonetheless, the MOSA-Net+ model outperformed other existing methods, including intrusive approaches and previous versions of MOSA-Net, in estimating subjective speech quality and intelligibility scores on a Mandarin speech dataset.
To further validate the model's robustness, the researchers tested MOSA-Net+ in a speech quality assessment challenge, where it achieved the top performance among all the participating systems.
Technical Explanation
The researchers introduce an enhanced version of the MOSA-Net speech assessment model, called MOSA-Net+, by leveraging the acoustic features from Whisper, a large-scale weakly supervised model.
First, the researchers investigate the effectiveness of Whisper in deploying a more robust speech assessment model. They explore combining representations from Whisper and SSL models, as previous research has shown the potential of combining self-supervised representations for speech quality assessment.
The experimental results reveal that Whisper's embedding features can contribute to more accurate prediction performance. However, combining the embedding features from Whisper and SSL models only leads to marginal improvement.
Compared to intrusive methods, MOSA-Net, and other SSL-based speech assessment models, MOSA-Net+ yields notable improvements in estimating subjective quality and intelligibility scores across all evaluation metrics in the Taiwan Mandarin Hearing In Noise test - Quality & Intelligibility (TMHINT-QI) dataset.
To further validate its robustness, MOSA-Net+ was tested in the noisy-and-enhanced track of the VoiceMOS Challenge 2023, where it obtained the top-ranked performance among nine systems, demonstrating its efficiency in infusing self-supervised representations for automatic speech assessment.
Critical Analysis
The paper provides a thorough evaluation of the MOSA-Net+ model and its performance compared to other speech assessment approaches. However, the researchers do not delve into potential limitations or areas for further research.
One potential concern is the reliance on the TMHINT-QI dataset, which may not fully capture the diversity of speech samples encountered in real-world scenarios. The researchers could consider evaluating the model's performance on a broader range of datasets to ensure its robustness.
Additionally, the paper does not discuss the computational complexity or resource requirements of the MOSA-Net+ model. As speech assessment models are often deployed in resource-constrained environments, such as mobile devices, understanding the model's efficiency would be valuable for practical applications.
Further research could explore the interpretability of the MOSA-Net+ model, providing insights into the specific acoustic features and their contributions to the speech assessment process. This could help researchers and practitioners better understand the model's decision-making and potentially lead to improvements in the future.
Conclusion
The research introduces an enhanced version of the MOSA-Net speech assessment model, MOSA-Net+, which leverages the acoustic features from the Whisper model. The experimental results demonstrate that Whisper's embedding features can contribute to more accurate prediction performance in estimating subjective speech quality and intelligibility.
MOSA-Net+ outperforms other intrusive methods, MOSA-Net, and SSL-based speech assessment models across various evaluation metrics. Furthermore, the model's top-ranked performance in the VoiceMOS Challenge 2023 validates its robustness and potential for practical applications in speech assessment and quality evaluation.
This research highlights the benefits of incorporating large-scale, weakly supervised models like Whisper to improve the accuracy and reliability of speech assessment systems. The findings have implications for developing more effective automated tools for speech quality analysis, which could be valuable in a wide range of applications, from communication systems to assistive technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🗣️
Non-Intrusive Speech Intelligibility Prediction for Hearing Aids using Whisper and Metadata
Ryandhimas E. Zezario, Fei Chen, Chiou-Shann Fuh, Hsin-Min Wang, Yu Tsao
0
0
Automated speech intelligibility assessment is pivotal for hearing aid (HA) development. In this paper, we present three novel methods to improve intelligibility prediction accuracy and introduce MBI-Net+, an enhanced version of MBI-Net, the top-performing system in the 1st Clarity Prediction Challenge. MBI-Net+ leverages Whisper's embeddings to create cross-domain acoustic features and includes metadata from speech signals by using a classifier that distinguishes different enhancement methods. Furthermore, MBI-Net+ integrates the hearing-aid speech perception index (HASPI) as a supplementary metric into the objective function to further boost prediction performance. Experimental results demonstrate that MBI-Net+ surpasses several intrusive baseline systems and MBI-Net on the Clarity Prediction Challenge 2023 dataset, validating the effectiveness of incorporating Whisper embeddings, speech metadata, and related complementary metrics to improve prediction performance for HA.
6/14/2024
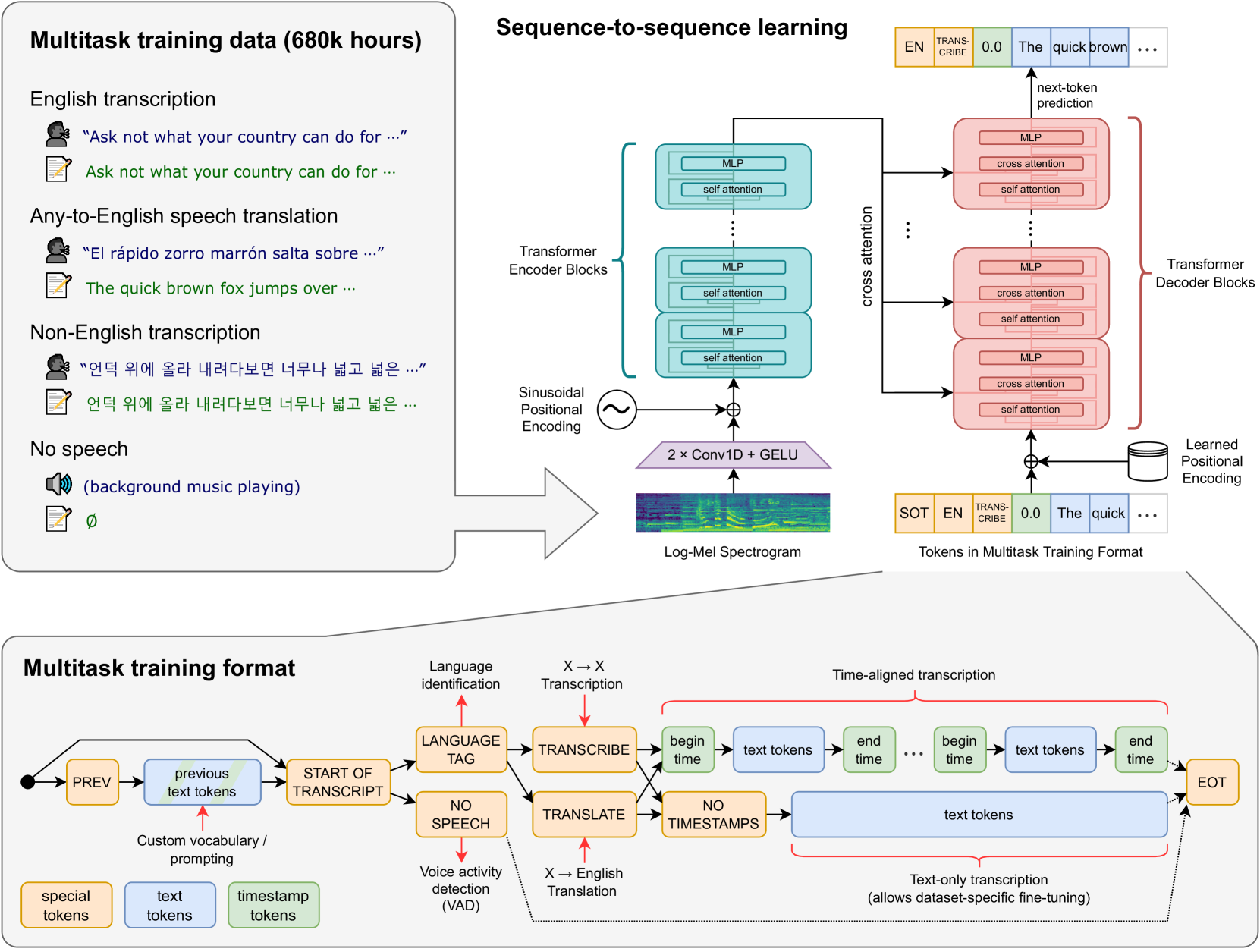
Efficient Compression of Multitask Multilingual Speech Models
Thomas Palmeira Ferraz
0
0
Whisper is a multitask and multilingual speech model covering 99 languages. It yields commendable automatic speech recognition (ASR) results in a subset of its covered languages, but the model still underperforms on a non-negligible number of under-represented languages, a problem exacerbated in smaller model versions. In this work, we examine its limitations, demonstrating the presence of speaker-related (gender, age) and model-related (resourcefulness and model size) bias. Despite that, we show that only model-related bias are amplified by quantization, impacting more low-resource languages and smaller models. Searching for a better compression approach, we propose DistilWhisper, an approach that is able to bridge the performance gap in ASR for these languages while retaining the advantages of multitask and multilingual capabilities. Our approach involves two key strategies: lightweight modular ASR fine-tuning of whisper-small using language-specific experts, and knowledge distillation from whisper-large-v2. This dual approach allows us to effectively boost ASR performance while keeping the robustness inherited from the multitask and multilingual pre-training. Results demonstrate that our approach is more effective than standard fine-tuning or LoRA adapters, boosting performance in the targeted languages for both in- and out-of-domain test sets, while introducing only a negligible parameter overhead at inference.
5/3/2024

LoRA-Whisper: Parameter-Efficient and Extensible Multilingual ASR
Zheshu Song, Jianheng Zhuo, Yifan Yang, Ziyang Ma, Shixiong Zhang, Xie Chen
0
0
Recent years have witnessed significant progress in multilingual automatic speech recognition (ASR), driven by the emergence of end-to-end (E2E) models and the scaling of multilingual datasets. Despite that, two main challenges persist in multilingual ASR: language interference and the incorporation of new languages without degrading the performance of the existing ones. This paper proposes LoRA-Whisper, which incorporates LoRA matrix into Whisper for multilingual ASR, effectively mitigating language interference. Furthermore, by leveraging LoRA and the similarities between languages, we can achieve better performance on new languages while upholding consistent performance on original ones. Experiments on a real-world task across eight languages demonstrate that our proposed LoRA-Whisper yields a relative gain of 18.5% and 23.0% over the baseline system for multilingual ASR and language expansion respectively.
6/12/2024

Prompting Whisper for QA-driven Zero-shot End-to-end Spoken Language Understanding
Mohan Li, Simon Keizer, Rama Doddipatla
0
0
Zero-shot spoken language understanding (SLU) enables systems to comprehend user utterances in new domains without prior exposure to training data. Recent studies often rely on large language models (LLMs), leading to excessive footprints and complexity. This paper proposes the use of Whisper, a standalone speech processing model, for zero-shot end-to-end (E2E) SLU. To handle unseen semantic labels, SLU tasks are integrated into a question-answering (QA) framework, which prompts the Whisper decoder for semantics deduction. The system is efficiently trained with prefix-tuning, optimising a minimal set of parameters rather than the entire Whisper model. We show that the proposed system achieves a 40.7% absolute gain for slot filling (SLU-F1) on SLURP compared to a recently introduced zero-shot benchmark. Furthermore, it performs comparably to a Whisper-GPT-2 modular system under both in-corpus and cross-corpus evaluation settings, but with a relative 34.8% reduction in model parameters.
6/24/2024