An Efficient Continuous Control Perspective for Reinforcement-Learning-based Sequential Recommendation

0
Sign in to get full access
Overview
- The paper proposes an efficient continuous control perspective for reinforcement-learning-based sequential recommendation
- It aims to improve the performance and efficiency of reinforcement learning (RL) models for sequential recommendation tasks
- The approach leverages a continuous control framework to enable more efficient exploration and optimization compared to traditional RL methods
Plain English Explanation
The paper presents a new way of using reinforcement learning (RL) for sequential recommendation tasks, such as suggesting the next product or content a user should interact with. Traditional RL methods for this problem can be inefficient and struggle to explore the vast space of possible recommendations effectively.
To address this, the authors propose framing the sequential recommendation problem as a continuous control task. This means they model the recommendation process as a smooth, continuous function rather than a series of discrete choices. This allows the RL agent to explore the space of possible recommendations in a more efficient and nuanced way, leading to better performance on real-world recommendation tasks.
The key insight is that by treating recommendation as a continuous control problem, the RL agent can learn to make small, incremental adjustments to its recommendations, rather than having to make large, discrete jumps. This helps the agent explore the recommendation space more thoroughly and find better solutions.
Technical Explanation
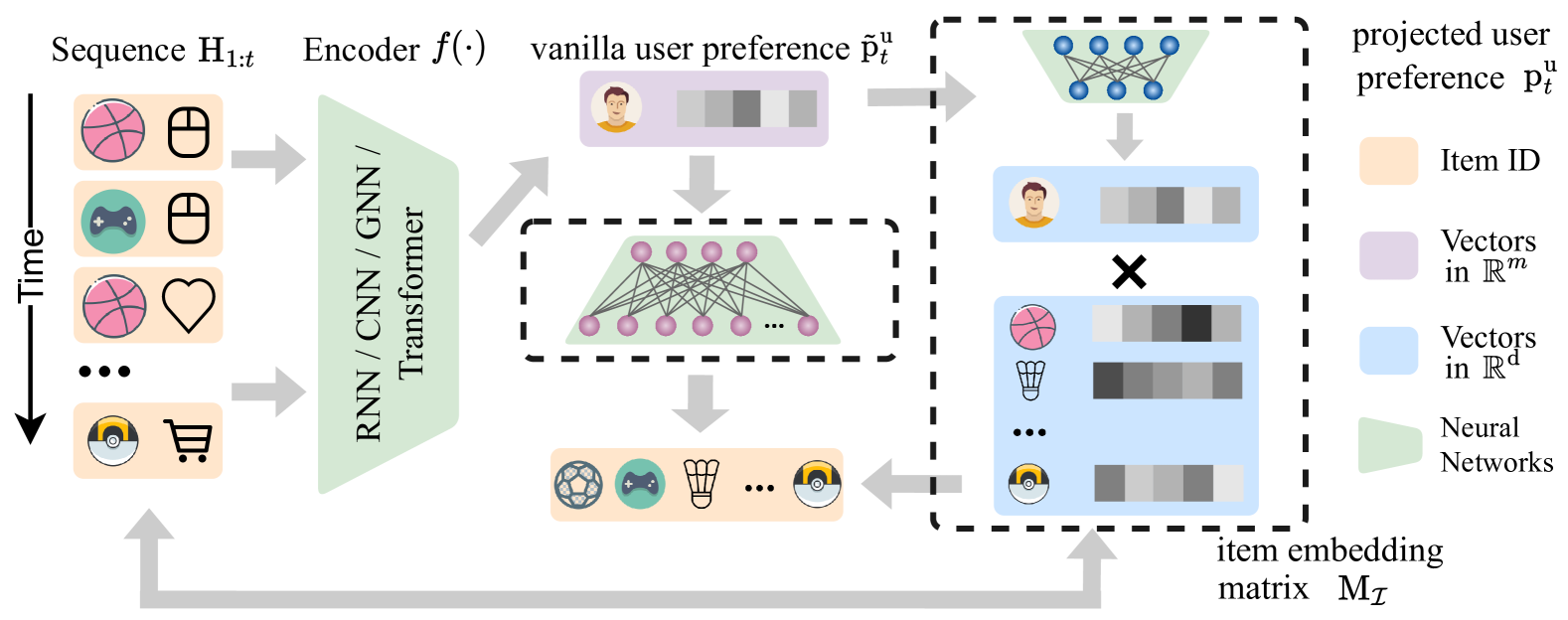
The paper formulates the sequential recommendation problem as a continuous control task, where the goal is to learn a smooth, continuous function that maps a user's context (e.g., their past interactions, preferences, etc.) to a recommended item. This is in contrast to traditional RL approaches that treat recommendation as a discrete choice problem.
To achieve this, the authors propose a novel RL framework that combines elements of actor-critic and deep deterministic policy gradient methods. This allows the agent to learn a continuous recommendation policy while also efficiently exploring the recommendation space.
The key components of the framework include:
- Continuous Recommendation Policy: The agent learns a smooth, differentiable function that maps user context to a recommended item.
- Actor-Critic Architecture: The agent uses an actor network to generate recommendations and a critic network to evaluate the quality of those recommendations.
- Efficient Exploration: The agent leverages the continuous nature of the recommendation policy to explore the space of possible recommendations in a more efficient and targeted way.
The authors evaluate their approach on several real-world recommendation datasets and show that it outperforms traditional RL and other baselines in terms of recommendation quality and efficiency.
Critical Analysis
The paper presents a novel and promising approach to using RL for sequential recommendation tasks. The continuous control formulation is a clever way to address the limitations of traditional discrete RL methods, and the authors demonstrate that it can lead to significant performance improvements.
However, the paper does not address some potential limitations and areas for future research:
- Scalability: While the continuous control framework may be more efficient than discrete RL, it is still unclear how well it would scale to very large recommendation spaces or high-dimensional user contexts.
- Interpretability: The learned continuous recommendation policy may be difficult to interpret and understand, which could be a concern for some real-world applications.
- Robustness: The paper does not explore the robustness of the approach to noisy or incomplete user data, which is a common challenge in real-world recommendation scenarios.
Additionally, the paper could have benefited from a more thorough comparison to other recent advances in RL-based recommendation, such as ROLER and Rich Observation RL, to better contextualize the contributions of the proposed approach.
Conclusion
The paper presents an innovative continuous control perspective for reinforcement-learning-based sequential recommendation. By framing the recommendation problem as a smooth, continuous function, the authors are able to develop a more efficient and effective RL framework that outperforms traditional discrete RL methods.
While the approach shows promise, there are still some open challenges and areas for further research, such as scalability, interpretability, and robustness. However, the core idea of leveraging continuous control techniques for recommendation tasks is a valuable contribution that could inspire further advancements in this important area of research.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
An Efficient Continuous Control Perspective for Reinforcement-Learning-based Sequential Recommendation
Jun Wang, Likang Wu, Qi Liu, Yu Yang
Sequential recommendation, where user preference is dynamically inferred from sequential historical behaviors, is a critical task in recommender systems (RSs). To further optimize long-term user engagement, offline reinforcement-learning-based RSs have become a mainstream technique as they provide an additional advantage in avoiding global explorations that may harm online users' experiences. However, previous studies mainly focus on discrete action and policy spaces, which might have difficulties in handling dramatically growing items efficiently. To mitigate this issue, in this paper, we aim to design an algorithmic framework applicable to continuous policies. To facilitate the control in the low-dimensional but dense user preference space, we propose an underline{textbf{E}}fficient underline{textbf{Co}}ntinuous underline{textbf{C}}ontrol framework (ECoC). Based on a statistically tested assumption, we first propose the novel unified action representation abstracted from normalized user and item spaces. Then, we develop the corresponding policy evaluation and policy improvement procedures. During this process, strategic exploration and directional control in terms of unified actions are carefully designed and crucial to final recommendation decisions. Moreover, beneficial from unified actions, the conservatism regularization for policies and value functions are combined and perfectly compatible with the continuous framework. The resulting dual regularization ensures the successful offline training of RL-based recommendation policies. Finally, we conduct extensive experiments to validate the effectiveness of our framework. The results show that compared to the discrete baselines, our ECoC is trained far more efficiently. Meanwhile, the final policies outperform baselines in both capturing the offline data and gaining long-term rewards.
Read more8/16/2024
🏅
0
Robust Reinforcement Learning Objectives for Sequential Recommender Systems
Melissa Mozifian, Tristan Sylvain, Dave Evans, Lili Meng
Attention-based sequential recommendation methods have shown promise in accurately capturing users' evolving interests from their past interactions. Recent research has also explored the integration of reinforcement learning (RL) into these models, in addition to generating superior user representations. By framing sequential recommendation as an RL problem with reward signals, we can develop recommender systems that incorporate direct user feedback in the form of rewards, enhancing personalization for users. Nonetheless, employing RL algorithms presents challenges, including off-policy training, expansive combinatorial action spaces, and the scarcity of datasets with sufficient reward signals. Contemporary approaches have attempted to combine RL and sequential modeling, incorporating contrastive-based objectives and negative sampling strategies for training the RL component. In this work, we further emphasize the efficacy of contrastive-based objectives paired with augmentation to address datasets with extended horizons. Additionally, we recognize the potential instability issues that may arise during the application of negative sampling. These challenges primarily stem from the data imbalance prevalent in real-world datasets, which is a common issue in offline RL contexts. Furthermore, we introduce an enhanced methodology aimed at providing a more effective solution to these challenges. Experimental results across several real datasets show our method with increased robustness and state-of-the-art performance.
Read more4/19/2024

0
Continuous Control with Coarse-to-fine Reinforcement Learning
Younggyo Seo, Jafar Uruc{c}, Stephen James
Despite recent advances in improving the sample-efficiency of reinforcement learning (RL) algorithms, designing an RL algorithm that can be practically deployed in real-world environments remains a challenge. In this paper, we present Coarse-to-fine Reinforcement Learning (CRL), a framework that trains RL agents to zoom-into a continuous action space in a coarse-to-fine manner, enabling the use of stable, sample-efficient value-based RL algorithms for fine-grained continuous control tasks. Our key idea is to train agents that output actions by iterating the procedure of (i) discretizing the continuous action space into multiple intervals and (ii) selecting the interval with the highest Q-value to further discretize at the next level. We then introduce a concrete, value-based algorithm within the CRL framework called Coarse-to-fine Q-Network (CQN). Our experiments demonstrate that CQN significantly outperforms RL and behavior cloning baselines on 20 sparsely-rewarded RLBench manipulation tasks with a modest number of environment interactions and expert demonstrations. We also show that CQN robustly learns to solve real-world manipulation tasks within a few minutes of online training.
Read more7/11/2024

0
UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems
Changshuo Zhang, Sirui Chen, Xiao Zhang, Sunhao Dai, Weijie Yu, Jun Xu
Reinforcement learning (RL) has gained traction for enhancing user long-term experiences in recommender systems by effectively exploring users' interests. However, modern recommender systems exhibit distinct user behavioral patterns among tens of millions of items, which increases the difficulty of exploration. For example, user behaviors with different activity levels require varying intensity of exploration, while previous studies often overlook this aspect and apply a uniform exploration strategy to all users, which ultimately hurts user experiences in the long run. To address these challenges, we propose User-Oriented Exploration Policy (UOEP), a novel approach facilitating fine-grained exploration among user groups. We first construct a distributional critic which allows policy optimization under varying quantile levels of cumulative reward feedbacks from users, representing user groups with varying activity levels. Guided by this critic, we devise a population of distinct actors aimed at effective and fine-grained exploration within its respective user group. To simultaneously enhance diversity and stability during the exploration process, we further introduce a population-level diversity regularization term and a supervision module. Experimental results on public recommendation datasets demonstrate that our approach outperforms all other baselines in terms of long-term performance, validating its user-oriented exploration effectiveness. Meanwhile, further analyses reveal our approach's benefits of improved performance for low-activity users as well as increased fairness among users.
Read more5/24/2024