ROLeR: Effective Reward Shaping in Offline Reinforcement Learning for Recommender Systems

0
Sign in to get full access
Overview
- This paper proposes a novel reward shaping technique called ROLeR (Reward Optimization for Offline Reinforcement Learning) to improve the performance of offline reinforcement learning in recommender systems.
- The authors show that ROLeR can effectively learn rewards from offline data, resulting in better recommendation policies compared to existing approaches.
- The technique involves optimizing a reward function that balances user preferences, item attributes, and temporal dynamics, which are crucial factors in recommendation tasks.
Plain English Explanation
Recommendation systems are algorithms that suggest products, content, or services to users based on their past behavior and preferences. These systems often rely on offline reinforcement learning, where the algorithm learns from historical data without interacting with users in real-time.
The key challenge in offline reinforcement learning for recommender systems is reward shaping. This involves designing a reward function that accurately captures the user's preferences and the dynamics of the recommendation task. The authors of this paper propose a new technique called ROLeR (Reward Optimization for Offline Reinforcement Learning) to address this challenge.
ROLeR optimizes a reward function that takes into account three crucial factors in recommendation tasks: user preferences, item attributes, and temporal dynamics. By effectively learning these factors from offline data, ROLeR can generate recommendation policies that perform better than existing approaches.
The authors demonstrate the effectiveness of ROLeR through extensive experiments on real-world datasets, showing that it outperforms other offline inverse reinforcement learning techniques in terms of recommendation quality and robustness to distributional shift.
Technical Explanation
The core idea of ROLeR is to optimize a reward function that captures the key factors influencing user preferences in recommendation tasks. The reward function is parameterized as a linear combination of user-item interaction features, item attribute features, and temporal features.
The authors formulate the reward learning problem as a unified linear programming framework. This allows them to efficiently learn the reward function parameters from offline data, without the need for direct user interaction or exploration.
The learned reward function is then used to train a reinforcement learning agent, which generates the final recommendation policy. The authors show that this robust reinforcement learning objective leads to better recommendation performance compared to existing offline reinforcement learning approaches.
Critical Analysis
The authors acknowledge several limitations and areas for future research. First, the reward function parameterization may not capture all the complexities of user preferences, and more expressive models could potentially further improve performance.
Additionally, the authors only evaluate ROLeR on a limited set of recommendation datasets and tasks. Applying the technique to a wider range of real-world recommendation scenarios, including those with sparse data or complex user-item interactions, could provide additional insights.
The paper also does not explore the potential negative societal impacts of the proposed approach, such as the propagation of biases present in the offline data or the ethical implications of optimizing recommendation policies solely based on user engagement metrics.
Conclusion
The ROLeR technique proposed in this paper represents a significant advancement in the field of offline reinforcement learning for recommender systems. By effectively learning a reward function that captures key factors influencing user preferences, the authors demonstrate how to generate more effective recommendation policies from historical data.
The work has important implications for the development of sequential recommender systems that can better adapt to user preferences and the evolving dynamics of recommendation tasks. As the authors note, further research is needed to address the limitations and explore the broader societal impacts of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ROLeR: Effective Reward Shaping in Offline Reinforcement Learning for Recommender Systems
Yi Zhang, Ruihong Qiu, Jiajun Liu, Sen Wang
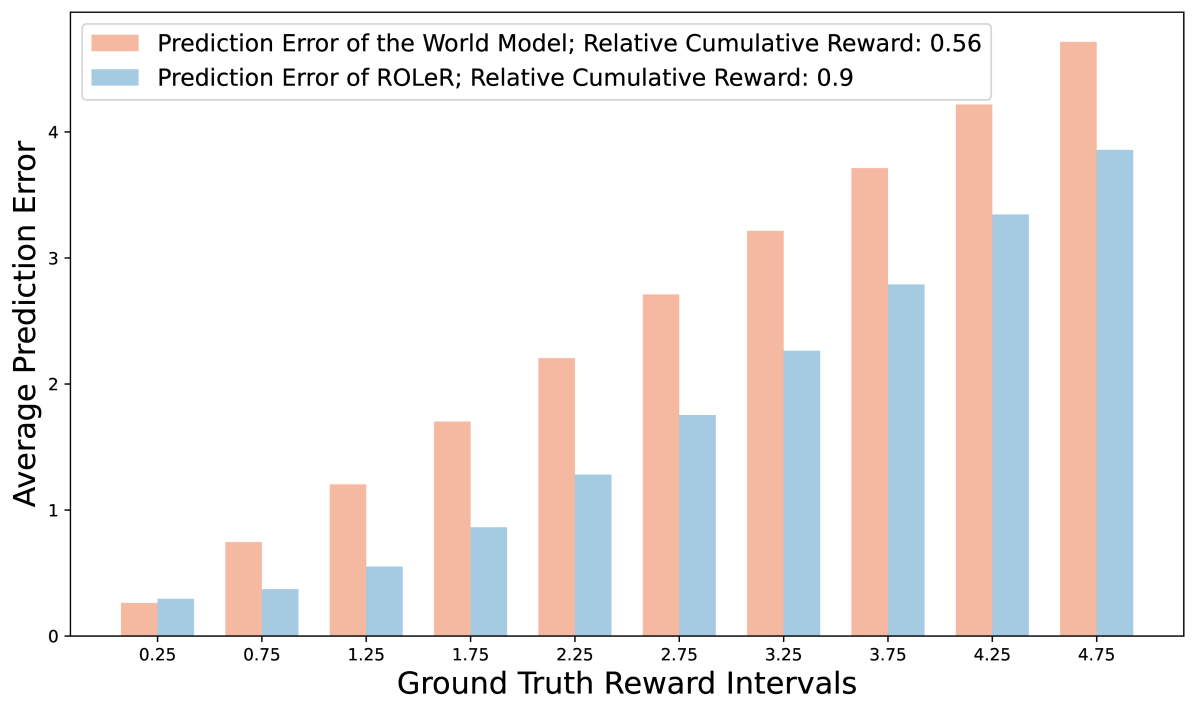
Offline reinforcement learning (RL) is an effective tool for real-world recommender systems with its capacity to model the dynamic interest of users and its interactive nature. Most existing offline RL recommender systems focus on model-based RL through learning a world model from offline data and building the recommendation policy by interacting with this model. Although these methods have made progress in the recommendation performance, the effectiveness of model-based offline RL methods is often constrained by the accuracy of the estimation of the reward model and the model uncertainties, primarily due to the extreme discrepancy between offline logged data and real-world data in user interactions with online platforms. To fill this gap, a more accurate reward model and uncertainty estimation are needed for the model-based RL methods. In this paper, a novel model-based Reward Shaping in Offline Reinforcement Learning for Recommender Systems, ROLeR, is proposed for reward and uncertainty estimation in recommendation systems. Specifically, a non-parametric reward shaping method is designed to refine the reward model. In addition, a flexible and more representative uncertainty penalty is designed to fit the needs of recommendation systems. Extensive experiments conducted on four benchmark datasets showcase that ROLeR achieves state-of-the-art performance compared with existing baselines. The source code can be downloaded at https://github.com/ArronDZhang/ROLeR.
Read more7/19/2024

0
Offline Reinforcement Learning with Imputed Rewards
Carlo Romeo, Andrew D. Bagdanov
Offline Reinforcement Learning (ORL) offers a robust solution to training agents in applications where interactions with the environment must be strictly limited due to cost, safety, or lack of accurate simulation environments. Despite its potential to facilitate deployment of artificial agents in the real world, Offline Reinforcement Learning typically requires very many demonstrations annotated with ground-truth rewards. Consequently, state-of-the-art ORL algorithms can be difficult or impossible to apply in data-scarce scenarios. In this paper we propose a simple but effective Reward Model that can estimate the reward signal from a very limited sample of environment transitions annotated with rewards. Once the reward signal is modeled, we use the Reward Model to impute rewards for a large sample of reward-free transitions, thus enabling the application of ORL techniques. We demonstrate the potential of our approach on several D4RL continuous locomotion tasks. Our results show that, using only 1% of reward-labeled transitions from the original datasets, our learned reward model is able to impute rewards for the remaining 99% of the transitions, from which performant agents can be learned using Offline Reinforcement Learning.
Read more7/16/2024
0
Preference Elicitation for Offline Reinforcement Learning
Aliz'ee Pace, Bernhard Scholkopf, Gunnar Ratsch, Giorgia Ramponi
Applying reinforcement learning (RL) to real-world problems is often made challenging by the inability to interact with the environment and the difficulty of designing reward functions. Offline RL addresses the first challenge by considering access to an offline dataset of environment interactions labeled by the reward function. In contrast, Preference-based RL does not assume access to the reward function and learns it from preferences, but typically requires an online interaction with the environment. We bridge the gap between these frameworks by exploring efficient methods for acquiring preference feedback in a fully offline setup. We propose Sim-OPRL, an offline preference-based reinforcement learning algorithm, which leverages a learned environment model to elicit preference feedback on simulated rollouts. Drawing on insights from both the offline RL and the preference-based RL literature, our algorithm employs a pessimistic approach for out-of-distribution data, and an optimistic approach for acquiring informative preferences about the optimal policy. We provide theoretical guarantees regarding the sample complexity of our approach, dependent on how well the offline data covers the optimal policy. Finally, we demonstrate the empirical performance of Sim-OPRL in different environments.
Read more6/27/2024
🐍
0
A Unified Linear Programming Framework for Offline Reward Learning from Human Demonstrations and Feedback
Kihyun Kim, Jiawei Zhang, Asuman Ozdaglar, Pablo A. Parrilo
Inverse Reinforcement Learning (IRL) and Reinforcement Learning from Human Feedback (RLHF) are pivotal methodologies in reward learning, which involve inferring and shaping the underlying reward function of sequential decision-making problems based on observed human demonstrations and feedback. Most prior work in reward learning has relied on prior knowledge or assumptions about decision or preference models, potentially leading to robustness issues. In response, this paper introduces a novel linear programming (LP) framework tailored for offline reward learning. Utilizing pre-collected trajectories without online exploration, this framework estimates a feasible reward set from the primal-dual optimality conditions of a suitably designed LP, and offers an optimality guarantee with provable sample efficiency. Our LP framework also enables aligning the reward functions with human feedback, such as pairwise trajectory comparison data, while maintaining computational tractability and sample efficiency. We demonstrate that our framework potentially achieves better performance compared to the conventional maximum likelihood estimation (MLE) approach through analytical examples and numerical experiments.
Read more6/5/2024