UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems

0

Sign in to get full access
Overview
- The paper proposes a new approach called UOEP (User-Oriented Exploration Policy) for enhancing long-term user experiences in recommender systems.
- UOEP aims to improve the exploration-exploitation balance in recommender systems to provide more personalized and satisfactory recommendations over time.
- The key idea is to model user preferences and incorporate user-specific exploration patterns to guide the recommendation process.
Plain English Explanation
Recommender systems are algorithms that suggest products, services, or content to users based on their past preferences and behaviors. However, these systems often struggle to balance exploration (trying new things) and exploitation (recommending familiar items) in a way that maximizes user satisfaction over the long term.
The UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems paper introduces a new approach called UOEP that tries to address this challenge. The core insight is that by modeling each user's unique exploration patterns and preferences, the recommender system can make more personalized and satisfying recommendations over time.
UOEP works by first learning a model of each user's interests and exploration tendencies. It then uses this information to guide the recommendation process, striking a balance between suggesting familiar items the user is likely to enjoy and introducing new, potentially interesting options. This helps the system keep users engaged and satisfied, even as their tastes and interests evolve.
The authors demonstrate the effectiveness of UOEP through experiments on real-world datasets, showing that it outperforms traditional recommender systems in terms of long-term user satisfaction and engagement. This suggests that personalized exploration strategies like UOEP could be a valuable tool for building more user-friendly and impactful recommender systems.
Technical Explanation
The UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems paper proposes a new approach called UOEP (User-Oriented Exploration Policy) to address the challenge of balancing exploration and exploitation in recommender systems.
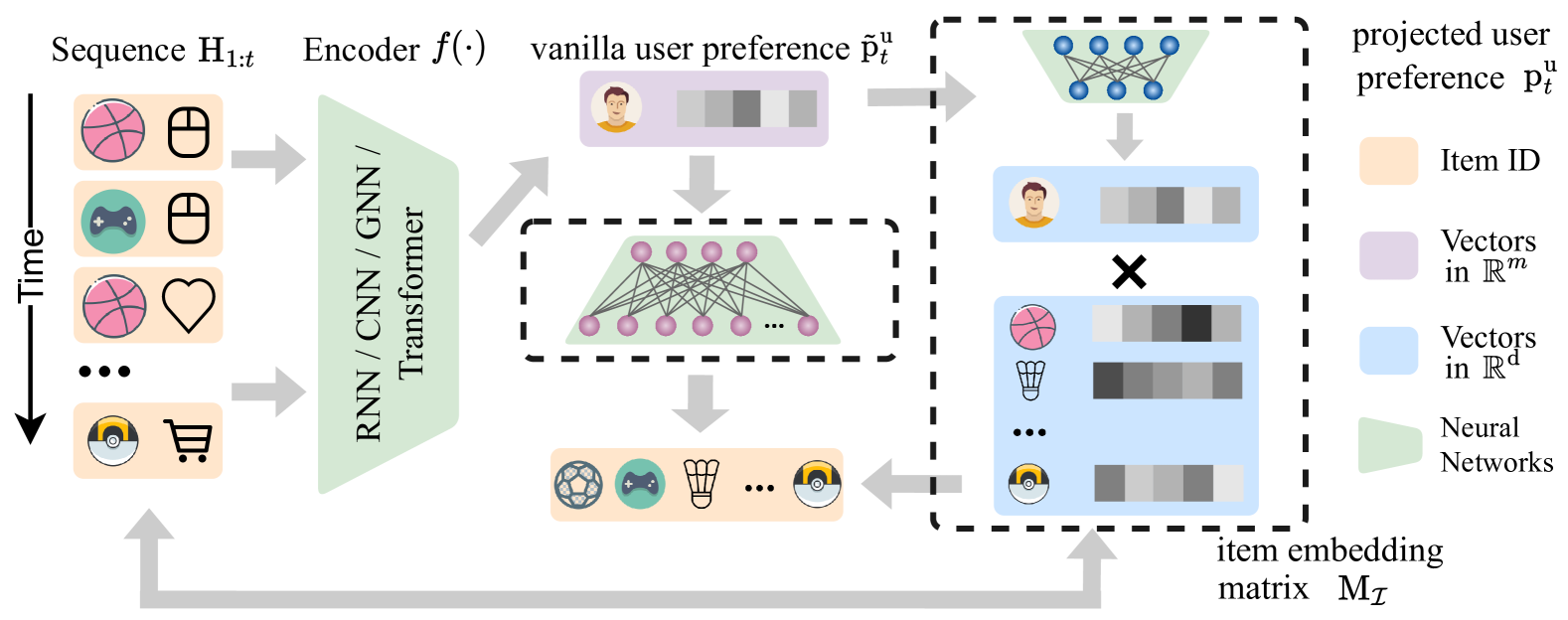
The key idea behind UOEP is to model each user's unique exploration patterns and preferences, and then use this information to guide the recommendation process. The authors formulate the problem as a Markov Decision Process (MDP), where the recommender system's actions correspond to making recommendations to the user.
The UOEP approach has three main components:
- User Preference Model: This component learns a personalized user preference model for each user, capturing their interests and exploration tendencies.
- Exploration Policy: Based on the user preference model, UOEP learns an exploration policy that determines the optimal balance between exploring new items and exploiting the user's known preferences.
- Recommendation Policy: The recommendation policy combines the exploration policy with the user preference model to generate personalized recommendations that are tailored to each user's long-term satisfaction.
The authors evaluate UOEP on real-world datasets and compare it to several baseline recommender systems. The results show that UOEP outperforms the baselines in terms of long-term user satisfaction and engagement, demonstrating the value of incorporating personalized exploration strategies into recommender systems.
Critical Analysis
The UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems paper presents an innovative approach to improving the long-term user experience in recommender systems. The authors' focus on modeling individual user preferences and exploration patterns is a valuable contribution, as it recognizes the importance of personalization in building effective and engaging recommender systems.
However, the paper does not address several potential limitations and areas for further research:
-
Cold-Start Problem: The paper does not discuss how UOEP would handle new users or items with limited historical data, which is a common challenge in recommender systems. Incorporating techniques to address the cold-start problem could further enhance the system's practical applicability.
-
Fairness and Bias: The paper does not consider the potential for UOEP to introduce or exacerbate biases in the recommendation process, such as reinforcing existing user biases or limiting the diversity of recommendations. Exploring fairness-aware extensions of UOEP could be an important area for future research.
-
Computational Complexity: The authors do not provide a detailed analysis of the computational complexity of UOEP, which could be an important consideration for real-world deployment, especially in large-scale recommender systems. Investigating ways to optimize the algorithm's efficiency would be valuable.
-
User Involvement: The paper does not discuss the potential for involving users in the exploration and recommendation process, such as allowing them to provide feedback or preferences on the exploration strategy. Incorporating user agency could further improve the long-term user experience.
Despite these limitations, the UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems paper presents a promising approach that could significantly enhance the effectiveness and user-friendliness of recommender systems. The authors' focus on personalization and long-term user satisfaction is an important step forward in the field.
Conclusion
The UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems paper introduces a novel approach called UOEP that aims to improve the long-term user experience in recommender systems. By modeling individual user preferences and exploration patterns, UOEP is able to strike a better balance between exploration and exploitation, leading to more personalized and satisfying recommendations over time.
The authors' experimental results demonstrate the effectiveness of UOEP compared to traditional recommender systems, suggesting that personalized exploration strategies could be a valuable tool for building more user-centric and impactful recommender systems. While the paper does not address all potential limitations, it represents an important step forward in the ongoing effort to enhance the user experience in recommender systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
UOEP: User-Oriented Exploration Policy for Enhancing Long-Term User Experiences in Recommender Systems
Changshuo Zhang, Sirui Chen, Xiao Zhang, Sunhao Dai, Weijie Yu, Jun Xu
Reinforcement learning (RL) has gained traction for enhancing user long-term experiences in recommender systems by effectively exploring users' interests. However, modern recommender systems exhibit distinct user behavioral patterns among tens of millions of items, which increases the difficulty of exploration. For example, user behaviors with different activity levels require varying intensity of exploration, while previous studies often overlook this aspect and apply a uniform exploration strategy to all users, which ultimately hurts user experiences in the long run. To address these challenges, we propose User-Oriented Exploration Policy (UOEP), a novel approach facilitating fine-grained exploration among user groups. We first construct a distributional critic which allows policy optimization under varying quantile levels of cumulative reward feedbacks from users, representing user groups with varying activity levels. Guided by this critic, we devise a population of distinct actors aimed at effective and fine-grained exploration within its respective user group. To simultaneously enhance diversity and stability during the exploration process, we further introduce a population-level diversity regularization term and a supervision module. Experimental results on public recommendation datasets demonstrate that our approach outperforms all other baselines in terms of long-term performance, validating its user-oriented exploration effectiveness. Meanwhile, further analyses reveal our approach's benefits of improved performance for low-activity users as well as increased fairness among users.
Read more5/24/2024
0
An Efficient Continuous Control Perspective for Reinforcement-Learning-based Sequential Recommendation
Jun Wang, Likang Wu, Qi Liu, Yu Yang
Sequential recommendation, where user preference is dynamically inferred from sequential historical behaviors, is a critical task in recommender systems (RSs). To further optimize long-term user engagement, offline reinforcement-learning-based RSs have become a mainstream technique as they provide an additional advantage in avoiding global explorations that may harm online users' experiences. However, previous studies mainly focus on discrete action and policy spaces, which might have difficulties in handling dramatically growing items efficiently. To mitigate this issue, in this paper, we aim to design an algorithmic framework applicable to continuous policies. To facilitate the control in the low-dimensional but dense user preference space, we propose an underline{textbf{E}}fficient underline{textbf{Co}}ntinuous underline{textbf{C}}ontrol framework (ECoC). Based on a statistically tested assumption, we first propose the novel unified action representation abstracted from normalized user and item spaces. Then, we develop the corresponding policy evaluation and policy improvement procedures. During this process, strategic exploration and directional control in terms of unified actions are carefully designed and crucial to final recommendation decisions. Moreover, beneficial from unified actions, the conservatism regularization for policies and value functions are combined and perfectly compatible with the continuous framework. The resulting dual regularization ensures the successful offline training of RL-based recommendation policies. Finally, we conduct extensive experiments to validate the effectiveness of our framework. The results show that compared to the discrete baselines, our ECoC is trained far more efficiently. Meanwhile, the final policies outperform baselines in both capturing the offline data and gaining long-term rewards.
Read more8/16/2024

0
On-policy Actor-Critic Reinforcement Learning for Multi-UAV Exploration
Ali Moltajaei Farid, Jafar Roshanian, Malek Mouhoub
Unmanned aerial vehicles (UAVs) have become increasingly popular in various fields, including precision agriculture, search and rescue, and remote sensing. However, exploring unknown environments remains a significant challenge. This study aims to address this challenge by utilizing on-policy Reinforcement Learning (RL) with Proximal Policy Optimization (PPO) to explore the {two dimensional} area of interest with multiple UAVs. The UAVs will avoid collision with obstacles and each other and do the exploration in a distributed manner. The proposed solution includes actor-critic networks using deep convolutional neural networks {(CNN)} and long short-term memory (LSTM) for identifying the UAVs and areas that have already been covered. Compared to other RL techniques, such as policy gradient (PG) and asynchronous advantage actor-critic (A3C), the simulation results demonstrate the superiority of the proposed PPO approach. Also, the results show that combining LSTM with CNN in critic can improve exploration. Since the proposed exploration has to work in unknown environments, the results showed that the proposed setup can complete the coverage when we have new maps that differ from the trained maps. Finally, we showed how tuning hyper parameters may affect the overall performance.
Read more9/18/2024

0
Preference-Guided Reinforcement Learning for Efficient Exploration
Guojian Wang, Faguo Wu, Xiao Zhang, Tianyuan Chen, Xuyang Chen, Lin Zhao
In this paper, we investigate preference-based reinforcement learning (PbRL) that allows reinforcement learning (RL) agents to learn from human feedback. This is particularly valuable when defining a fine-grain reward function is not feasible. However, this approach is inefficient and impractical for promoting deep exploration in hard-exploration tasks with long horizons and sparse rewards. To tackle this issue, we introduce LOPE: Learning Online with trajectory Preference guidancE, an end-to-end preference-guided RL framework that enhances exploration efficiency in hard-exploration tasks. Our intuition is that LOPE directly adjusts the focus of online exploration by considering human feedback as guidance, avoiding learning a separate reward model from preferences. Specifically, LOPE includes a two-step sequential policy optimization process consisting of trust-region-based policy improvement and preference guidance steps. We reformulate preference guidance as a novel trajectory-wise state marginal matching problem that minimizes the maximum mean discrepancy distance between the preferred trajectories and the learned policy. Furthermore, we provide a theoretical analysis to characterize the performance improvement bound and evaluate the LOPE's effectiveness. When assessed in various challenging hard-exploration environments, LOPE outperforms several state-of-the-art methods regarding convergence rate and overall performance. The code used in this study is available at url{https://github.com/buaawgj/LOPE}.
Read more7/10/2024