Ranking-based Client Selection with Imitation Learning for Efficient Federated Learning

0

Sign in to get full access
Overview
- Proposes a ranking-based client selection method using imitation learning for federated learning
- Aims to improve the efficiency and performance of federated learning by selecting the most relevant clients to participate in each round
- Leverages imitation learning to mimic the behavior of an oracle client selector, which selects clients based on their potential contribution to the global model
Plain English Explanation
Federated learning is a machine learning technique where multiple devices or clients collaborate to train a shared model without sharing their raw data. This can be more efficient than centralizing all the data, but it comes with the challenge of selecting the right clients to participate in each training round.
The paper introduces a new approach that uses ranking-based client selection with imitation learning to address this challenge. The key idea is to train a machine learning model that can mimic the behavior of an "oracle" client selector - an ideal system that knows exactly which clients would be most valuable to include in each round.
By learning from this oracle, the proposed technique can efficiently select the best clients without needing to fully understand the complex factors that contribute to a client's value. This helps make federated learning more efficient and effective, as it focuses the training on the most relevant data sources.
The paper demonstrates the benefits of this approach through experiments, showing that it can outperform other client selection methods in terms of model performance and training efficiency.
Technical Explanation
The paper proposes a ranking-based client selection method for federated learning that uses imitation learning to mimic an oracle client selector.
The oracle client selector is assumed to have perfect knowledge of each client's potential contribution to the global model. In practice, this information is not available, so the key idea is to train a machine learning model to approximate the oracle's client rankings.
Specifically, the authors train a neural network-based ranking model that takes in features about each client (e.g., data quality, device capabilities) and outputs a ranking score. This ranking model is trained using imitation learning, where the goal is to match the oracle's rankings as closely as possible.
Once trained, this ranking model can be used to efficiently select the top-k clients to participate in each federated learning round, without needing to fully understand the complex factors that determine a client's value.
The paper evaluates this approach on several federated learning benchmarks, comparing it to other client selection strategies like random selection and uncertainty-based selection. The results show that the proposed ranking-based client selection with imitation learning can lead to significant improvements in model performance and training efficiency.
Critical Analysis
The paper presents a novel and promising approach for improving the efficiency of federated learning through adaptive and heterogeneous client selection. The key strengths of the work include:
- Addressing a critical challenge: Client selection is a crucial but often overlooked aspect of federated learning, and the proposed approach provides a principled way to tackle this problem.
- Leveraging imitation learning: The use of imitation learning to mimic an oracle selector is a clever and effective way to approximate an ideal client selection strategy without full information.
- Empirical evidence: The experimental results demonstrating the benefits of the proposed method are compelling and help validate the approach.
However, the paper also has some limitations and areas for further research:
- Reliance on an oracle: The performance of the imitation learning approach is inherently limited by the quality of the oracle client selector, which may be difficult to obtain in practice.
- Scalability: The paper does not extensively explore the scalability of the approach to large-scale federated learning systems with many clients.
- Real-world applicability: While the experiments use standard federated learning benchmarks, more work may be needed to understand how the approach would perform in real-world federated learning deployments with diverse client characteristics and evolving data distributions.
Overall, the paper presents a promising direction for enhancing the efficiency and adaptability of federated learning and should inspire further research in this important area.
Conclusion
This paper introduces a novel ranking-based client selection method using imitation learning for federated learning. By training a model to mimic the behavior of an oracle client selector, the approach can efficiently select the most relevant clients to participate in each round of federated training, leading to improved model performance and training efficiency.
The key innovation is the use of imitation learning to approximate an ideal client selection strategy without full information about each client's potential contribution. This allows the method to be deployed in practical federated learning settings where the complex factors governing client value are not fully known.
The experimental results demonstrate the benefits of this approach, and the paper highlights important directions for future research to further enhance the scalability and real-world applicability of federated learning systems. Overall, this work represents an important step forward in making federated learning more efficient and effective for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Ranking-based Client Selection with Imitation Learning for Efficient Federated Learning
Chunlin Tian, Zhan Shi, Xinpeng Qin, Li Li, Chengzhong Xu
Federated Learning (FL) enables multiple devices to collaboratively train a shared model while ensuring data privacy. The selection of participating devices in each training round critically affects both the model performance and training efficiency, especially given the vast heterogeneity in training capabilities and data distribution across devices. To address these challenges, we introduce a novel device selection solution called FedRank, which is an end-to-end, ranking-based approach that is pre-trained by imitation learning against state-of-the-art analytical approaches. It not only considers data and system heterogeneity at runtime but also adaptively and efficiently chooses the most suitable clients for model training. Specifically, FedRank views client selection in FL as a ranking problem and employs a pairwise training strategy for the smart selection process. Additionally, an imitation learning-based approach is designed to counteract the cold-start issues often seen in state-of-the-art learning-based approaches. Experimental results reveal that model~ boosts model accuracy by 5.2% to 56.9%, accelerates the training convergence up to $2.01 times$ and saves the energy consumption up to $40.1%$.
Read more5/8/2024
📊
0
Enhancing Efficiency in Multidevice Federated Learning through Data Selection
Fan Mo, Mohammad Malekzadeh, Soumyajit Chatterjee, Fahim Kawsar, Akhil Mathur
Federated learning (FL) in multidevice environments creates new opportunities to learn from a vast and diverse amount of private data. Although personal devices capture valuable data, their memory, computing, connectivity, and battery resources are often limited. Since deep neural networks (DNNs) are the typical machine learning models employed in FL, there are demands for integrating ubiquitous constrained devices into the training process of DNNs. In this paper, we develop an FL framework to incorporate on-device data selection on such constrained devices, which allows partition-based training of a DNN through collaboration between constrained devices and resourceful devices of the same client. Evaluations on five benchmark DNNs and six benchmark datasets across different modalities show that, on average, our framework achieves ~19% higher accuracy and ~58% lower latency; compared to the baseline FL without our implemented strategies. We demonstrate the effectiveness of our FL framework when dealing with imbalanced data, client participation heterogeneity, and various mobility patterns. As a benchmark for the community, our code is available at https://github.com/dr-bell/data-centric-federated-learning
Read more4/11/2024

0
Efficient Data Distribution Estimation for Accelerated Federated Learning
Yuanli Wang, Lei Huang
Federated Learning(FL) is a privacy-preserving machine learning paradigm where a global model is trained in-situ across a large number of distributed edge devices. These systems are often comprised of millions of user devices and only a subset of available devices can be used for training in each epoch. Designing a device selection strategy is challenging, given that devices are highly heterogeneous in both their system resources and training data. This heterogeneity makes device selection very crucial for timely model convergence and sufficient model accuracy. To tackle the FL client heterogeneity problem, various client selection algorithms have been developed, showing promising performance improvement in terms of model coverage and accuracy. In this work, we study the overhead of client selection algorithms in a large scale FL environment. Then we propose an efficient data distribution summary calculation algorithm to reduce the overhead in a real-world large scale FL environment. The evaluation shows that our proposed solution could achieve up to 30x reduction in data summary time, and up to 360x reduction in clustering time.
Read more6/5/2024
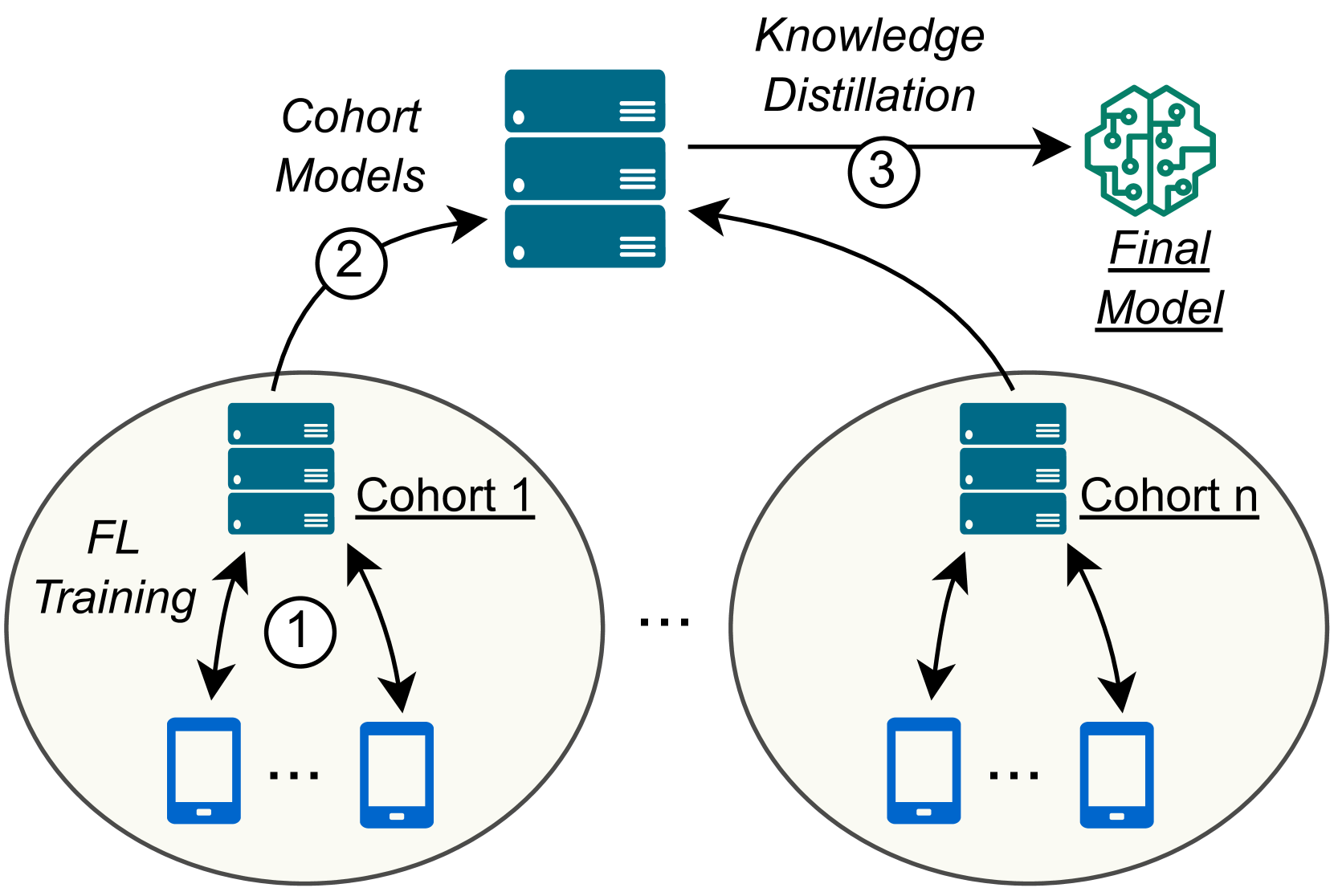
0
Harnessing Increased Client Participation with Cohort-Parallel Federated Learning
Akash Dhasade, Anne-Marie Kermarrec, Tuan-Anh Nguyen, Rafael Pires, Martijn de Vos
Federated Learning (FL) is a machine learning approach where nodes collaboratively train a global model. As more nodes participate in a round of FL, the effectiveness of individual model updates by nodes also diminishes. In this study, we increase the effectiveness of client updates by dividing the network into smaller partitions, or cohorts. We introduce Cohort-Parallel Federated Learning (CPFL): a novel learning approach where each cohort independently trains a global model using FL, until convergence, and the produced models by each cohort are then unified using one-shot Knowledge Distillation (KD) and a cross-domain, unlabeled dataset. The insight behind CPFL is that smaller, isolated networks converge quicker than in a one-network setting where all nodes participate. Through exhaustive experiments involving realistic traces and non-IID data distributions on the CIFAR-10 and FEMNIST image classification tasks, we investigate the balance between the number of cohorts, model accuracy, training time, and compute and communication resources. Compared to traditional FL, CPFL with four cohorts, non-IID data distribution, and CIFAR-10 yields a 1.9$times$ reduction in train time and a 1.3$times$ reduction in resource usage, with a minimal drop in test accuracy.
Read more5/27/2024