Efficient Exploration for LLMs

0
❗
Sign in to get full access
Overview
- The paper presents evidence of substantial benefits from efficient exploration in gathering human feedback to improve large language models.
- The proposed agent sequentially generates queries while fitting a reward model to the feedback received.
- The best-performing agent uses double Thompson sampling with uncertainty represented by an epistemic neural network.
- The results demonstrate that efficient exploration enables high levels of performance with far fewer queries.
- Both uncertainty estimation and the choice of exploration scheme play critical roles.
Plain English Explanation
The researchers conducted experiments to see how an agent could effectively learn from human feedback to improve a large language model. They developed an agent that generates questions or "queries" and then uses the feedback it receives to update its understanding of what kinds of responses are desirable.
The most successful version of the agent used a technique called "double Thompson sampling" to decide which queries to ask next. This means the agent maintains an estimate of the uncertainty in its own understanding, and uses that to balance exploration (asking questions to reduce uncertainty) and exploitation (asking questions it expects will get good feedback).
The key finding is that this efficient exploration approach allowed the agent to achieve high performance with far fewer queries compared to other methods. In other words, it was able to learn a lot from a limited amount of human feedback. The researchers also found that properly modeling the agent's uncertainty, and the specific exploration strategy used, were both crucial to this success.
This work has important implications for improving the performance of large language models using limited human feedback, a challenging but important problem. By using efficient exploration techniques, it may be possible to train highly capable language models with much less manual labeling or oversight.
Technical Explanation
The paper describes experiments evaluating different approaches for an agent to sequentially generate queries while fitting a reward model to the feedback received. The goal is to maximize the agent's performance on some objective function using as few queries as possible.
The researchers tested several schemes for the agent to decide which queries to ask next, including random sampling, upper confidence bound (UCB) exploration, and double Thompson sampling. Double Thompson sampling involves maintaining both a point estimate and an uncertainty estimate for the reward function, and using both to stochastically select the next query.
The uncertainty estimate was represented using an epistemic neural network - a neural network that outputs not just a prediction, but also an estimate of its own uncertainty about that prediction. This allows the agent to balance exploration (querying to reduce uncertainty) and exploitation (querying to maximize expected reward).
The results demonstrate that the double Thompson sampling agent with epistemic uncertainty achieves substantially higher performance than the alternatives, using far fewer queries. This highlights the critical importance of both uncertainty estimation and the choice of exploration scheme when training models from limited feedback, as discussed in related work on enhancing Q-learning with large language model heuristics and efficient reinforcement learning via large language models.
Critical Analysis
The paper provides a promising demonstration of the benefits of efficient exploration when training models from human feedback. However, the experiments are limited to a single task and dataset, so further research is needed to assess the generalizability of the findings.
Additionally, the paper does not discuss potential limitations or risks of this approach. For example, the agent's queries could potentially be biased or adversarial, leading to misleading feedback and suboptimal model performance, as discussed in work on weak exploration leading to strong exploitation.
There are also open questions about the computational and sample efficiency of the epistemic neural network approach compared to other uncertainty estimation techniques, and how these methods scale to very large language models. A comprehensive survey of efficient large language models could provide helpful context.
Overall, this work represents an important step forward in efficiently generating hypotheses for large language models using limited feedback. With further research and refinement, these techniques could enable significant performance gains with much less human oversight.
Conclusion
This paper presents a novel approach for efficiently training large language models using human feedback. By maintaining an estimate of the agent's own uncertainty and using that to guide its query selection, the researchers were able to achieve high performance with far fewer queries compared to other exploration methods.
These findings have important implications for reducing the manual effort required to fine-tune or adapt large language models for specific tasks or domains. If this type of efficient exploration can be scaled to very large models, it could enable the development of highly capable AI systems with much less human labeling or oversight. This could unlock new applications and benefits for language AI technology.
However, further research is needed to assess the broader applicability of this approach and address potential limitations or risks. Nonetheless, this work represents a promising step forward in the quest to build powerful yet sample-efficient language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
❗
0
Efficient Exploration for LLMs
Vikranth Dwaracherla, Seyed Mohammad Asghari, Botao Hao, Benjamin Van Roy
We present evidence of substantial benefit from efficient exploration in gathering human feedback to improve large language models. In our experiments, an agent sequentially generates queries while fitting a reward model to the feedback received. Our best-performing agent generates queries using double Thompson sampling, with uncertainty represented by an epistemic neural network. Our results demonstrate that efficient exploration enables high levels of performance with far fewer queries. Further, both uncertainty estimation and the choice of exploration scheme play critical roles.
Read more6/6/2024

0
Can large language models explore in-context?
Akshay Krishnamurthy, Keegan Harris, Dylan J. Foster, Cyril Zhang, Aleksandrs Slivkins
We investigate the extent to which contemporary Large Language Models (LLMs) can engage in exploration, a core capability in reinforcement learning and decision making. We focus on native performance of existing LLMs, without training interventions. We deploy LLMs as agents in simple multi-armed bandit environments, specifying the environment description and interaction history entirely in-context, i.e., within the LLM prompt. We experiment with GPT-3.5, GPT-4, and Llama2, using a variety of prompt designs, and find that the models do not robustly engage in exploration without substantial interventions: i) Across all of our experiments, only one configuration resulted in satisfactory exploratory behavior: GPT-4 with chain-of-thought reasoning and an externally summarized interaction history, presented as sufficient statistics; ii) All other configurations did not result in robust exploratory behavior, including those with chain-of-thought reasoning but unsummarized history. Although these findings can be interpreted positively, they suggest that external summarization -- which may not be possible in more complex settings -- is important for obtaining desirable behavior from LLM agents. We conclude that non-trivial algorithmic interventions, such as fine-tuning or dataset curation, may be required to empower LLM-based decision making agents in complex settings.
Read more7/15/2024
💬
0
Enhancing Exploratory Learning through Exploratory Search with the Emergence of Large Language Models
Yiming Luo, Patrick Cheong-Iao, Shanton Chang
In the information era, how learners find, evaluate, and effectively use information has become a challenging issue, especially with the added complexity of large language models (LLMs) that have further confused learners in their information retrieval and search activities. This study attempts to unpack this complexity by combining exploratory search strategies with the theories of exploratory learning to form a new theoretical model of exploratory learning from the perspective of students' learning. Our work adapts Kolb's learning model by incorporating high-frequency exploration and feedback loops, aiming to promote deep cognitive and higher-order cognitive skill development in students. Additionally, this paper discusses and suggests how advanced LLMs integrated into information retrieval and information theory can support students in their exploratory searches, contributing theoretically to promoting student-computer interaction and supporting their learning journeys in the new era with LLMs.
Read more8/20/2024
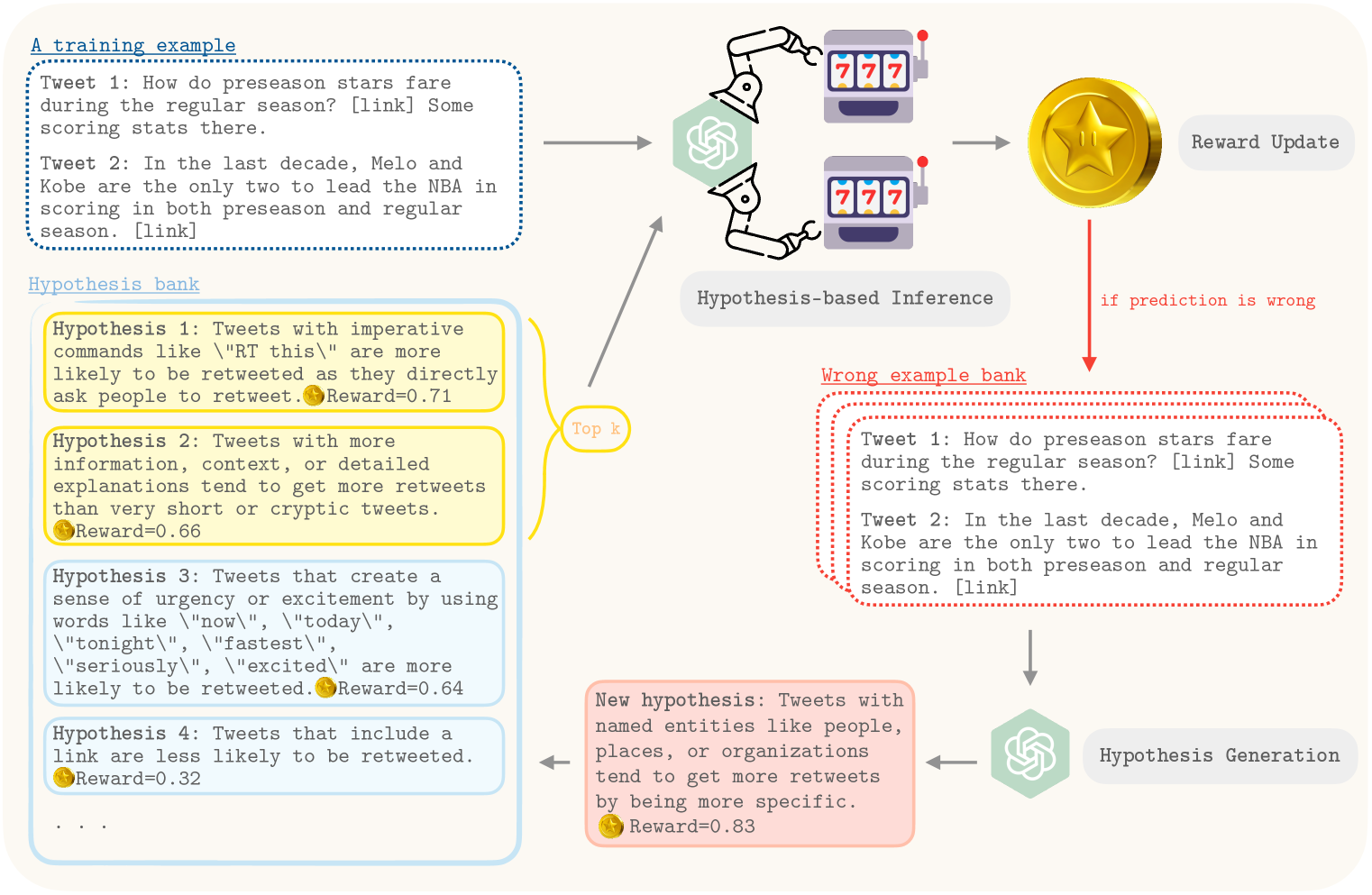
0
Hypothesis Generation with Large Language Models
Yangqiaoyu Zhou, Haokun Liu, Tejes Srivastava, Hongyuan Mei, Chenhao Tan
Effective generation of novel hypotheses is instrumental to scientific progress. So far, researchers have been the main powerhouse behind hypothesis generation by painstaking data analysis and thinking (also known as the Eureka moment). In this paper, we examine the potential of large language models (LLMs) to generate hypotheses. We focus on hypothesis generation based on data (i.e., labeled examples). To enable LLMs to handle arbitrarily long contexts, we generate initial hypotheses from a small number of examples and then update them iteratively to improve the quality of hypotheses. Inspired by multi-armed bandits, we design a reward function to inform the exploitation-exploration tradeoff in the update process. Our algorithm is able to generate hypotheses that enable much better predictive performance than few-shot prompting in classification tasks, improving accuracy by 31.7% on a synthetic dataset and by 13.9%, 3.3% and, 24.9% on three real-world datasets. We also outperform supervised learning by 12.8% and 11.2% on two challenging real-world datasets. Furthermore, we find that the generated hypotheses not only corroborate human-verified theories but also uncover new insights for the tasks.
Read more8/27/2024