Can large language models explore in-context?

0

Sign in to get full access
Overview
- This paper explores whether large language models (LLMs) can "explore in-context" - i.e., whether they can effectively solve novel problems by dynamically generating and evaluating different approaches within a given context, rather than relying solely on memorized responses.
- The researchers conducted experiments to test the in-context exploration capabilities of LLMs across a variety of problem-solving tasks.
- The findings provide insights into the strengths and limitations of LLMs' ability to engage in flexible, contextual reasoning and problem-solving.
Plain English Explanation
Large language models (LLMs) like GPT-3 have shown impressive abilities in tasks like answering questions, generating text, and even completing complex prompts. But can these models truly explore and reason about new problems dynamically, or do they mainly rely on recalling and regurgitating memorized responses?
This paper set out to investigate whether LLMs can "explore in-context" - that is, whether they can generate and evaluate different approaches to solving a problem, all within the context of the original prompt, rather than just returning a single pre-programmed answer. The researchers designed a series of experiments to test this, covering a range of problem-solving tasks like link to "Evaluating Interventional Reasoning Capabilities of Large Language Models" and link to "Mental Modeling: Reinforcement Learning Agents by Language".
The results suggest that while LLMs can show some ability to explore problem-solving approaches in-context, they still have significant limitations. They tend to get stuck in local optima or repeat the same unsuccessful strategies, rather than dynamically exploring a wider range of possibilities. This points to shortcomings in the models' capacity for flexible, contextual reasoning.
Nevertheless, the researchers believe that with further advancements, LLMs could one day become powerful "problem-solving engines" that can creatively tackle novel challenges. This could have important implications for fields like link to "Reinforcement Learning for Problem-Solving in Large Language Models" and link to "Large Language Model as Policy Teacher for Training", where AI systems need to be able to reason dynamically about complex problems.
Technical Explanation
The paper begins by noting that while LLMs have demonstrated impressive performance on a wide range of language tasks, it remains unclear whether they can truly "explore in-context" - that is, whether they can dynamically generate and evaluate different problem-solving approaches within a given context, rather than simply recalling and regurgitating memorized responses.
To investigate this, the researchers designed a series of experiments to assess LLMs' in-context exploration capabilities across various problem-solving tasks. This included tasks like link to "From Words to Actions: Unveiling the Theoretical Underpinnings", where the model had to propose and evaluate different strategies for accomplishing a given goal.
The experiments used a variety of baseline models and prompting techniques as comparisons, in order to isolate the LLMs' innate in-context exploration abilities. The researchers also carefully analyzed the models' generated outputs to understand the underlying thought processes and strategies being employed.
The findings suggest that while LLMs can demonstrate some capacity for in-context exploration, they often get stuck in local optima or repeat the same unsuccessful approaches, rather than dynamically exploring a wider range of possibilities. This points to limitations in the models' ability to engage in flexible, contextual reasoning and problem-solving.
However, the researchers believe that with further advancements, LLMs could potentially become powerful "problem-solving engines" capable of creatively tackling novel challenges. They suggest that continued research in this area, including the development of new architectural and training approaches, could help unlock the full potential of LLMs for flexible, contextual reasoning.
Critical Analysis
The paper provides a thoughtful and well-designed investigation into the in-context exploration capabilities of LLMs. The researchers have carefully crafted a series of experiments to isolate and assess this specific ability, which is an important step in understanding the strengths and limitations of these powerful language models.
That said, the findings do reveal significant constraints in LLMs' ability to dynamically explore problem-solving approaches. The tendency to get stuck in local optima and repeat unsuccessful strategies suggests shortcomings in their capacity for flexible, contextual reasoning. This is an important limitation that should be further explored and addressed.
Additionally, the paper acknowledges that the experiments were conducted on a relatively narrow set of problem-solving tasks. It would be valuable to see the researchers expand their investigation to a wider range of domains and problem types, to better understand the generalizability of the results.
Another potential avenue for future research could be to investigate the role of model scale, architecture, and training data in shaping in-context exploration capabilities. As the researchers note, continued advancements in these areas may unlock new breakthroughs in LLMs' problem-solving abilities.
Overall, this paper makes a valuable contribution to our understanding of LLMs' capabilities and limitations. By rigorously exploring the boundaries of their in-context exploration, the researchers have shed light on important considerations for the development of truly flexible, contextual AI systems.
Conclusion
This paper provides a detailed investigation into whether large language models (LLMs) can effectively "explore in-context" - that is, whether they can dynamically generate and evaluate different problem-solving approaches within a given context, rather than relying solely on memorized responses.
The findings suggest that while LLMs can demonstrate some capacity for in-context exploration, they often get stuck in local optima or repeat unsuccessful strategies, rather than flexibly exploring a wider range of possibilities. This points to limitations in the models' ability to engage in dynamic, contextual reasoning.
However, the researchers believe that with continued advancements in model architecture, training techniques, and scale, LLMs could one day become powerful "problem-solving engines" capable of creatively tackling novel challenges. This could have important implications for fields like reinforcement learning and mental modeling, where AI systems need to reason flexibly about complex problems.
Overall, this paper makes a valuable contribution to our understanding of LLMs' capabilities and limitations, and highlights the importance of further research to unlock the full potential of these powerful language models for flexible, contextual reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Can large language models explore in-context?
Akshay Krishnamurthy, Keegan Harris, Dylan J. Foster, Cyril Zhang, Aleksandrs Slivkins
We investigate the extent to which contemporary Large Language Models (LLMs) can engage in exploration, a core capability in reinforcement learning and decision making. We focus on native performance of existing LLMs, without training interventions. We deploy LLMs as agents in simple multi-armed bandit environments, specifying the environment description and interaction history entirely in-context, i.e., within the LLM prompt. We experiment with GPT-3.5, GPT-4, and Llama2, using a variety of prompt designs, and find that the models do not robustly engage in exploration without substantial interventions: i) Across all of our experiments, only one configuration resulted in satisfactory exploratory behavior: GPT-4 with chain-of-thought reasoning and an externally summarized interaction history, presented as sufficient statistics; ii) All other configurations did not result in robust exploratory behavior, including those with chain-of-thought reasoning but unsummarized history. Although these findings can be interpreted positively, they suggest that external summarization -- which may not be possible in more complex settings -- is important for obtaining desirable behavior from LLM agents. We conclude that non-trivial algorithmic interventions, such as fine-tuning or dataset curation, may be required to empower LLM-based decision making agents in complex settings.
Read more7/15/2024
0
Reinforcement Learning Problem Solving with Large Language Models
Sina Gholamian, Domingo Huh
Large Language Models (LLMs) encapsulate an extensive amount of world knowledge, and this has enabled their application in various domains to improve the performance of a variety of Natural Language Processing (NLP) tasks. This has also facilitated a more accessible paradigm of conversation-based interactions between humans and AI systems to solve intended problems. However, one interesting avenue that shows untapped potential is the use of LLMs as Reinforcement Learning (RL) agents to enable conversational RL problem solving. Therefore, in this study, we explore the concept of formulating Markov Decision Process-based RL problems as LLM prompting tasks. We demonstrate how LLMs can be iteratively prompted to learn and optimize policies for specific RL tasks. In addition, we leverage the introduced prompting technique for episode simulation and Q-Learning, facilitated by LLMs. We then show the practicality of our approach through two detailed case studies for Research Scientist and Legal Matter Intake workflows.
Read more4/30/2024
💬
0
Large Language Model as a Policy Teacher for Training Reinforcement Learning Agents
Zihao Zhou, Bin Hu, Chenyang Zhao, Pu Zhang, Bin Liu
Recent studies have uncovered the potential of Large Language Models (LLMs) in addressing complex sequential decision-making tasks through the provision of high-level instructions. However, LLM-based agents lack specialization in tackling specific target problems, particularly in real-time dynamic environments. Additionally, deploying an LLM-based agent in practical scenarios can be both costly and time-consuming. On the other hand, reinforcement learning (RL) approaches train agents that specialize in the target task but often suffer from low sampling efficiency and high exploration costs. In this paper, we introduce a novel framework that addresses these challenges by training a smaller, specialized student RL agent using instructions from an LLM-based teacher agent. By incorporating the guidance from the teacher agent, the student agent can distill the prior knowledge of the LLM into its own model. Consequently, the student agent can be trained with significantly less data. Moreover, through further training with environment feedback, the student agent surpasses the capabilities of its teacher for completing the target task. We conducted experiments on challenging MiniGrid and Habitat environments, specifically designed for embodied AI research, to evaluate the effectiveness of our framework. The results clearly demonstrate that our approach achieves superior performance compared to strong baseline methods. Our code is available at https://github.com/ZJLAB-AMMI/LLM4Teach.
Read more4/23/2024
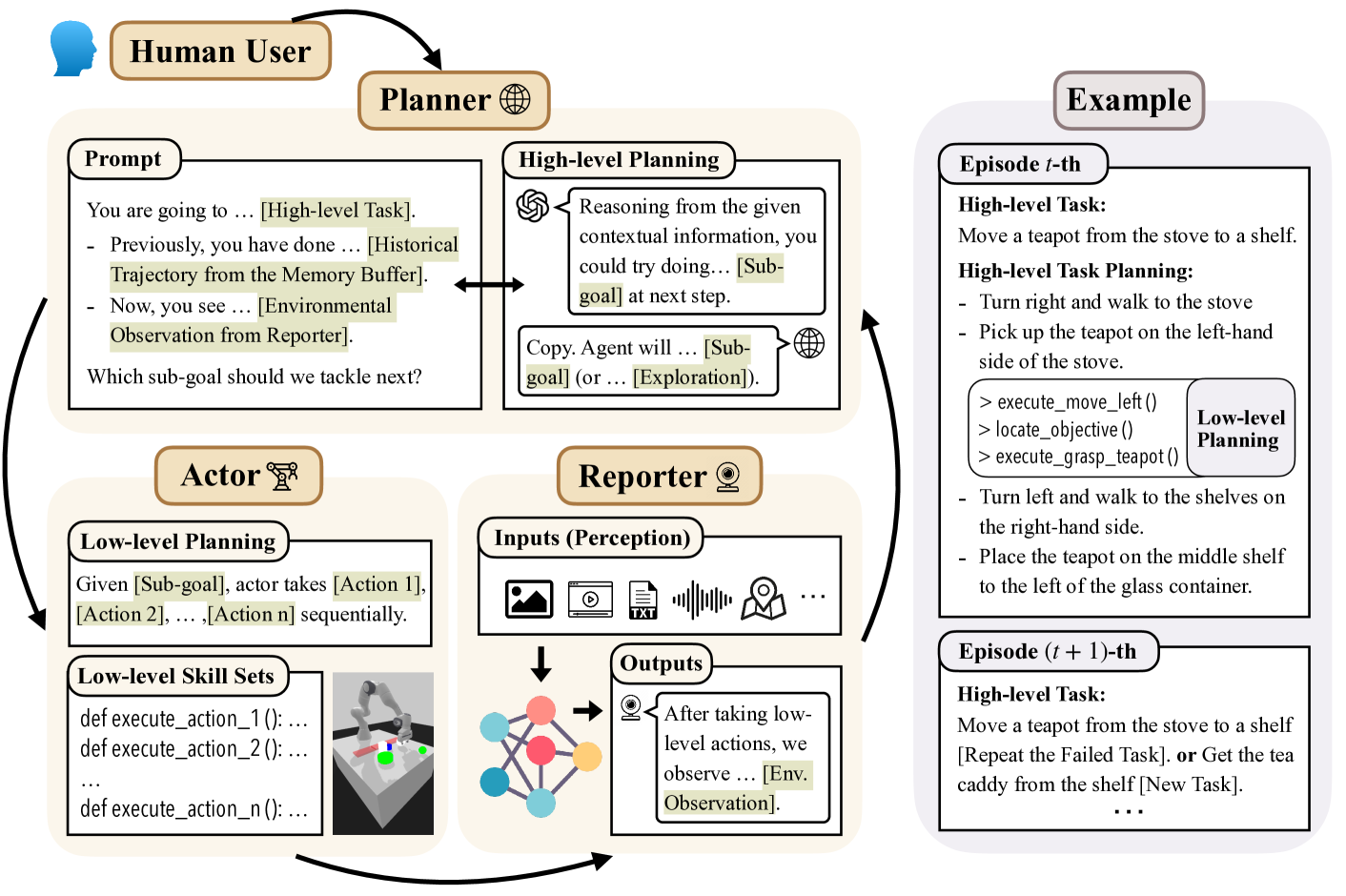
0
From Words to Actions: Unveiling the Theoretical Underpinnings of LLM-Driven Autonomous Systems
Jianliang He, Siyu Chen, Fengzhuo Zhang, Zhuoran Yang
In this work, from a theoretical lens, we aim to understand why large language model (LLM) empowered agents are able to solve decision-making problems in the physical world. To this end, consider a hierarchical reinforcement learning (RL) model where the LLM Planner and the Actor perform high-level task planning and low-level execution, respectively. Under this model, the LLM Planner navigates a partially observable Markov decision process (POMDP) by iteratively generating language-based subgoals via prompting. Under proper assumptions on the pretraining data, we prove that the pretrained LLM Planner effectively performs Bayesian aggregated imitation learning (BAIL) through in-context learning. Additionally, we highlight the necessity for exploration beyond the subgoals derived from BAIL by proving that naively executing the subgoals returned by LLM leads to a linear regret. As a remedy, we introduce an $epsilon$-greedy exploration strategy to BAIL, which is proven to incur sublinear regret when the pretraining error is small. Finally, we extend our theoretical framework to include scenarios where the LLM Planner serves as a world model for inferring the transition model of the environment and to multi-agent settings, enabling coordination among multiple Actors.
Read more7/23/2024