Efficient Fine-Tuning of Large Language Models for Automated Medical Documentation

0
💬
Sign in to get full access
Overview
- Physicians spend nearly 2 hours on administrative tasks for every 1 hour of direct patient care
- This administrative burden reduces time for patient care and contributes to physician burnout
- To address this, the study introduces MediGen, a language model designed to automate medical report generation from dialogues
- MediGen achieved high accuracy in transcribing and summarizing clinical interactions
Plain English Explanation
Doctors today spend a lot of time on paperwork and electronic health records instead of seeing patients. This administrative burden not only takes away from patient care, but also contributes to physician burnout. To help solve this problem, the researchers developed a system called MediGen that can automatically generate medical reports from conversations between doctors and patients.
MediGen uses advanced language models that have been specially trained on medical data. This allows MediGen to accurately transcribe and summarize clinical interactions, producing detailed reports. The researchers showed that MediGen can do this task very well, getting high scores on industry-standard evaluation metrics.
The hope is that by automating this administrative work, MediGen can free up doctors to spend more time with patients, improving both healthcare efficiency and physician well-being. This could be a valuable tool for reducing the administrative burden on doctors.
Technical Explanation
The researchers fine-tuned a large language model (LLM) called LLaMA3-8B to create MediGen, a system designed to automatically generate medical reports from clinical dialogues. By leveraging state-of-the-art fine-tuning techniques on this large, pre-trained model, MediGen achieved high performance on the task.
In their experiments, the fine-tuned MediGen model demonstrated a ROUGE score of 58% and a BERTScore-F1 of 72% when evaluated on medical report generation. These metrics indicate the model is able to produce accurate and clinically relevant summaries of medical interactions.
The researchers note that this level of performance has the potential to significantly reduce the administrative burden on physicians, freeing up more time for direct patient care. This could in turn improve both healthcare efficiency and physician well-being by mitigating factors that contribute to burnout.
Critical Analysis
While the results presented are promising, the researchers acknowledge several caveats and limitations to their work. For example, the study was conducted on a relatively small dataset of medical dialogues, and further testing on larger, more diverse datasets would be needed to fully validate the model's capabilities.
Additionally, the researchers do not address potential issues around data privacy and security when deploying a language model like MediGen in a clinical setting. Safeguards would need to be put in place to ensure patient confidentiality is protected.
It will also be important to carefully monitor for any bias or errors introduced by the model, as incorrect medical reporting could have serious consequences for patient care. Ongoing evaluation and refinement of the model will be crucial.
Conclusion
This study introduces a promising approach to reducing the administrative burden on physicians through the use of a fine-tuned language model, MediGen. By automating the generation of medical reports from clinical dialogues, MediGen has the potential to free up more time for direct patient care and mitigate factors contributing to physician burnout.
While further research is needed to fully validate the model's capabilities and address potential limitations, the high performance demonstrated by MediGen suggests it could be a valuable tool for improving healthcare efficiency and supporting the well-being of medical professionals.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Efficient Fine-Tuning of Large Language Models for Automated Medical Documentation
Hui Yi Leong, Yi Fan Gao, Ji Shuai, Uktu Pamuksuz
Scientific research indicates that for every hour spent in direct patient care, physicians spend nearly two additional hours on administrative tasks, particularly on electronic health records (EHRs) and desk work. This excessive administrative burden not only reduces the time available for patient care but also contributes to physician burnout and inefficiencies in healthcare delivery. To address these challenges, this study introduces MediGen, a fine-tuned large language model (LLM) designed to automate the generation of medical reports from medical dialogues. By leveraging state-of-the-art methodologies for fine-tuning open-source pretrained models, including LLaMA3-8B, MediGen achieves high accuracy in transcribing and summarizing clinical interactions. The fine-tuned LLaMA3-8B model demonstrated promising results, achieving a ROUGE score of 58% and a BERTScore-F1 of 72%, indicating its effectiveness in generating accurate and clinically relevant medical reports. These findings suggest that MediGen has the potential to significantly reduce the administrative workload on physicians, improving both healthcare efficiency and physician well-being.
Read more9/17/2024
0
Towards Adapting Open-Source Large Language Models for Expert-Level Clinical Note Generation
Hanyin Wang, Chufan Gao, Bolun Liu, Qiping Xu, Guleid Hussein, Mohamad El Labban, Kingsley Iheasirim, Hariprasad Korsapati, Chuck Outcalt, Jimeng Sun
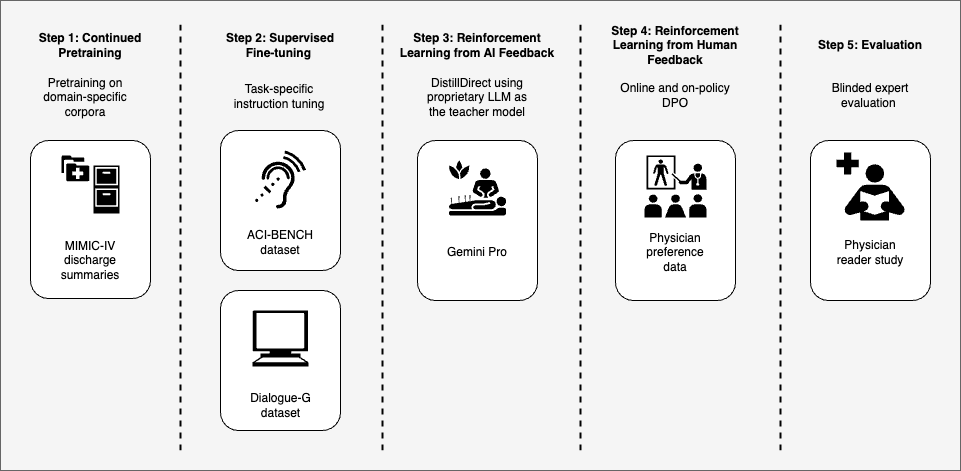
Proprietary Large Language Models (LLMs) such as GPT-4 and Gemini have demonstrated promising capabilities in clinical text summarization tasks. However, due to patient data privacy concerns and computational costs, many healthcare providers prefer using small, locally-hosted models over external generic LLMs. This study presents a comprehensive domain- and task-specific adaptation process for the open-source LLaMA-2 13 billion parameter model, enabling it to generate high-quality clinical notes from outpatient patient-doctor dialogues. Our process incorporates continued pre-training, supervised fine-tuning, and reinforcement learning from both AI and human feedback. We introduced a new approach, DistillDirect, for performing on-policy reinforcement learning with Gemini 1.0 Pro as the teacher model. Our resulting model, LLaMA-Clinic, can generate clinical notes comparable in quality to those authored by physicians. In a blinded physician reader study, the majority (90.4%) of individual evaluations rated the notes generated by LLaMA-Clinic as acceptable or higher across all three criteria: real-world readiness, completeness, and accuracy. In the more challenging Assessment and Plan section, LLaMA-Clinic scored higher (4.2/5) in real-world readiness than physician-authored notes (4.1/5). Our cost analysis for inference shows that our LLaMA-Clinic model achieves a 3.75-fold cost reduction compared to an external generic LLM service. Additionally, we highlight key considerations for future clinical note-generation tasks, emphasizing the importance of pre-defining a best-practice note format, rather than relying on LLMs to determine this for clinical practice. We have made our newly created synthetic clinic dialogue-note dataset and the physician feedback dataset publicly available to foster future research.
Read more6/11/2024
0
Biomedical Large Languages Models Seem not to be Superior to Generalist Models on Unseen Medical Data
Felix J. Dorfner, Amin Dada, Felix Busch, Marcus R. Makowski, Tianyu Han, Daniel Truhn, Jens Kleesiek, Madhumita Sushil, Jacqueline Lammert, Lisa C. Adams, Keno K. Bressem
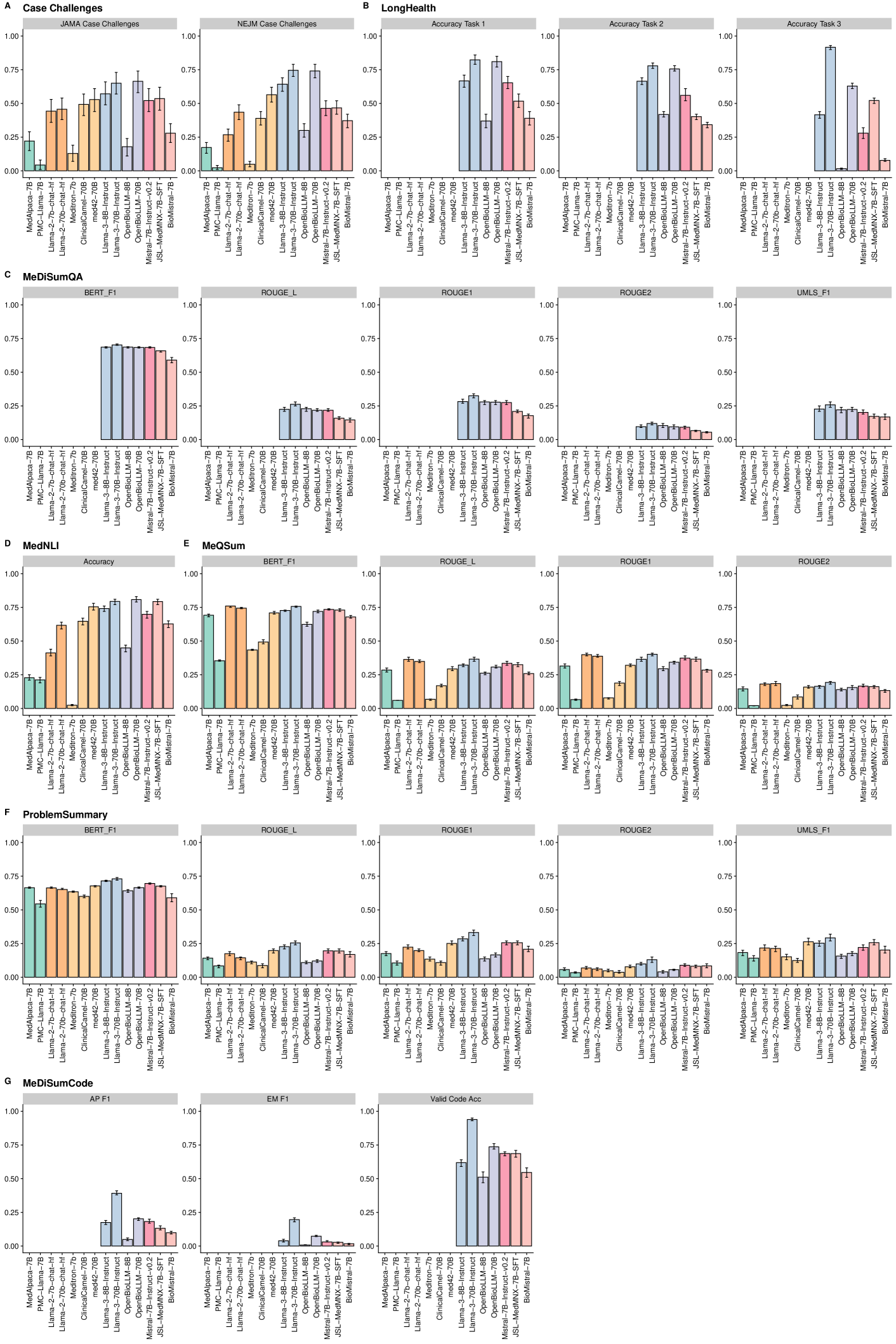
Large language models (LLMs) have shown potential in biomedical applications, leading to efforts to fine-tune them on domain-specific data. However, the effectiveness of this approach remains unclear. This study evaluates the performance of biomedically fine-tuned LLMs against their general-purpose counterparts on a variety of clinical tasks. We evaluated their performance on clinical case challenges from the New England Journal of Medicine (NEJM) and the Journal of the American Medical Association (JAMA) and on several clinical tasks (e.g., information extraction, document summarization, and clinical coding). Using benchmarks specifically chosen to be likely outside the fine-tuning datasets of biomedical models, we found that biomedical LLMs mostly perform inferior to their general-purpose counterparts, especially on tasks not focused on medical knowledge. While larger models showed similar performance on case tasks (e.g., OpenBioLLM-70B: 66.4% vs. Llama-3-70B-Instruct: 65% on JAMA cases), smaller biomedical models showed more pronounced underperformance (e.g., OpenBioLLM-8B: 30% vs. Llama-3-8B-Instruct: 64.3% on NEJM cases). Similar trends were observed across the CLUE (Clinical Language Understanding Evaluation) benchmark tasks, with general-purpose models often performing better on text generation, question answering, and coding tasks. Our results suggest that fine-tuning LLMs to biomedical data may not provide the expected benefits and may potentially lead to reduced performance, challenging prevailing assumptions about domain-specific adaptation of LLMs and highlighting the need for more rigorous evaluation frameworks in healthcare AI. Alternative approaches, such as retrieval-augmented generation, may be more effective in enhancing the biomedical capabilities of LLMs without compromising their general knowledge.
Read more8/27/2024

0
Towards Democratizing Multilingual Large Language Models For Medicine Through A Two-Stage Instruction Fine-tuning Approach
Meng Zhou, Surajsinh Parmar, Anubhav Bhatti
Open-source, multilingual medical large language models (LLMs) have the potential to serve linguistically diverse populations across different regions. Adapting generic LLMs for healthcare often requires continual pretraining, but this approach is computationally expensive and sometimes impractical. Instruction fine-tuning on a specific task may not always guarantee optimal performance due to the lack of broader domain knowledge that the model needs to understand and reason effectively in diverse scenarios. To address these challenges, we introduce two multilingual instruction fine-tuning datasets, MMed-IFT and MMed-IFT-MC, containing over 200k high-quality medical samples in six languages. We propose a two-stage training paradigm: the first stage injects general medical knowledge using MMed-IFT, while the second stage fine-tunes task-specific multiple-choice questions with MMed-IFT-MC. Our method achieves competitive results on both English and multilingual benchmarks, striking a balance between computational efficiency and performance. We plan to make our dataset and model weights public at url{https://github.com/SpassMed/Med-Llama3} in the future.
Read more9/10/2024