Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations
2404.18812
0
0
🚀
Abstract
Learned sparse representations form an attractive class of contextual embeddings for text retrieval. That is so because they are effective models of relevance and are interpretable by design. Despite their apparent compatibility with inverted indexes, however, retrieval over sparse embeddings remains challenging. That is due to the distributional differences between learned embeddings and term frequency-based lexical models of relevance such as BM25. Recognizing this challenge, a great deal of research has gone into, among other things, designing retrieval algorithms tailored to the properties of learned sparse representations, including approximate retrieval systems. In fact, this task featured prominently in the latest BigANN Challenge at NeurIPS 2023, where approximate algorithms were evaluated on a large benchmark dataset by throughput and recall. In this work, we propose a novel organization of the inverted index that enables fast yet effective approximate retrieval over learned sparse embeddings. Our approach organizes inverted lists into geometrically-cohesive blocks, each equipped with a summary vector. During query processing, we quickly determine if a block must be evaluated using the summaries. As we show experimentally, single-threaded query processing using our method, Seismic, reaches sub-millisecond per-query latency on various sparse embeddings of the MS MARCO dataset while maintaining high recall. Our results indicate that Seismic is one to two orders of magnitude faster than state-of-the-art inverted index-based solutions and further outperforms the winning (graph-based) submissions to the BigANN Challenge by a significant margin.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Learned sparse representations offer effective and interpretable models of text relevance for information retrieval
- However, retrieving over sparse embeddings remains challenging due to differences from traditional lexical models like BM25
- Researchers have focused on developing specialized retrieval algorithms and approximate systems to address this challenge
- This paper proposes a novel inverted index organization that enables fast yet effective approximate retrieval over learned sparse embeddings
Plain English Explanation
Learned sparse representations are a type of text embedding that can effectively capture the relevance of text. This makes them useful for information retrieval tasks like search.
The sparse and interpretable nature of these embeddings is appealing. However, actually using them for retrieval is challenging. This is because they are quite different from the traditional lexical relevance models like BM25 that search engines typically rely on.
To address this challenge, researchers have focused on developing specialized retrieval algorithms and approximate search systems tailored to sparse embeddings.
This paper proposes a new way to organize the search index that enables fast yet effective approximate retrieval over learned sparse embeddings. The key idea is to group the index entries into cohesive blocks, each with a summary vector to quickly determine if the block is relevant to the query. This allows for very fast search speeds while maintaining high accuracy.
Technical Explanation
The paper introduces a novel inverted index organization called "Seismic" that enables efficient approximate retrieval over learned sparse text embeddings.
The core idea is to group the inverted lists into geometrically-cohesive blocks, each equipped with a summary vector. During query processing, the system can quickly determine if a block of the index should be evaluated by checking the block's summary against the query. This avoids unnecessary processing of irrelevant blocks.
The authors show experimentally that their Seismic method can achieve sub-millisecond per-query latency on various sparse text embeddings of the MS MARCO dataset, while maintaining high recall. Compared to state-of-the-art inverted index-based solutions, Seismic is 1-2 orders of magnitude faster. It also significantly outperforms the winning submissions to the recent BigANN Challenge, which used graph-based approximate nearest neighbor search.
Critical Analysis
The paper makes a compelling case for the Seismic index organization and demonstrates its strong performance on standard benchmarks. However, a few potential limitations or areas for further research are worth noting:
The evaluation is focused on throughput and recall, but does not consider other important factors like index construction time or index size. These practical concerns may be important in real-world applications.
Additionally, the experiments are limited to sparse text embeddings. It would be valuable to understand how well the Seismic approach generalizes to other types of high-dimensional sparse data beyond just text.
Finally, while the paper references the BigANN Challenge, it does not provide a deeper analysis of how Seismic compares to the specific techniques used by the winning graph-based submissions. A more nuanced technical comparison could yield additional insights.
Overall, the Seismic index organization represents a promising advance in enabling fast approximate retrieval over learned sparse representations. However, further research is needed to fully understand its strengths, weaknesses, and applicability across a broader range of domains and use cases.
Conclusion
This paper introduces a novel inverted index organization called Seismic that enables fast yet effective approximate retrieval over learned sparse text embeddings. By grouping the index into geometrically-cohesive blocks with summary vectors, Seismic can quickly filter out irrelevant parts of the index, leading to sub-millisecond query latencies while maintaining high recall.
The Seismic approach significantly outperforms state-of-the-art inverted index-based solutions as well as the winning submissions to the recent BigANN Challenge. This work represents an important step forward in making learned sparse representations practically usable for real-world information retrieval tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Information Retrieval with Entity Linking
Dahlia Shehata
0
0
Despite the advantages of their low-resource settings, traditional sparse retrievers depend on exact matching approaches between high-dimensional bag-of-words (BoW) representations of both the queries and the collection. As a result, retrieval performance is restricted by semantic discrepancies and vocabulary gaps. On the other hand, transformer-based dense retrievers introduce significant improvements in information retrieval tasks by exploiting low-dimensional contextualized representations of the corpus. While dense retrievers are known for their relative effectiveness, they suffer from lower efficiency and lack of generalization issues, when compared to sparse retrievers. For a lightweight retrieval task, high computational resources and time consumption are major barriers encouraging the renunciation of dense models despite potential gains. In this work, I propose boosting the performance of sparse retrievers by expanding both the queries and the documents with linked entities in two formats for the entity names: 1) explicit and 2) hashed. A zero-shot end-to-end dense entity linking system is employed for entity recognition and disambiguation to augment the corpus. By leveraging the advanced entity linking methods, I believe that the effectiveness gap between sparse and dense retrievers can be narrowed. Experiments are conducted on the MS MARCO passage dataset using the original qrel set, the re-ranked qrels favoured by MonoT5 and the latter set further re-ranked by DuoT5. Since I am concerned with the early stage retrieval in cascaded ranking architectures of large information retrieval systems, the results are evaluated using recall@1000. The suggested approach is also capable of retrieving documents for query subsets judged to be particularly difficult in prior work.
4/16/2024
🌿
Span-Aggregatable, Contextualized Word Embeddings for Effective Phrase Mining
Eyal Orbach, Lev Haikin, Nelly David, Avi Faizakof
0
0
Dense vector representations for sentences made significant progress in recent years as can be seen on sentence similarity tasks. Real-world phrase retrieval applications, on the other hand, still encounter challenges for effective use of dense representations. We show that when target phrases reside inside noisy context, representing the full sentence with a single dense vector, is not sufficient for effective phrase retrieval. We therefore look into the notion of representing multiple, sub-sentence, consecutive word spans, each with its own dense vector. We show that this technique is much more effective for phrase mining, yet requires considerable compute to obtain useful span representations. Accordingly, we make an argument for contextualized word/token embeddings that can be aggregated for arbitrary word spans while maintaining the span's semantic meaning. We introduce a modification to the common contrastive loss used for sentence embeddings that encourages word embeddings to have this property. To demonstrate the effect of this method we present a dataset based on the STS-B dataset with additional generated text, that requires finding the best matching paraphrase residing in a larger context and report the degree of similarity to the origin phrase. We demonstrate on this dataset, how our proposed method can achieve better results without significant increase to compute.
5/14/2024
Faster Learned Sparse Retrieval with Block-Max Pruning
Antonio Mallia, Torten Suel, Nicola Tonellotto
0
0
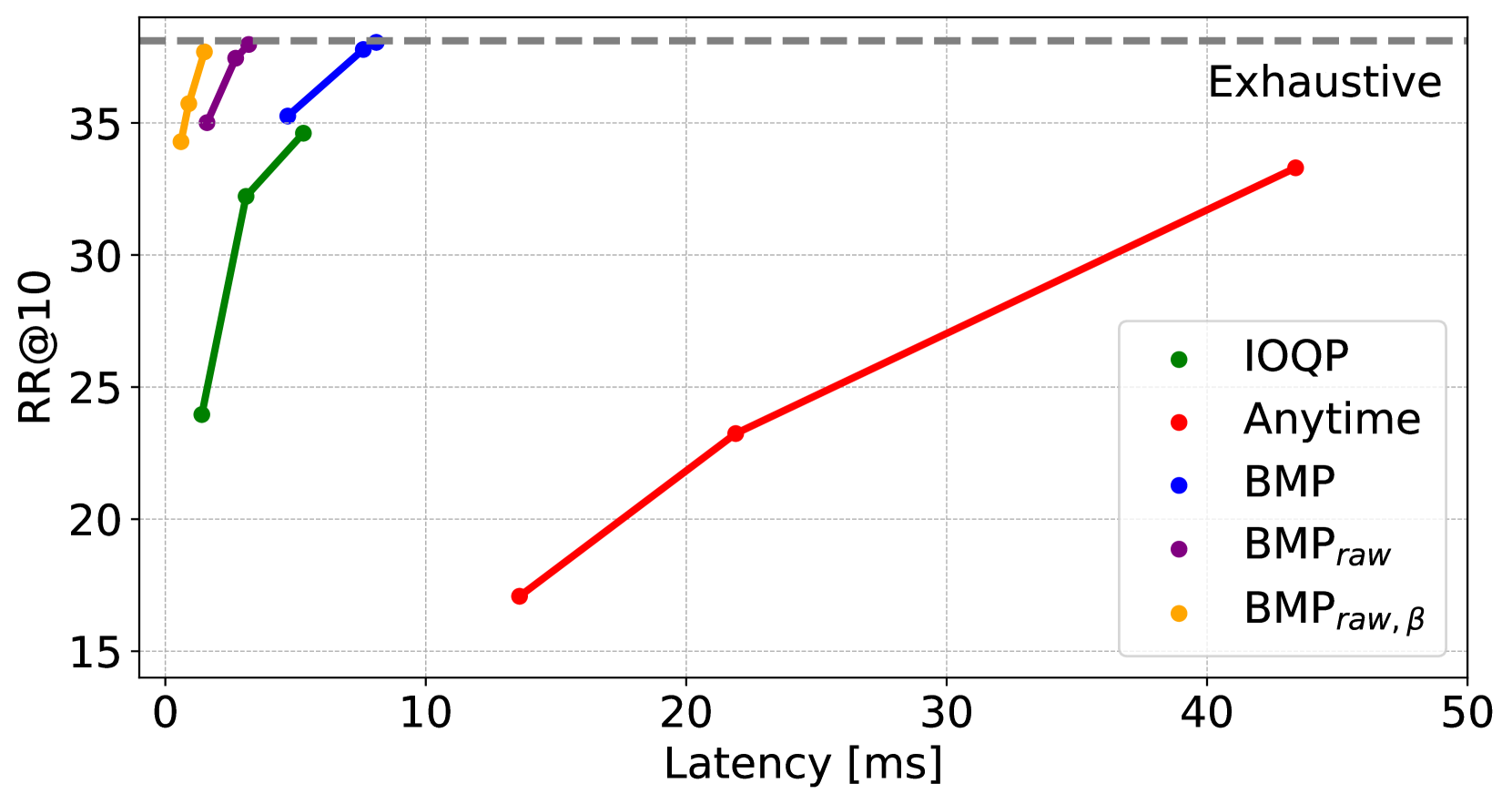
Learned sparse retrieval systems aim to combine the effectiveness of contextualized language models with the scalability of conventional data structures such as inverted indexes. Nevertheless, the indexes generated by these systems exhibit significant deviations from the ones that use traditional retrieval models, leading to a discrepancy in the performance of existing query optimizations that were specifically developed for traditional structures. These disparities arise from structural variations in query and document statistics, including sub-word tokenization, leading to longer queries, smaller vocabularies, and different score distributions within posting lists. This paper introduces Block-Max Pruning (BMP), an innovative dynamic pruning strategy tailored for indexes arising in learned sparse retrieval environments. BMP employs a block filtering mechanism to divide the document space into small, consecutive document ranges, which are then aggregated and sorted on the fly, and fully processed only as necessary, guided by a defined safe early termination criterion or based on approximate retrieval requirements. Through rigorous experimentation, we show that BMP substantially outperforms existing dynamic pruning strategies, offering unparalleled efficiency in safe retrieval contexts and improved tradeoffs between precision and efficiency in approximate retrieval tasks.
5/3/2024
Two-Step SPLADE: Simple, Efficient and Effective Approximation of SPLADE
Carlos Lassance, Herv'e Dejean, St'ephane Clinchant, Nicola Tonellotto
0
0
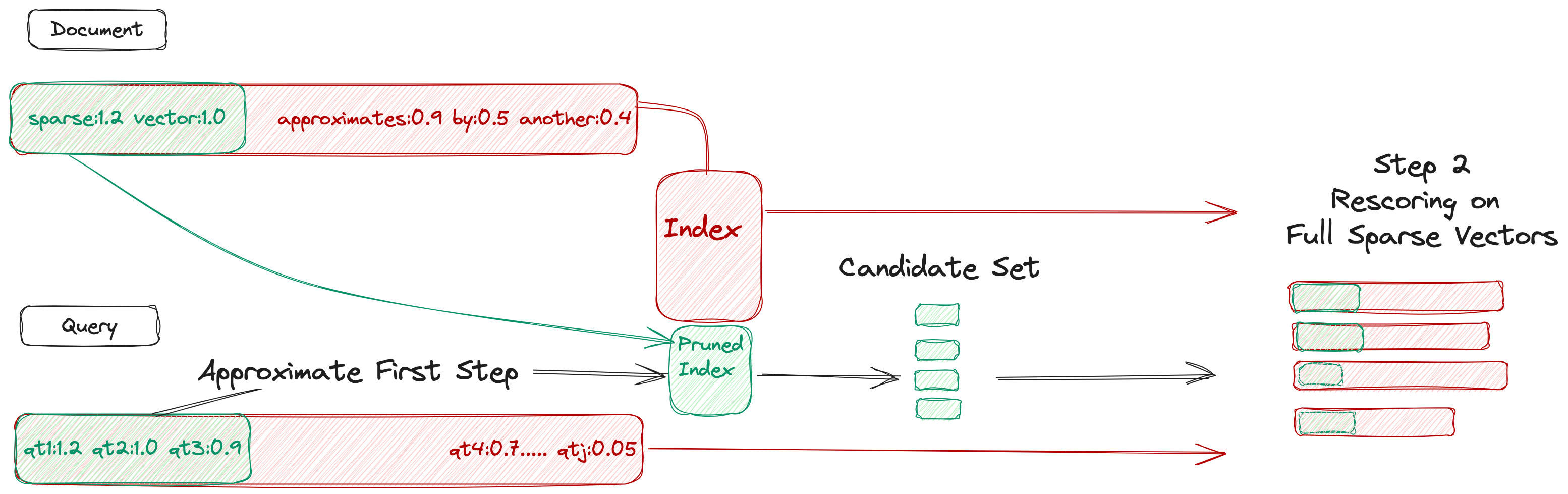
Learned sparse models such as SPLADE have successfully shown how to incorporate the benefits of state-of-the-art neural information retrieval models into the classical inverted index data structure. Despite their improvements in effectiveness, learned sparse models are not as efficient as classical sparse model such as BM25. The problem has been investigated and addressed by recently developed strategies, such as guided traversal query processing and static pruning, with different degrees of success on in-domain and out-of-domain datasets. In this work, we propose a new query processing strategy for SPLADE based on a two-step cascade. The first step uses a pruned and reweighted version of the SPLADE sparse vectors, and the second step uses the original SPLADE vectors to re-score a sample of documents retrieved in the first stage. Our extensive experiments, performed on 30 different in-domain and out-of-domain datasets, show that our proposed strategy is able to improve mean and tail response times over the original single-stage SPLADE processing by up to $30times$ and $40times$, respectively, for in-domain datasets, and by 12x to 25x, for mean response on out-of-domain datasets, while not incurring in statistical significant difference in 60% of datasets.
4/23/2024