Two-Step SPLADE: Simple, Efficient and Effective Approximation of SPLADE

0
Sign in to get full access
Overview
- Proposes a two-step approach called "Two-Step SPLADE" to efficiently approximate the SPLADE document retrieval model
- SPLADE is a state-of-the-art sparse retrieval model, but is computationally expensive
- Two-Step SPLADE aims to maintain SPLADE's effectiveness while significantly improving efficiency
Plain English Explanation
Two-Step SPLADE is a new way to do document retrieval that builds on an existing model called SPLADE. SPLADE is very good at finding relevant documents, but it can be slow and require a lot of computing power.
The key idea behind Two-Step SPLADE is to break the retrieval process into two simpler steps. First, it quickly identifies a smaller set of potentially relevant documents. Then, it takes a closer look at that smaller set to pick the most relevant ones. This two-step approach is more efficient than running the full SPLADE model on all documents.
By simplifying the retrieval process, Two-Step SPLADE can run much faster than SPLADE while still finding many of the same highly relevant documents. This makes it a practical choice for real-world search applications that need to be both effective and efficient.
Technical Explanation
Two-Step SPLADE is an approximation of the SPLADE document retrieval model. SPLADE is a state-of-the-art sparse retrieval model that achieves high effectiveness, but is computationally expensive.
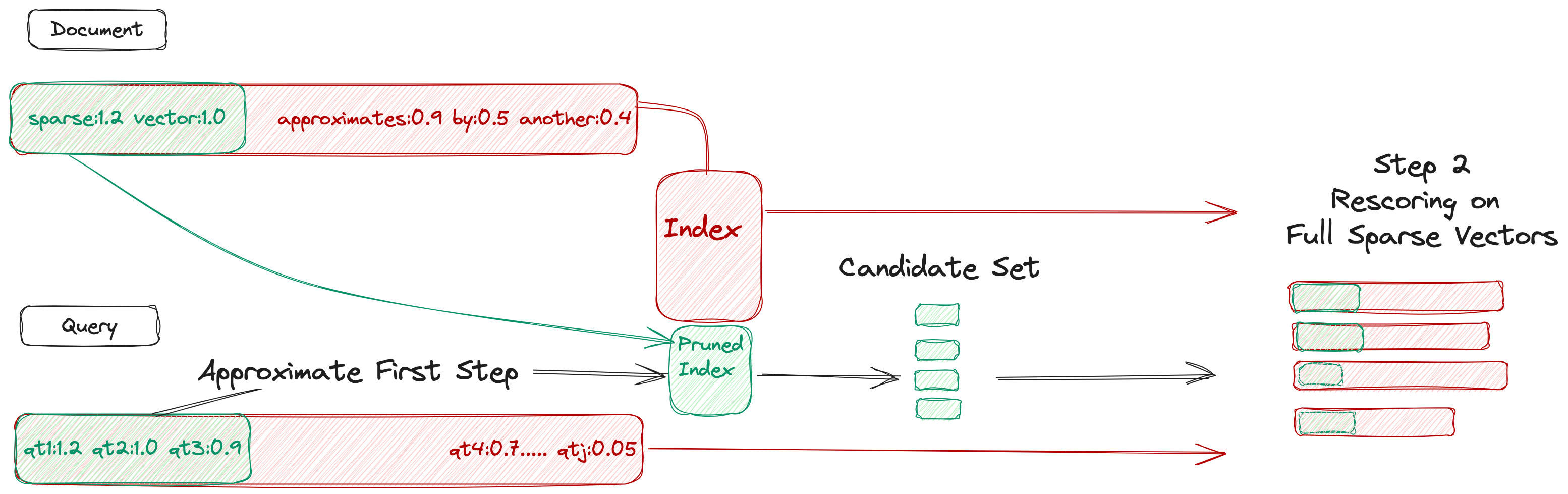
The key idea behind Two-Step SPLADE is to break the retrieval process into two steps:
- Candidate Generation: First, a fast and lightweight model is used to quickly identify a small set of potentially relevant documents.
- Reranking: Then, the full SPLADE model is applied to this smaller candidate set to select the most relevant documents.
By separating the process into these two steps, Two-Step SPLADE can maintain the effectiveness of SPLADE while significantly improving efficiency. The authors show that Two-Step SPLADE achieves comparable retrieval performance to SPLADE, but is 2-3 times faster.
The authors also experiment with different techniques for the candidate generation step, including a cluster-based sparse retrieval model and a simple term-based scoring function. They find that even a simple term-based approach can work well in practice.
Critical Analysis
The authors provide a thorough evaluation of Two-Step SPLADE, comparing it to SPLADE and other baselines across several standard information retrieval benchmarks. The results demonstrate the effectiveness of their two-step approach in balancing retrieval quality and efficiency.
One potential limitation is that the performance of Two-Step SPLADE may depend on the quality of the candidate generation step. If the initial candidate set does not contain the most relevant documents, the reranking step may not be able to recover them. The authors acknowledge this and experiment with different techniques for the candidate generation, but further research may be needed to fully understand the factors that influence this step.
Additionally, while Two-Step SPLADE significantly improves upon the efficiency of SPLADE, it is still a complex model that may require specialized hardware or infrastructure to deploy at scale. Simpler term-based or cluster-based approaches may be more suitable for certain real-world applications with more limited resources.
Overall, the Two-Step SPLADE approach represents an important step forward in balancing the often competing goals of retrieval effectiveness and efficiency. The authors' careful experimentation and analysis provide valuable insights for the broader information retrieval community.
Conclusion
Two-Step SPLADE proposes a novel two-step approach to approximate the state-of-the-art SPLADE document retrieval model. By breaking the retrieval process into candidate generation and reranking steps, Two-Step SPLADE is able to maintain SPLADE's high effectiveness while significantly improving efficiency.
The authors' thorough evaluation demonstrates the practical value of this approach, which could enable the deployment of advanced retrieval models in real-world search and recommendation systems that require both high quality and low latency. Further research exploring the tradeoffs and applicability of Two-Step SPLADE in different domains and settings could yield additional insights for the information retrieval community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Two-Step SPLADE: Simple, Efficient and Effective Approximation of SPLADE
Carlos Lassance, Herv'e Dejean, St'ephane Clinchant, Nicola Tonellotto
Learned sparse models such as SPLADE have successfully shown how to incorporate the benefits of state-of-the-art neural information retrieval models into the classical inverted index data structure. Despite their improvements in effectiveness, learned sparse models are not as efficient as classical sparse model such as BM25. The problem has been investigated and addressed by recently developed strategies, such as guided traversal query processing and static pruning, with different degrees of success on in-domain and out-of-domain datasets. In this work, we propose a new query processing strategy for SPLADE based on a two-step cascade. The first step uses a pruned and reweighted version of the SPLADE sparse vectors, and the second step uses the original SPLADE vectors to re-score a sample of documents retrieved in the first stage. Our extensive experiments, performed on 30 different in-domain and out-of-domain datasets, show that our proposed strategy is able to improve mean and tail response times over the original single-stage SPLADE processing by up to $30times$ and $40times$, respectively, for in-domain datasets, and by 12x to 25x, for mean response on out-of-domain datasets, while not incurring in statistical significant difference in 60% of datasets.
Read more4/23/2024
🤷
0
CoSPLADE: Contextualizing SPLADE for Conversational Information Retrieval
Nam Le Hai, Thomas Gerald, Thibault Formal, Jian-Yun Nie, Benjamin Piwowarski, Laure Soulier
Conversational search is a difficult task as it aims at retrieving documents based not only on the current user query but also on the full conversation history. Most of the previous methods have focused on a multi-stage ranking approach relying on query reformulation, a critical intermediate step that might lead to a sub-optimal retrieval. Other approaches have tried to use a fully neural IR first-stage, but are either zero-shot or rely on full learning-to-rank based on a dataset with pseudo-labels. In this work, leveraging the CANARD dataset, we propose an innovative lightweight learning technique to train a first-stage ranker based on SPLADE. By relying on SPLADE sparse representations, we show that, when combined with a second-stage ranker based on T5Mono, the results are competitive on the TREC CAsT 2020 and 2021 tracks.
Read more7/8/2024
0
Contextualization with SPLADE for High Recall Retrieval
Eugene Yang
High Recall Retrieval (HRR), such as eDiscovery and medical systematic review, is a search problem that optimizes the cost of retrieving most relevant documents in a given collection. Iterative approaches, such as iterative relevance feedback and uncertainty sampling, are shown to be effective under various operational scenarios. Despite neural models demonstrating success in other text-related tasks, linear models such as logistic regression, in general, are still more effective and efficient in HRR since the model is trained and retrieves documents from the same fixed collection. In this work, we leverage SPLADE, an efficient retrieval model that transforms documents into contextualized sparse vectors, for HRR. Our approach combines the best of both worlds, leveraging both the contextualization from pretrained language models and the efficiency of linear models. It reduces 10% and 18% of the review cost in two HRR evaluation collections under a one-phase review workflow with a target recall of 80%. The experiment is implemented with TARexp and is available at https://github.com/eugene-yang/LSR-for-TAR.
Read more5/8/2024
0
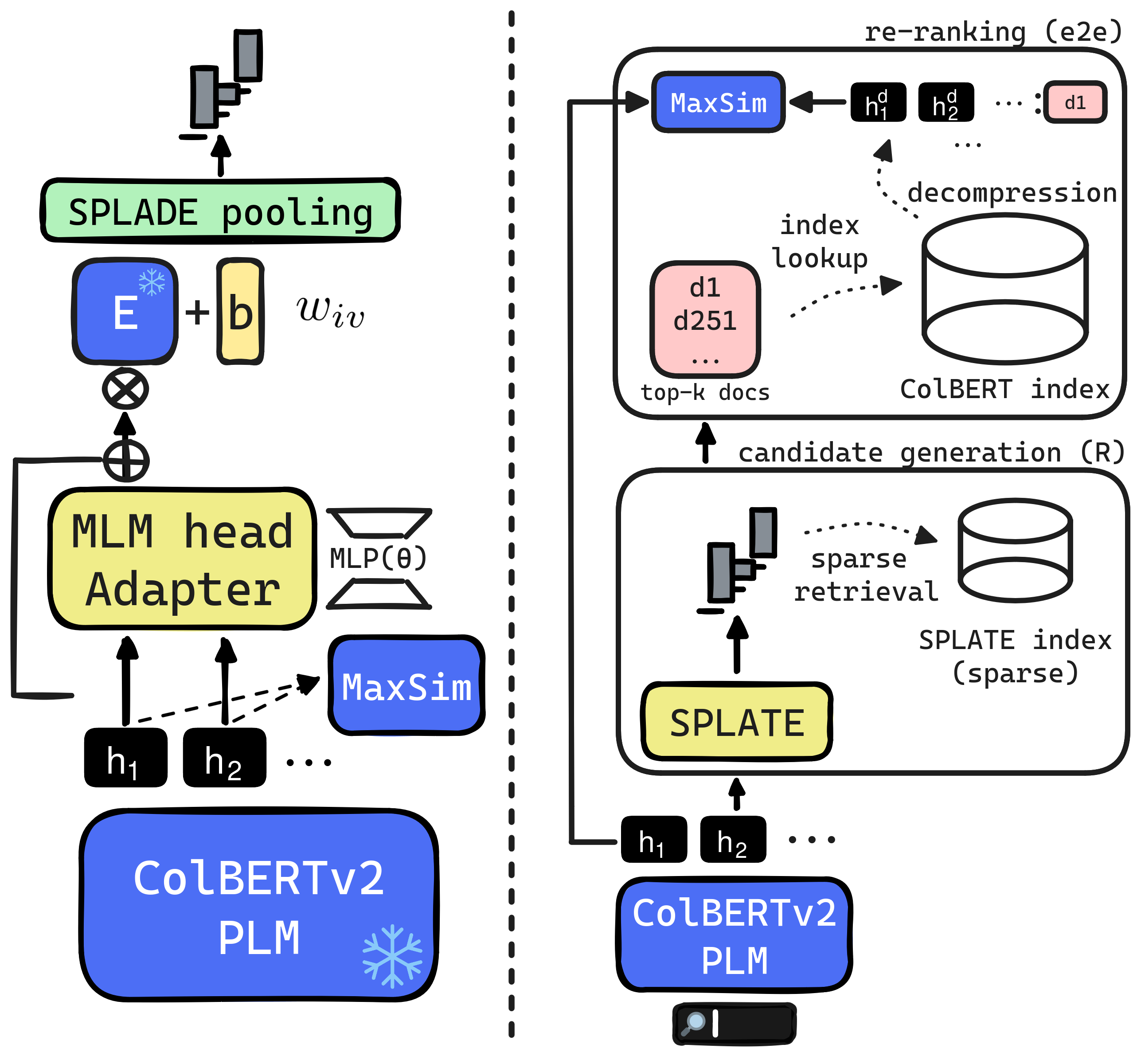
SPLATE: Sparse Late Interaction Retrieval
Thibault Formal, St'ephane Clinchant, Herv'e D'ejean, Carlos Lassance
The late interaction paradigm introduced with ColBERT stands out in the neural Information Retrieval space, offering a compelling effectiveness-efficiency trade-off across many benchmarks. Efficient late interaction retrieval is based on an optimized multi-step strategy, where an approximate search first identifies a set of candidate documents to re-rank exactly. In this work, we introduce SPLATE, a simple and lightweight adaptation of the ColBERTv2 model which learns an ``MLM adapter'', mapping its frozen token embeddings to a sparse vocabulary space with a partially learned SPLADE module. This allows us to perform the candidate generation step in late interaction pipelines with traditional sparse retrieval techniques, making it particularly appealing for running ColBERT in CPU environments. Our SPLATE ColBERTv2 pipeline achieves the same effectiveness as the PLAID ColBERTv2 engine by re-ranking 50 documents that can be retrieved under 10ms.
Read more4/23/2024