On Efficient Language and Vision Assistants for Visually-Situated Natural Language Understanding: What Matters in Reading and Reasoning
2406.11823
0
0
Abstract
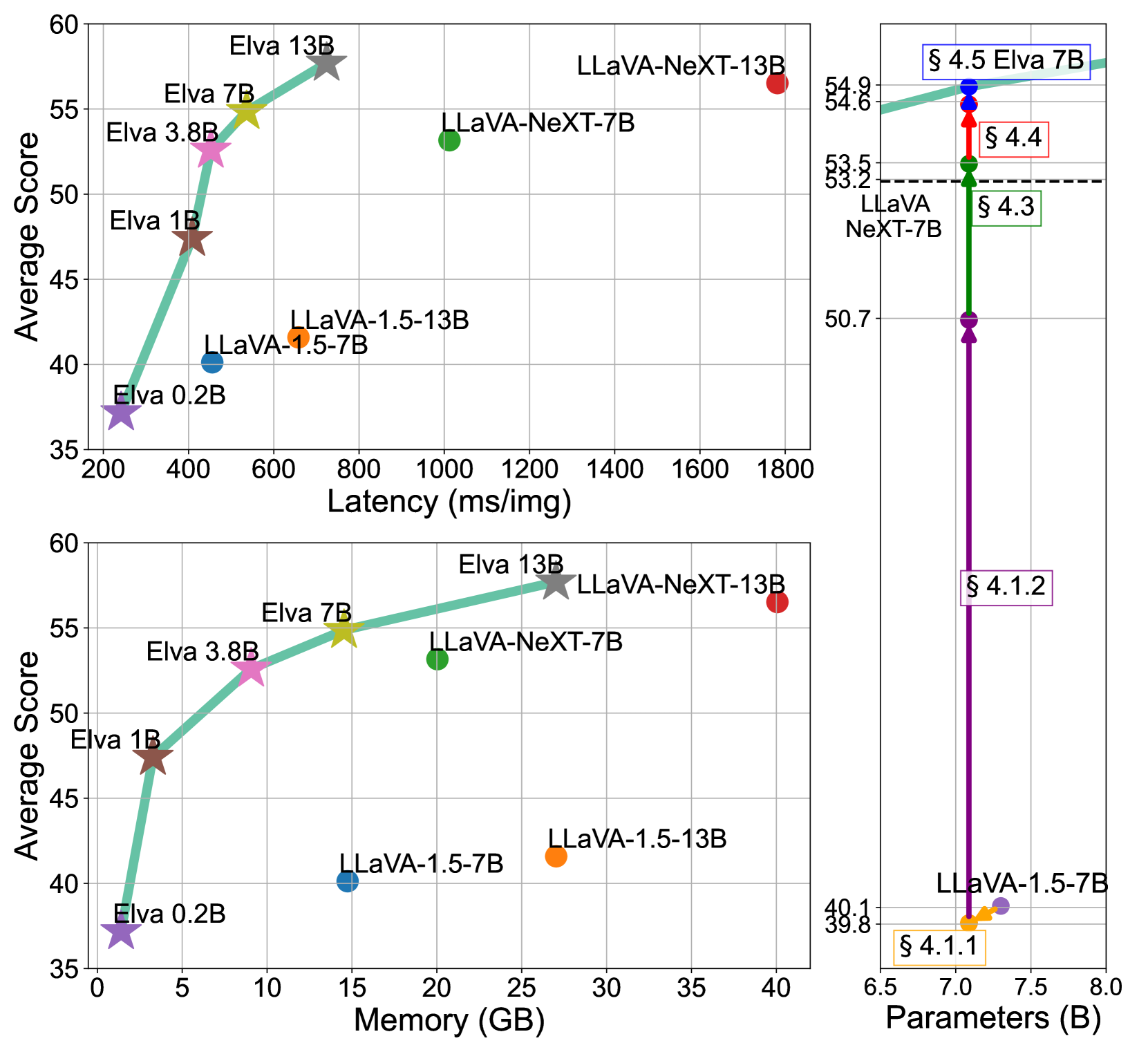
Recent advancements in language and vision assistants have showcased impressive capabilities but suffer from a lack of transparency, limiting broader research and reproducibility. While open-source models handle general image tasks effectively, they face challenges with the high computational demands of complex visually-situated text understanding. Such tasks often require increased token inputs and large vision modules to harness high-resolution information. Striking a balance between model size and data importance remains an open question. This study aims to redefine the design of vision-language models by identifying key components and creating efficient models with constrained inference costs. By strategically formulating datasets, optimizing vision modules, and enhancing supervision techniques, we achieve significant improvements in inference throughput while maintaining high performance. Extensive experiments across models ranging from 160M to 13B parameters offer insights into model optimization. We will fully open-source our codebase, models, and datasets at https://github.com/naver-ai/elva .
Create account to get full access
Overview
- This paper explores the important factors in building efficient and effective language and vision assistants for visually-situated natural language understanding tasks.
- The authors analyze the roles of language and vision in learning from limited data, assess the effectiveness of recent large vision-language models, and explore techniques to enhance vision models for text-heavy content understanding.
- The research provides insights into designing more capable and efficient multimodal AI systems that can understand language in the context of visual information.
Plain English Explanation
The paper investigates what is important when developing language and vision AI assistants that can understand natural language in the context of visual information. The researchers analyze how language and vision contribute to learning from limited data, evaluate the performance of recent large vision-language models, and explore ways to improve vision models for tasks involving a lot of text.
This research is important for designing more capable and efficient multimodal AI systems - systems that can understand language by combining it with visual information. For example, these types of assistants could be useful for tasks like answering questions about an image or describing the contents of a document with both text and diagrams. The insights from this paper can help create AI assistants that are better at comprehending language in real-world visual contexts.
Technical Explanation
The paper examines several key aspects of building effective language and vision AI assistants:
-
Analyzing the Roles of Language and Vision in Learning from Limited Data: The authors investigate how language and vision contribute to model performance when training data is scarce, providing guidance on leveraging multimodal information.
-
Assessing the Effectiveness of Recent Large Vision-Language Models: The paper evaluates the capabilities of state-of-the-art vision-language models, identifying strengths and weaknesses to inform the development of more capable systems.
-
Enhancing Vision Models for Text-Heavy Content Understanding: The authors explore techniques to improve the performance of vision models on tasks involving a significant amount of text, which is important for applications like document understanding.
-
Designing Efficient Language and Vision Assistants: The research provides guidance on the key factors to consider when developing practical, high-performing language and vision AI assistants, such as model size, training data, and multimodal integration.
Critical Analysis
The paper provides a comprehensive analysis of the important considerations when building efficient and effective language and vision assistants. However, the authors acknowledge some limitations in their work. For example, they note that their evaluations of vision-language models may not fully capture real-world performance, as the tested tasks and datasets may not reflect the complexity of actual applications.
Additionally, the paper does not delve deeply into potential social and ethical implications of these technologies, such as concerns around bias, privacy, or the impact on human labor. Further research could explore these broader societal considerations as language and vision AI assistants become more prevalent.
Overall, this paper offers valuable insights for researchers and practitioners working on advancing the capabilities of multimodal AI systems. The findings can help guide the development of more capable and efficient language and vision assistants that can better understand and interact with the world around them.
Conclusion
This paper provides a thorough examination of the key factors that matter when building efficient and effective language and vision AI assistants for visually-situated natural language understanding. The authors' analysis of the roles of language and vision, the performance of recent large vision-language models, and techniques for enhancing vision models for text-heavy content offer important guidance for researchers and developers working in this area.
The insights from this research can contribute to the creation of more capable and practical multimodal AI systems that can seamlessly combine language and visual understanding. As these technologies continue to advance, it will be crucial to also consider the broader societal implications and ensure they are developed and deployed responsibly.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
What matters when building vision-language models?
Hugo Laurenc{c}on, L'eo Tronchon, Matthieu Cord, Victor Sanh
0
0
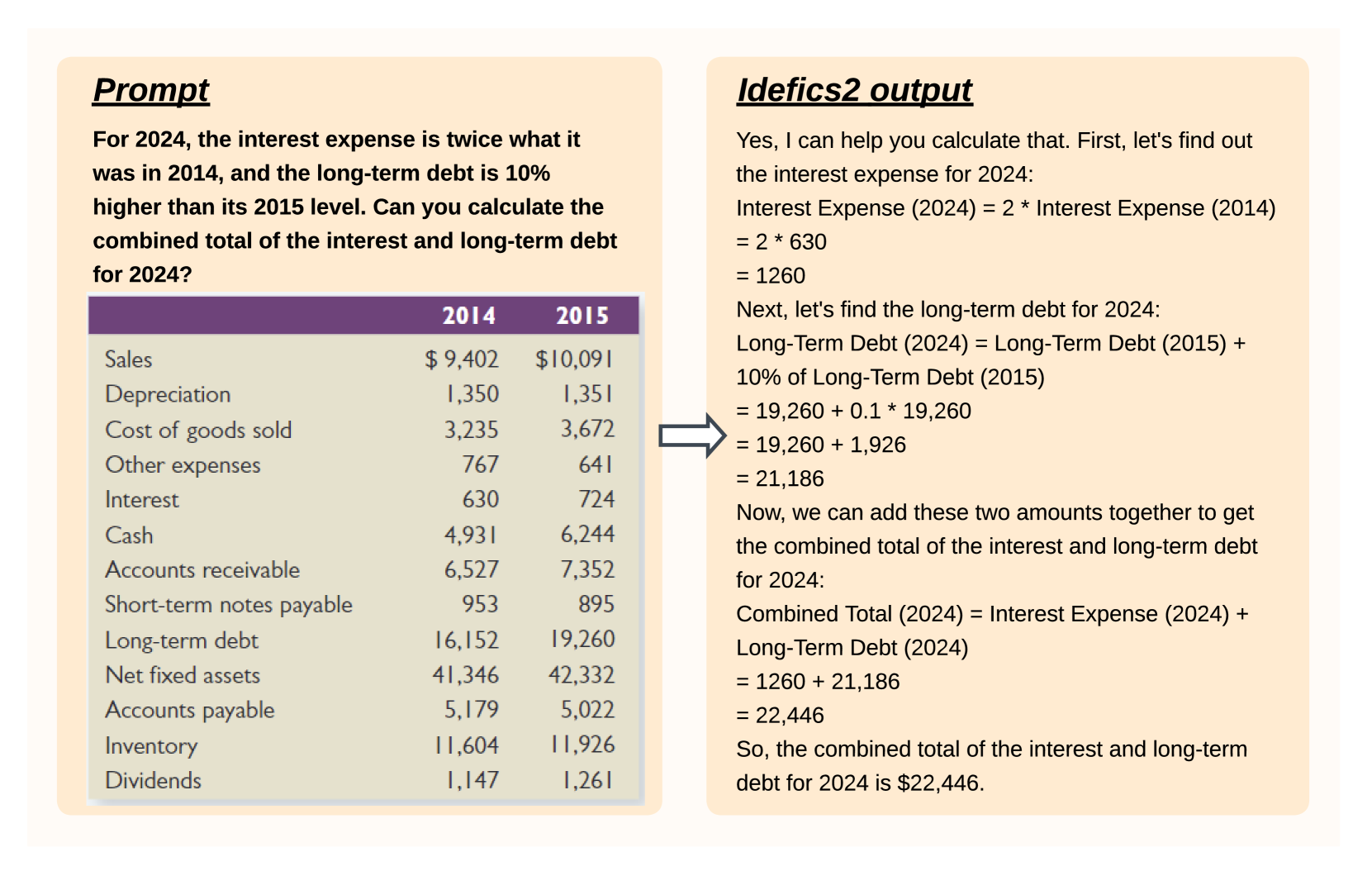
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
5/6/2024
Analyzing the Roles of Language and Vision in Learning from Limited Data
Allison Chen, Ilia Sucholutsky, Olga Russakovsky, Thomas L. Griffiths
0
0
Does language help make sense of the visual world? How important is it to actually see the world rather than having it described with words? These basic questions about the nature of intelligence have been difficult to answer because we only had one example of an intelligent system -- humans -- and limited access to cases that isolated language or vision. However, the development of sophisticated Vision-Language Models (VLMs) by artificial intelligence researchers offers us new opportunities to explore the contributions that language and vision make to learning about the world. We ablate components from the cognitive architecture of these models to identify their contributions to learning new tasks from limited data. We find that a language model leveraging all components recovers a majority of a VLM's performance, despite its lack of visual input, and that language seems to allow this by providing access to prior knowledge and reasoning.
5/13/2024
Effectiveness Assessment of Recent Large Vision-Language Models
Yao Jiang, Xinyu Yan, Ge-Peng Ji, Keren Fu, Meijun Sun, Huan Xiong, Deng-Ping Fan, Fahad Shahbaz Khan
0
0
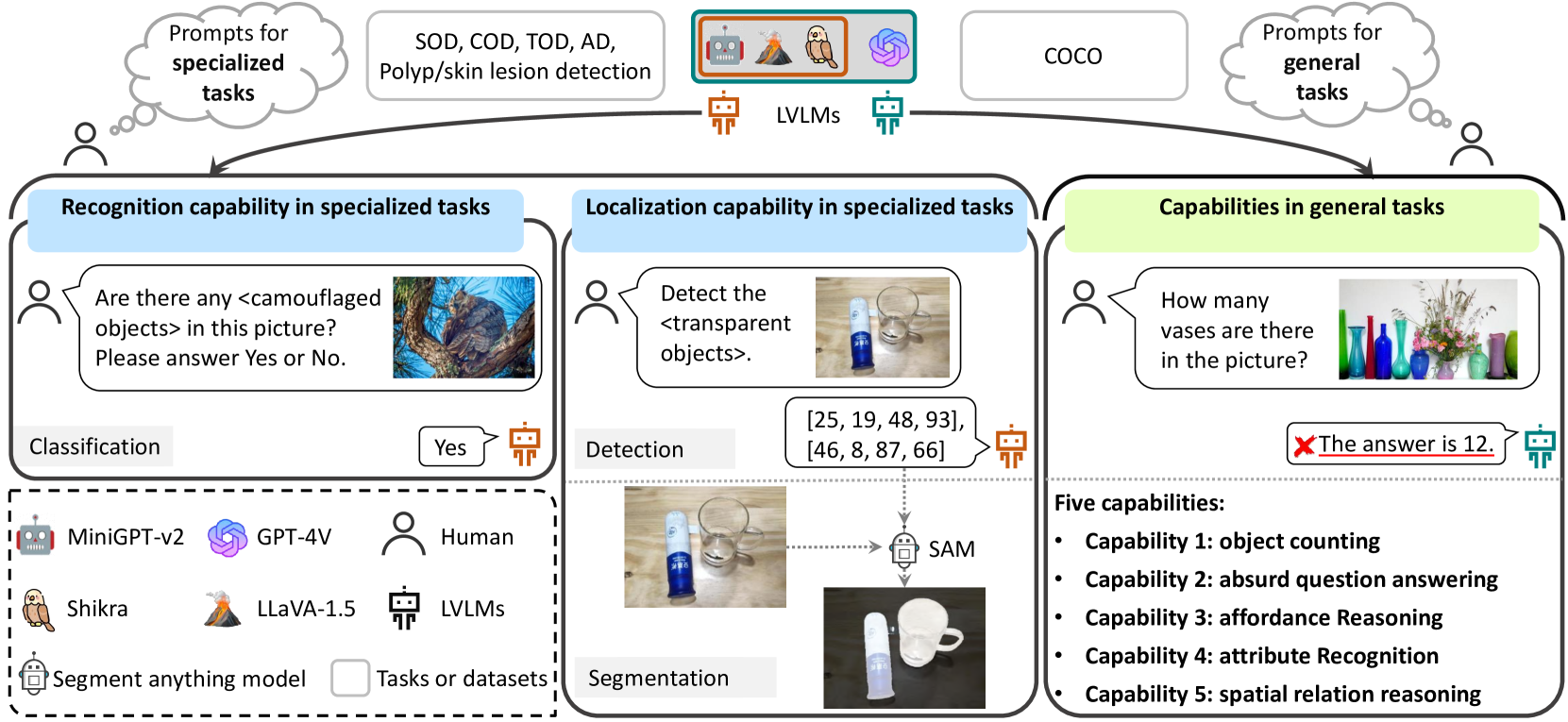
The advent of large vision-language models (LVLMs) represents a remarkable advance in the quest for artificial general intelligence. However, the model's effectiveness in both specialized and general tasks warrants further investigation. This paper endeavors to evaluate the competency of popular LVLMs in specialized and general tasks, respectively, aiming to offer a comprehensive understanding of these novel models. To gauge their effectiveness in specialized tasks, we employ six challenging tasks in three different application scenarios: natural, healthcare, and industrial. These six tasks include salient/camouflaged/transparent object detection, as well as polyp detection, skin lesion detection, and industrial anomaly detection. We examine the performance of three recent open-source LVLMs, including MiniGPT-v2, LLaVA-1.5, and Shikra, on both visual recognition and localization in these tasks. Moreover, we conduct empirical investigations utilizing the aforementioned LVLMs together with GPT-4V, assessing their multi-modal understanding capabilities in general tasks including object counting, absurd question answering, affordance reasoning, attribute recognition, and spatial relation reasoning. Our investigations reveal that these LVLMs demonstrate limited proficiency not only in specialized tasks but also in general tasks. We delve deep into this inadequacy and uncover several potential factors, including limited cognition in specialized tasks, object hallucination, text-to-image interference, and decreased robustness in complex problems. We hope that this study can provide useful insights for the future development of LVLMs, helping researchers improve LVLMs for both general and specialized applications.
6/12/2024
Training a Vision Language Model as Smartphone Assistant
Nicolai Dorka, Janusz Marecki, Ammar Anwar
0
0
Addressing the challenge of a digital assistant capable of executing a wide array of user tasks, our research focuses on the realm of instruction-based mobile device control. We leverage recent advancements in large language models (LLMs) and present a visual language model (VLM) that can fulfill diverse tasks on mobile devices. Our model functions by interacting solely with the user interface (UI). It uses the visual input from the device screen and mimics human-like interactions, encompassing gestures such as tapping and swiping. This generality in the input and output space allows our agent to interact with any application on the device. Unlike previous methods, our model operates not only on a single screen image but on vision-language sentences created from sequences of past screenshots along with corresponding actions. Evaluating our method on the challenging Android in the Wild benchmark demonstrates its promising efficacy and potential.
4/16/2024