Efficient learning-based sound propagation for virtual and real-world audio processing applications

0
⚙️
Sign in to get full access
Overview
- Sound propagation describes how sound energy travels through a medium like air as sound waves.
- The room impulse response (RIR) captures this process and is influenced by factors like source/listener positions, room geometry, and materials.
- Physics-based acoustic simulators have limitations, so this paper proposes three novel solutions.
Plain English Explanation
The paper explores ways to better understand how sound travels through different environments. When sound is produced in a room, the shape of the room and the materials it's made of affect how that sound travels and echoes. This is captured by something called the "room impulse response" (RIR). Traditional physics-based acoustic simulators have some issues, so the researchers propose three new approaches:
- A fast, learning-based RIR generator that can produce high-quality RIRs for both real and synthetic 3D spaces. This outperforms traditional simulators on speech processing tasks.
- A method to estimate RIRs directly from reverberant speech and visual cues, without needing a full 3D model of the environment. This can help improve speech recognition in far-field scenarios.
- A way to augment accurate RIRs using real data, allowing parametric control over acoustic properties to generate new RIRs that mimic different environments. This also improves far-field speech recognition.
Technical Explanation
The paper introduces three novel solutions to address limitations of existing physics-based acoustic simulators:
-
Learning-based RIR Generator: The authors propose a fast, learning-based RIR generator that can produce both monaural and binaural RIRs for real and synthetic 3D scenes. This model is two orders of magnitude faster than interactive ray-tracing simulators, while outperforming them on speech processing tasks like automatic speech recognition (ASR), speech enhancement, and speech separation.
-
Audio-Visual RIR Estimation: The researchers developed a method to estimate RIRs directly from reverberant speech signals and visual cues, without requiring a 3D representation of the environment. This allows augmenting training data to better match test conditions, leading to a 6.9% improvement in far-field ASR over previous learning-based RIR estimators.
-
RIR Augmentation with IR-GAN: The authors introduce IR-GAN, which can parametrically control acoustic properties learned from real RIRs to generate new RIRs that mimic different environments. This outperforms ray-tracing simulators on the far-field ASR benchmark by 8.95%.
Critical Analysis
The paper presents several innovative solutions to address the limitations of existing physics-based acoustic simulators. However, a few potential issues or areas for future research are worth considering:
- The learning-based RIR generator and audio-visual RIR estimation methods rely on large, high-quality training datasets, which may not always be available, especially for diverse real-world environments.
- The proposed techniques focus on improving speech processing applications, but their effectiveness for other audio tasks, such as music or environmental sound analysis, is not explored.
- While the paper demonstrates significant performance improvements, further research is needed to understand the fundamental limitations of physics-based simulators and how learning-based approaches can be generalized to overcome them.
Conclusion
This paper introduces three novel solutions to improve the modeling of sound propagation in acoustic environments. The learning-based RIR generator, audio-visual RIR estimation, and RIR augmentation with IR-GAN offer significant advancements over traditional physics-based simulators, particularly in speech processing applications. These techniques have the potential to enable more accurate and efficient acoustic simulation, which could benefit a wide range of fields, from virtual and augmented reality to Smart Home and autonomous systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⚙️
0
Efficient learning-based sound propagation for virtual and real-world audio processing applications
Anton Jeran Ratnarajah
Sound propagation is the process by which sound energy travels through a medium, such as air, to the surrounding environment as sound waves. The room impulse response (RIR) describes this process and is influenced by the positions of the source and listener, the room's geometry, and its materials. Physics-based acoustic simulators have been used for decades to compute accurate RIRs for specific acoustic environments. However, we have encountered limitations with existing acoustic simulators. To address these limitations, we propose three novel solutions. First, we introduce a learning-based RIR generator that is two orders of magnitude faster than an interactive ray-tracing simulator. Our approach can be trained to input both statistical and traditional parameters directly, and it can generate both monaural and binaural RIRs for both reconstructed and synthetic 3D scenes. Our generated RIRs outperform interactive ray-tracing simulators in speech-processing applications, including ASR, Speech Enhancement, and Speech Separation. Secondly, we propose estimating RIRs from reverberant speech signals and visual cues without a 3D representation of the environment. By estimating RIRs from reverberant speech, we can augment training data to match test data, improving the word error rate of the ASR system. Our estimated RIRs achieve a 6.9% improvement over previous learning-based RIR estimators in far-field ASR tasks. We demonstrate that our audio-visual RIR estimator aids tasks like visual acoustic matching, novel-view acoustic synthesis, and voice dubbing, validated through perceptual evaluation. Finally, we introduce IR-GAN to augment accurate RIRs using real RIRs. IR-GAN parametrically controls acoustic parameters learned from real RIRs to generate new RIRs that imitate different acoustic environments, outperforming Ray-tracing simulators on the far-field ASR benchmark by 8.95%.
Read more9/25/2024
0
Hearing Anything Anywhere
Mason Wang, Ryosuke Sawata, Samuel Clarke, Ruohan Gao, Shangzhe Wu, Jiajun Wu
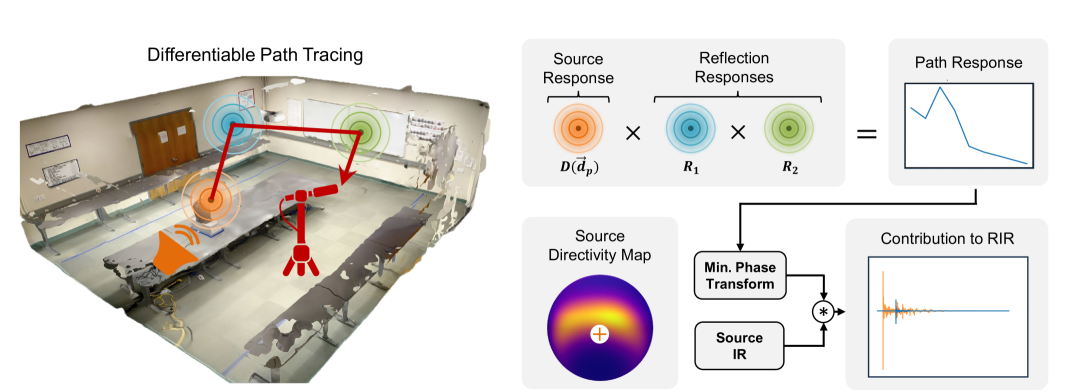
Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
Read more6/12/2024

0
ActiveRIR: Active Audio-Visual Exploration for Acoustic Environment Modeling
Arjun Somayazulu, Sagnik Majumder, Changan Chen, Kristen Grauman
An environment acoustic model represents how sound is transformed by the physical characteristics of an indoor environment, for any given source/receiver location. Traditional methods for constructing acoustic models involve expensive and time-consuming collection of large quantities of acoustic data at dense spatial locations in the space, or rely on privileged knowledge of scene geometry to intelligently select acoustic data sampling locations. We propose active acoustic sampling, a new task for efficiently building an environment acoustic model of an unmapped environment in which a mobile agent equipped with visual and acoustic sensors jointly constructs the environment acoustic model and the occupancy map on-the-fly. We introduce ActiveRIR, a reinforcement learning (RL) policy that leverages information from audio-visual sensor streams to guide agent navigation and determine optimal acoustic data sampling positions, yielding a high quality acoustic model of the environment from a minimal set of acoustic samples. We train our policy with a novel RL reward based on information gain in the environment acoustic model. Evaluating on diverse unseen indoor environments from a state-of-the-art acoustic simulation platform, ActiveRIR outperforms an array of methods--both traditional navigation agents based on spatial novelty and visual exploration as well as existing state-of-the-art methods.
Read more4/26/2024
↗️
0
Audio Simulation for Sound Source Localization in Virtual Evironment
Yi Di Yuan, Swee Liang Wong, Jonathan Pan
Non-line-of-sight localization in signal-deprived environments is a challenging yet pertinent problem. Acoustic methods in such predominantly indoor scenarios encounter difficulty due to the reverberant nature. In this study, we aim to locate sound sources to specific locations within a virtual environment by leveraging physically grounded sound propagation simulations and machine learning methods. This process attempts to overcome the issue of data insufficiency to localize sound sources to their location of occurrence especially in post-event localization. We achieve 0.786+/- 0.0136 F1-score using an audio transformer spectrogram approach.
Read more4/3/2024