Efficient LLM Comparative Assessment: a Product of Experts Framework for Pairwise Comparisons

0
Sign in to get full access
Overview
- Introduces a "Product of Experts" framework for efficiently assessing and comparing the performance of large language models (LLMs) through pairwise comparisons
- Aims to address challenges in LLM evaluation, such as the need for large-scale human evaluations and the difficulties in interpreting model comparisons
- Proposes a method to aggregate multiple expert opinions to arrive at robust and reliable model comparisons
Plain English Explanation
The paper presents a new approach called the "Product of Experts" framework to help researchers and developers more effectively evaluate and compare the performance of large language models (LLMs). Evaluating LLMs is challenging because it often requires extensive human testing, which can be time-consuming and expensive. Additionally, interpreting the results of model comparisons can be difficult.
The "Product of Experts" framework is designed to address these issues. The key idea is to aggregate the opinions of multiple "expert" models, each of which specializes in a different aspect of language understanding or generation. By combining the judgments of these experts, the framework can arrive at more reliable and robust comparisons between LLMs. This approach aims to provide a more efficient and insightful way to assess the strengths and weaknesses of different language models.
The framework could be particularly useful for researchers evaluating language models for educational content generation, developers comparing LLMs for specific use cases, or anyone seeking to improve the consistency and transparency of LLM evaluations.
Technical Explanation
The paper introduces a "Product of Experts" (PoE) framework for efficiently assessing and comparing the performance of large language models (LLMs) through pairwise comparisons. The key idea is to aggregate the judgments of multiple "expert" models, each of which specializes in a different aspect of language understanding or generation, in order to arrive at robust and reliable model comparisons.
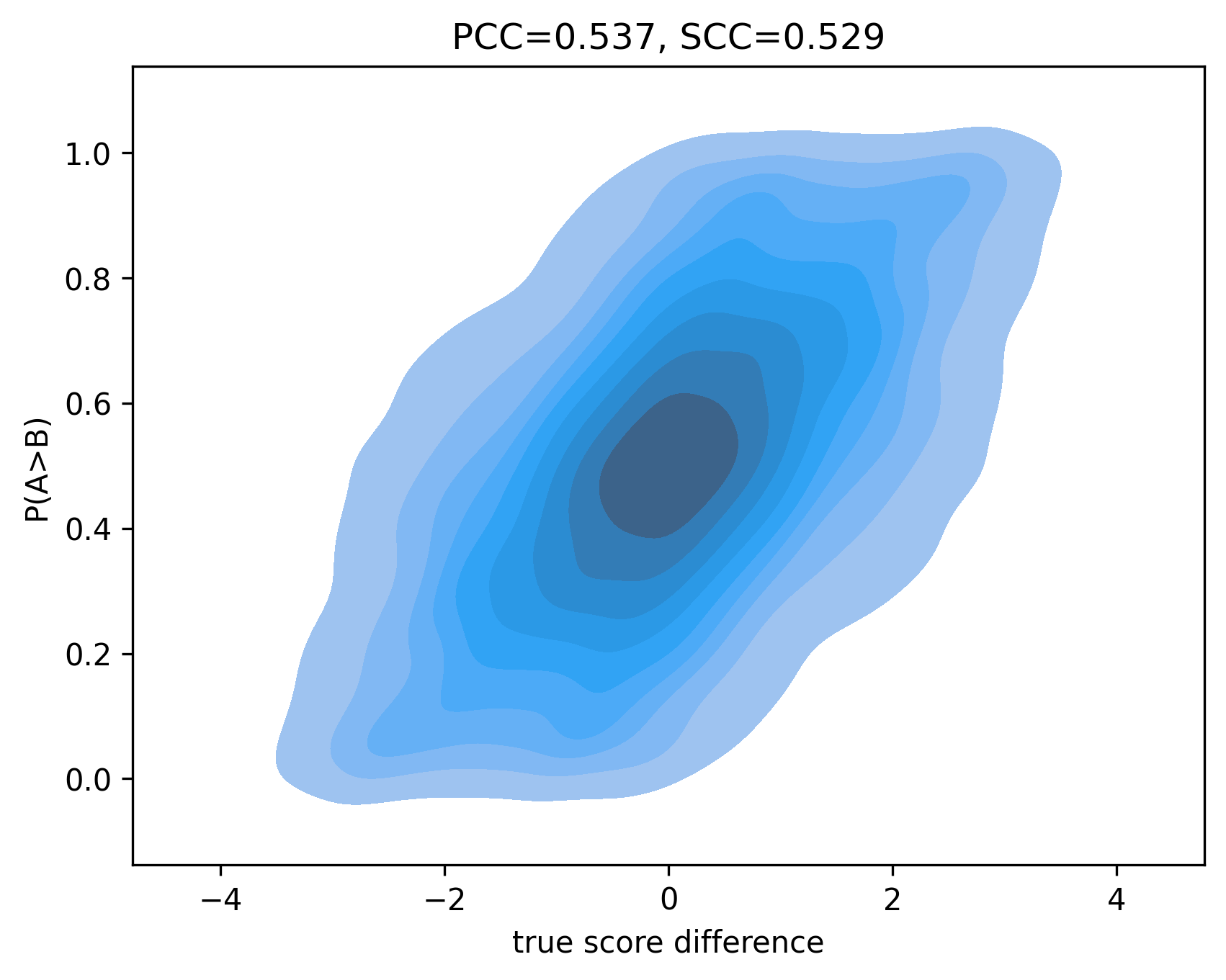
The authors propose a PoE model that combines the outputs of multiple expert models, where each expert is trained to predict a specific aspect of language quality (e.g., fluency, coherence, relevance). The overall PoE score for a given model pair is then computed as the product of the individual expert scores. This approach allows the framework to capture the multifaceted nature of language quality and provide a more nuanced evaluation than relying on a single metric.
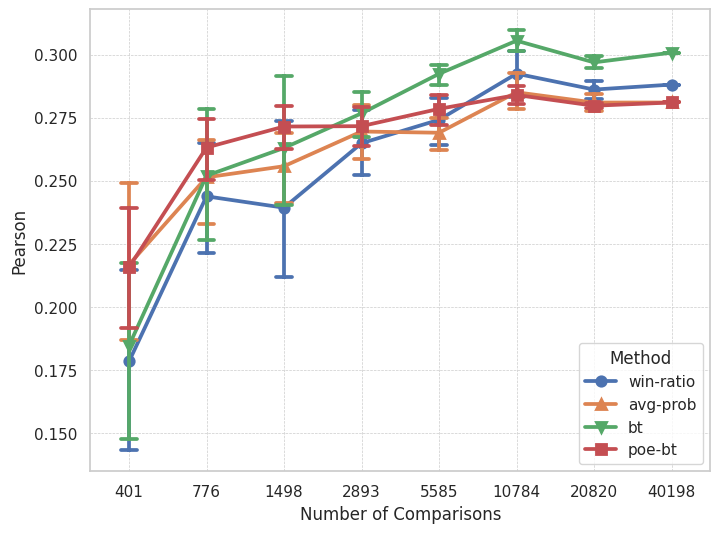
The authors demonstrate the effectiveness of the PoE framework through experiments on several language tasks, including text generation and summarization. The results show that the PoE framework can achieve reliable and consistent model comparisons while requiring fewer human evaluations than traditional approaches.
Critical Analysis
The "Product of Experts" framework presented in the paper offers a promising solution to the challenges of LLM evaluation. By aggregating the judgments of multiple specialized expert models, the framework can provide more nuanced and reliable assessments of language model performance.
One potential limitation of the approach is the need to develop and train the individual expert models, which may require significant effort and resources. The paper does not provide much detail on how these expert models are designed and trained, or how their performance and coverage of language quality aspects are ensured.
Additionally, the framework relies on the assumption that the expert models are truly independent and provide complementary assessments of language quality. In practice, there may be dependencies or overlaps between the experts, which could affect the robustness of the overall PoE scores.
Further research could explore methods for automatically identifying and selecting the most informative expert models, or for dynamically weighting the expert contributions based on their relative performance and reliability. Investigating the framework's applicability to a wider range of language tasks and its scalability to large-scale model comparisons would also be valuable.
Conclusion
The "Product of Experts" framework presented in this paper offers a novel and promising approach to efficiently evaluating and comparing the performance of large language models. By aggregating the judgments of multiple expert models, the framework can provide more robust and insightful assessments of language quality, which could be particularly useful for researchers, developers, and anyone seeking to improve LLM evaluations.
While the framework has its own challenges and limitations, the core idea of leveraging specialized expert models to provide a more comprehensive and reliable assessment of language models is a valuable contribution to the field of large language model evaluation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient LLM Comparative Assessment: a Product of Experts Framework for Pairwise Comparisons
Adian Liusie, Vatsal Raina, Yassir Fathullah, Mark Gales
LLM-as-a-judge approaches are a practical and effective way of assessing a range of text tasks, aligning with human judgements especially when applied in a comparative assessment fashion. However, when using pairwise comparisons to rank a set of candidates the computational costs scale quadratically with the number of candidates, which can have practical limitations. This paper introduces a Product of Expert (PoE) framework for efficient LLM Comparative Assessment. Here individual comparisons are considered experts that provide information on a pair's score difference. The PoE framework combines the information from these experts to yield an expression that can be maximized with respect to the underlying set of candidates, and is highly flexible where any form of expert can be assumed. When Gaussian experts are used one can derive simple closed-form solutions for the optimal candidate ranking, as well as expressions for selecting which comparisons should be made to maximize the probability of this ranking. Our approach enables efficient comparative assessment, where by using only a small subset of the possible comparisons, one can generate score predictions that correlate as well to human judgements as the predictions when all comparisons are used. We evaluate the approach on multiple NLG tasks and demonstrate that our framework can yield considerable computational savings when performing pairwise comparative assessment. When N is large, with as few as 2% of comparisons the PoE solution can achieve similar performance to when all comparisons are used.
Read more6/11/2024
0
Finetuning LLMs for Comparative Assessment Tasks
Vatsal Raina, Adian Liusie, Mark Gales
Automated assessment in natural language generation is a challenging task. Instruction-tuned large language models (LLMs) have shown promise in reference-free evaluation, particularly through comparative assessment. However, the quadratic computational complexity of pairwise comparisons limits its scalability. To address this, efficient comparative assessment has been explored by applying comparative strategies on zero-shot LLM probabilities. We propose a framework for finetuning LLMs for comparative assessment to align the model's output with the target distribution of comparative probabilities. By training on soft probabilities, our approach improves state-of-the-art performance while maintaining high performance with an efficient subset of comparisons.
Read more9/25/2024

0
Judging the Judges: A Systematic Investigation of Position Bias in Pairwise Comparative Assessments by LLMs
Lin Shi, Chiyu Ma, Weicheng Ma, Soroush Vosoughi
LLM-as-a-Judge offers a promising alternative to human judges across various tasks, yet inherent biases, particularly position bias - a systematic preference for answers based on their position in the prompt - compromise its effectiveness. Our study investigates this issue by developing a framework to systematically study and quantify position bias using metrics such as repetitional consistency, positional consistency, and positional fairness. We conduct experiments with 9 judge models across 22 tasks from the MTBench and DevBench benchmarks and nearly 40 answer-generating models, generating approximately 80,000 evaluation instances. This comprehensive assessment reveals significant variations in bias across judges and tasks. Although GPT-4 often excels in positional consistency and fairness, some more cost-effective models perform comparably or even better in specific tasks, highlighting essential trade-offs between consistency, fairness, and cost. Our results also demonstrate high consistency of judgment across repetitions, confirming that position bias is not due to random variations. This research significantly contributes to the field by introducing new concepts for understanding position bias and providing a multi-dimensional framework for evaluation. These insights guide the selection of optimal judge models, enhance benchmark design, and lay the foundation for future research into effective debiasing strategies, ultimately enhancing the reliability of LLM evaluators.
Read more8/14/2024

0
PRePair: Pointwise Reasoning Enhance Pairwise Evaluating for Robust Instruction-Following Assessments
Hawon Jeong, ChaeHun Park, Jimin Hong, Jaegul Choo
Pairwise evaluation using large language models (LLMs) is widely used for evaluating natural language generation (NLG) tasks. However, the reliability of LLMs is often compromised by biases, such as favoring verbosity and authoritative tone. In the study, we focus on the comparison of two LLM-based evaluation approaches, pointwise and pairwise. Our findings demonstrate that pointwise evaluators exhibit more robustness against undesirable preferences. Further analysis reveals that pairwise evaluators can accurately identify the shortcomings of low-quality outputs even when their judgment is incorrect. These results indicate that LLMs are more severely influenced by their bias in a pairwise evaluation setup. To mitigate this, we propose a hybrid method that integrates pointwise reasoning into pairwise evaluation. Experimental results show that our method enhances the robustness of pairwise evaluators against adversarial samples while preserving accuracy on normal samples.
Read more6/19/2024