Efficient LLM inference solution on Intel GPU
2401.05391
103
0
🤯
Abstract
Transformer based Large Language Models (LLMs) have been widely used in many fields, and the efficiency of LLM inference becomes hot topic in real applications. However, LLMs are usually complicatedly designed in model structure with massive operations and perform inference in the auto-regressive mode, making it a challenging task to design a system with high efficiency. In this paper, we propose an efficient LLM inference solution with low latency and high throughput. Firstly, we simplify the LLM decoder layer by fusing data movement and element-wise operations to reduce the memory access frequency and lower system latency. We also propose a segment KV cache policy to keep key/value of the request and response tokens in separate physical memory for effective device memory management, helping enlarge the runtime batch size and improve system throughput. A customized Scaled-Dot-Product-Attention kernel is designed to match our fusion policy based on the segment KV cache solution. We implement our LLM inference solution on Intel GPU and publish it publicly. Compared with the standard HuggingFace implementation, the proposed solution achieves up to 7x lower token latency and 27x higher throughput for some popular LLMs on Intel GPU.
Create account to get full access
Overview
- Transformer-based large language models (LLMs) are widely used but can be challenging to deploy efficiently
- This paper proposes an efficient solution for LLM inference with low latency and high throughput
- Key innovations include simplifying the decoder layer, using a segment KV cache policy, and a customized attention kernel
- The proposed solution achieves up to 7x lower token latency and 27x higher throughput compared to standard implementations on Intel GPUs
Plain English Explanation
Large language models (LLMs) powered by transformer architectures have become extremely powerful and useful in a variety of applications. However, efficiently running these models in real-world scenarios can be tricky. They often have complex designs with many operations, and they perform inference in an auto-regressive manner, which can make them slow and inefficient.
This paper presents a new approach to make LLM inference more efficient. First, the researchers simplified the decoder layer of the LLM by combining data movement and element-wise operations. This reduces the number of times data has to be accessed from memory, which helps lower the overall system latency.
The paper also introduces a "segment KV cache" policy. This keeps the keys and values used in the attention mechanism separately in memory. This allows the system to more effectively manage the limited memory available, enabling larger batch sizes and higher throughput.
Finally, the researchers designed a custom attention kernel that works well with their simplified decoder and segment KV cache approach. Putting all these pieces together, the resulting LLM inference solution can run up to 7 times faster and have 27 times higher throughput compared to standard implementations, when tested on Intel GPUs.
The key insight here is finding ways to streamline the architecture and memory usage of these powerful but complex language models, so they can be deployed more effectively in practical applications. This type of optimization work is crucial for bringing the benefits of large language models to the real world.
Technical Explanation
The paper starts by noting the widespread use of transformer-based large language models (LLMs) and the importance of achieving high-efficiency inference for real-world applications.
To address this, the authors propose several key innovations:
-
Simplified decoder layer: They fuse data movement and element-wise operations in the LLM decoder layer to reduce memory access frequency and lower system latency. This simplifies the overall model architecture.
-
Segment KV cache: The system keeps the key and value tensors used in the attention mechanism in separate physical memory locations. This enables more effective device memory management, allowing larger runtime batch sizes and improved throughput.
-
Customized attention kernel: The researchers designed a specialized Scaled-Dot-Product-Attention kernel that is tailored to work with their simplified decoder layer and segment KV cache approach.
The authors implemented this efficient LLM inference solution on Intel GPUs and compared it against the standard HuggingFace implementation. Their proposed approach achieved up to 7x lower token latency and 27x higher throughput for some popular LLMs.
Critical Analysis
The paper presents a well-designed and thorough approach to improving the efficiency of LLM inference. The key innovations, such as the simplified decoder layer and segment KV cache, are well-motivated and appear to deliver significant performance gains.
However, the paper does not deeply explore the potential limitations or tradeoffs of these techniques. For example, it's unclear how the simplified decoder layer might impact model accuracy or the ability to fine-tune the LLM for specific tasks. Additionally, the reliance on specialized hardware (Intel GPUs) may limit the broader applicability of the solution.
Further research could investigate the generalizability of these techniques across different LLM architectures and hardware platforms. It would also be valuable to better understand the impact on model quality and the suitability for various real-world use cases, beyond just raw performance metrics.
Overall, this paper represents an important contribution to the ongoing efforts to improve the efficiency of large language model inference and bring these powerful models to more edge-based applications. With continued research and development in this area, we may see substantial improvements in LLM inference efficiency in the near future.
Conclusion
This paper presents an innovative approach to improving the efficiency of transformer-based large language model inference. By simplifying the decoder layer, using a segment KV cache policy, and designing a customized attention kernel, the researchers were able to achieve significant performance gains in terms of lower latency and higher throughput.
These types of optimizations are crucial for bringing the benefits of powerful language models to real-world applications, where efficiency and low-latency inference are often essential. While the paper does not explore all the potential limitations, it represents an important step forward in the ongoing efforts to enhance the efficiency of large language model inference.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
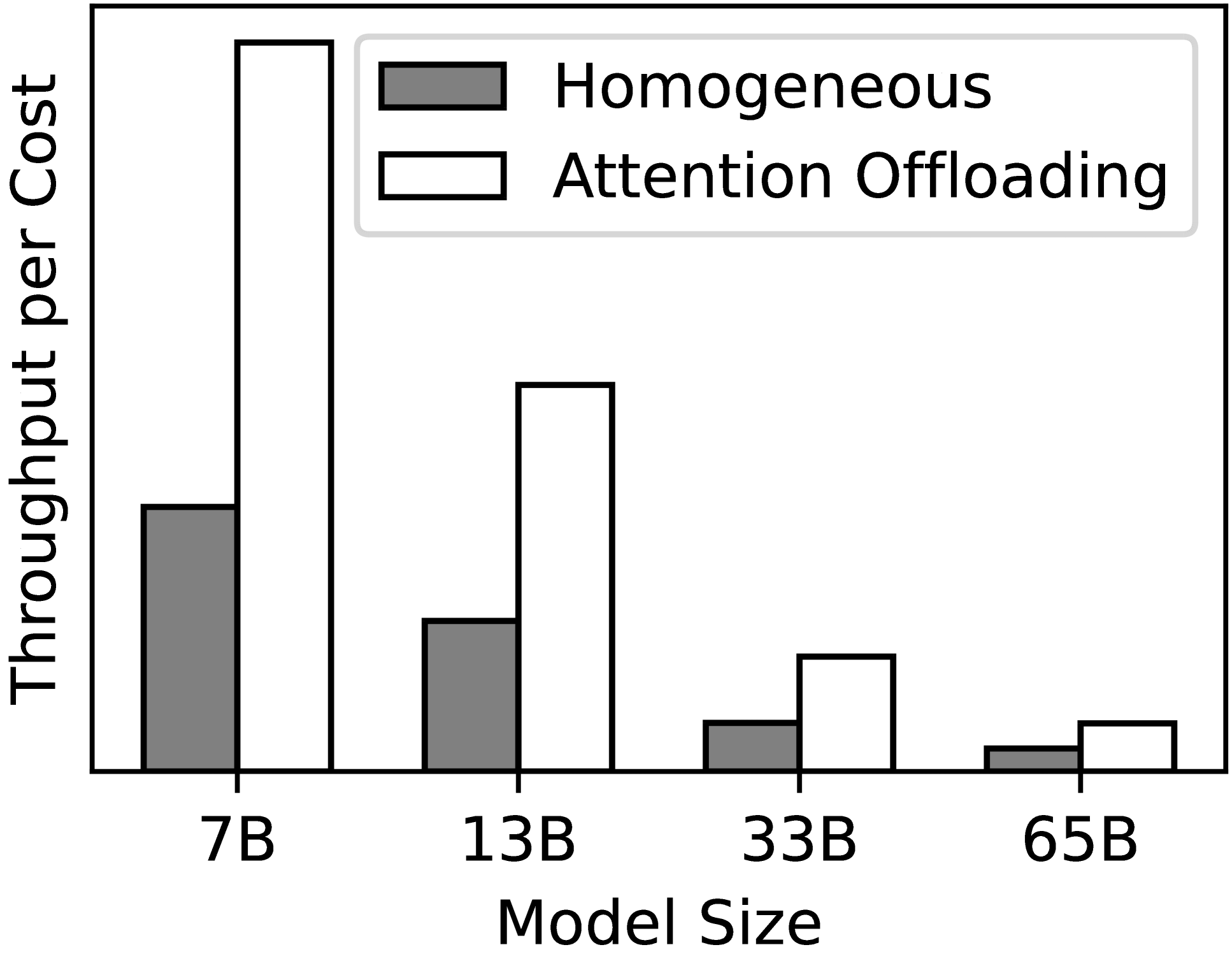
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
0
0
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
5/6/2024
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, Shengen Yan, Guohao Dai, Xiao-Ping Zhang, Yuhan Dong, Yu Wang
0
0
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
6/11/2024
💬
Transformer-Lite: High-efficiency Deployment of Large Language Models on Mobile Phone GPUs
Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie
0
0
The Large Language Model (LLM) is widely employed for tasks such as intelligent assistants, text summarization, translation, and multi-modality on mobile phones. However, the current methods for on-device LLM deployment maintain slow inference speed, which causes poor user experience. To facilitate high-efficiency LLM deployment on device GPUs, we propose four optimization techniques: (a) a symbolic expression-based approach to support dynamic shape model inference; (b) operator optimizations and execution priority setting to enhance inference speed and reduce phone lagging; (c) an FP4 quantization method termed M0E4 to reduce dequantization overhead; (d) a sub-tensor-based technique to eliminate the need for copying KV cache after LLM inference. Furthermore, we implement these methods in our mobile inference engine, Transformer-Lite, which is compatible with both Qualcomm and MTK processors. We evaluated Transformer-Lite's performance using LLMs with varied architectures and parameters ranging from 2B to 14B. Specifically, we achieved prefill and decoding speeds of 121 token/s and 14 token/s for ChatGLM2 6B, and 330 token/s and 30 token/s for smaller Gemma 2B, respectively. Compared with CPU-based FastLLM and GPU-based MLC-LLM, our engine attains over 10x speedup for the prefill speed and 2~3x speedup for the decoding speed.
5/22/2024
🛠️
Edge Intelligence Optimization for Large Language Model Inference with Batching and Quantization
Xinyuan Zhang, Jiang Liu, Zehui Xiong, Yudong Huang, Gaochang Xie, Ran Zhang
0
0
Generative Artificial Intelligence (GAI) is taking the world by storm with its unparalleled content creation ability. Large Language Models (LLMs) are at the forefront of this movement. However, the significant resource demands of LLMs often require cloud hosting, which raises issues regarding privacy, latency, and usage limitations. Although edge intelligence has long been utilized to solve these challenges by enabling real-time AI computation on ubiquitous edge resources close to data sources, most research has focused on traditional AI models and has left a gap in addressing the unique characteristics of LLM inference, such as considerable model size, auto-regressive processes, and self-attention mechanisms. In this paper, we present an edge intelligence optimization problem tailored for LLM inference. Specifically, with the deployment of the batching technique and model quantization on resource-limited edge devices, we formulate an inference model for transformer decoder-based LLMs. Furthermore, our approach aims to maximize the inference throughput via batch scheduling and joint allocation of communication and computation resources, while also considering edge resource constraints and varying user requirements of latency and accuracy. To address this NP-hard problem, we develop an optimal Depth-First Tree-Searching algorithm with online tree-Pruning (DFTSP) that operates within a feasible time complexity. Simulation results indicate that DFTSP surpasses other batching benchmarks in throughput across diverse user settings and quantization techniques, and it reduces time complexity by over 45% compared to the brute-force searching method.
5/14/2024