Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads

0

Sign in to get full access
Overview
- The paper proposes an efficient approach for training and serving large language models (LLMs) using heterogeneous context sharding among attention heads.
- The method aims to improve the efficiency of LLM inference and training by selectively processing only the relevant context for each attention head.
- The authors demonstrate the effectiveness of their approach through experiments on various LLM architectures and tasks.
Plain English Explanation
The paper introduces a new way to train and use large language models (LLMs) more efficiently. LLMs are powerful AI models that can understand and generate human-like text, but they often require a lot of computing power and memory to run.
The key idea is to divide the context (the information the model uses to make predictions) into smaller, specialized pieces, and then only process the parts that are relevant for each part of the model. This is called heterogeneous context sharding.
For example, imagine an LLM that needs to understand a long document. Instead of processing the entire document at once, the model would only look at the parts of the document that are most important for each different part of the model's decision-making process. This allows the model to run more efficiently, without sacrificing too much accuracy.
The authors show that this approach can improve the speed and memory usage of LLM training and inference (when the model is actually making predictions) across a variety of different LLM architectures and tasks. This could make LLMs more practical and accessible for a wider range of real-world applications.
Technical Explanation
The paper presents a novel technique called Heterogeneous Context Sharding (HCS) for efficient training and serving of large language models (LLMs). The key insight is that different attention heads in an LLM may require access to different parts of the context, and so it is not necessary to process the entire context for each head.
The authors propose to divide the context into smaller, specialized 'shards' that are then selectively processed by the different attention heads. This reduces the overall computational and memory requirements of the model, as each head only needs to handle the relevant parts of the context.
The authors evaluate their HCS approach on various LLM architectures and tasks, including [object Object] and [object Object]. They demonstrate significant improvements in terms of inference speed, memory usage, and training efficiency compared to baseline approaches that process the entire context.
The HCS technique builds on prior work on [object Object] and [object Object], which have also explored ways to improve the efficiency of LLM inference and training. The authors show how their approach can be combined with these other techniques to achieve even greater efficiency gains.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the HCS approach, demonstrating its effectiveness across a range of LLM architectures and tasks. The authors have carefully considered the potential limitations and caveats of their method, such as the trade-offs between efficiency gains and potential accuracy decreases.
One potential area for further research could be exploring how the HCS approach might interact with other optimization techniques, such as [object Object] or [object Object]. It would be interesting to see if combining multiple optimization strategies could lead to even greater efficiency improvements without significant accuracy loss.
Additionally, the authors could investigate the impact of HCS on the interpretability and explainability of LLMs. Since the method selectively processes different parts of the context, it may affect the model's ability to provide insights into its decision-making process.
Overall, the paper presents a compelling and well-executed approach to improving the efficiency of LLM training and inference, which could have significant practical implications for the widespread deployment of these powerful models.
Conclusion
The paper introduces a novel Heterogeneous Context Sharding (HCS) technique that can significantly improve the efficiency of training and serving large language models (LLMs). By selectively processing only the relevant parts of the context for each attention head, HCS reduces the computational and memory requirements of LLMs without compromising their performance.
The authors demonstrate the effectiveness of their approach across a range of LLM architectures and tasks, showing substantial improvements in inference speed, memory usage, and training efficiency. This could make LLMs more practical and accessible for a wider range of real-world applications, furthering the progress of this transformative technology.
The paper also highlights areas for future research, such as exploring the combination of HCS with other optimization techniques and investigating its impact on model interpretability. Overall, the HCS method represents an important contribution to the ongoing efforts to make large language models more efficient and widely deployable.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient LLM Training and Serving with Heterogeneous Context Sharding among Attention Heads
Xihui Lin, Yunan Zhang, Suyu Ge, Barun Patra, Vishrav Chaudhary, Hao Peng, Xia Song
Existing LLM training and inference frameworks struggle in boosting efficiency with sparsity while maintaining the integrity of context and model architecture. Inspired by the sharding concept in database and the fact that attention parallelizes over heads on accelerators, we propose Sparsely-Sharded (S2) Attention, an attention algorithm that allocates heterogeneous context partitions for different attention heads to divide and conquer. S2-Attention enforces each attention head to only attend to a partition of contexts following a strided sparsity pattern, while the full context is preserved as the union of all the shards. As attention heads are processed in separate thread blocks, the context reduction for each head can thus produce end-to-end speed-up and memory reduction. At inference, LLMs trained with S2-Attention can then take the KV cache reduction as free meals with guaranteed model quality preserve. In experiments, we show S2-Attentioncan provide as much as (1) 25.3X wall-clock attention speed-up over FlashAttention-2, resulting in 6X reduction in end-to-end training time and 10X inference latency, (2) on-par model training quality compared to default attention, (3)perfect needle retrieval accuracy over 32K context window. On top of the algorithm, we build DKernel, an LLM training and inference kernel library that allows users to customize sparsity patterns for their own models. We open-sourced DKerneland make it compatible with Megatron, Pytorch, and vLLM.
Read more8/29/2024

0
Near-Lossless Acceleration of Long Context LLM Inference with Adaptive Structured Sparse Attention
Qianchao Zhu, Jiangfei Duan, Chang Chen, Siran Liu, Xiuhong Li, Guanyu Feng, Xin Lv, Huanqi Cao, Xiao Chuanfu, Xingcheng Zhang, Dahua Lin, Chao Yang
Large language models (LLMs) now support extremely long context windows, but the quadratic complexity of vanilla attention results in significantly long Time-to-First-Token (TTFT) latency. Existing approaches to address this complexity require additional pretraining or finetuning, and often sacrifice model accuracy. In this paper, we first provide both theoretical and empirical foundations for near-lossless sparse attention. We find dynamically capturing head-specific sparse patterns at runtime with low overhead is crucial. To address this, we propose SampleAttention, an adaptive structured and near-lossless sparse attention. Leveraging observed significant sparse patterns, SampleAttention attends to a fixed percentage of adjacent tokens to capture local window patterns, and employs a two-stage query-guided key-value filtering approach, which adaptively select a minimum set of key-values with low overhead, to capture column stripe patterns. Comprehensive evaluations show that SampleAttention can seamlessly replace vanilla attention in off-the-shelf LLMs with nearly no accuracy loss, and reduces TTFT by up to $2.42times$ compared with FlashAttention.
Read more7/1/2024

0
Infinite-LLM: Efficient LLM Service for Long Context with DistAttention and Distributed KVCache
Bin Lin, Chen Zhang, Tao Peng, Hanyu Zhao, Wencong Xiao, Minmin Sun, Anmin Liu, Zhipeng Zhang, Lanbo Li, Xiafei Qiu, Shen Li, Zhigang Ji, Tao Xie, Yong Li, Wei Lin
Large Language Models (LLMs) demonstrate substantial potential across a diverse array of domains via request serving. However, as trends continue to push for expanding context sizes, the autoregressive nature of LLMs results in highly dynamic behavior of the attention layers, showcasing significant differences in computational characteristics and memory requirements from the non-attention layers. This presents substantial challenges for resource management and performance optimization in service systems. Existing static model parallelism and resource allocation strategies fall short when dealing with this dynamicity. To address the issue, we propose Infinite-LLM, a novel LLM serving system designed to effectively handle dynamic context lengths. Infinite-LLM disaggregates attention layers from an LLM's inference process, facilitating flexible and independent resource scheduling that optimizes computational performance and enhances memory utilization jointly. By leveraging a pooled GPU memory strategy across a cluster, Infinite-LLM not only significantly boosts system throughput but also supports extensive context lengths. Evaluated on a dataset with context lengths ranging from a few to 2000K tokens across a cluster with 32 A100 GPUs, Infinite-LLM demonstrates throughput improvement of 1.35-3.4x compared to state-of-the-art methods, enabling efficient and elastic LLM deployment.
Read more7/8/2024
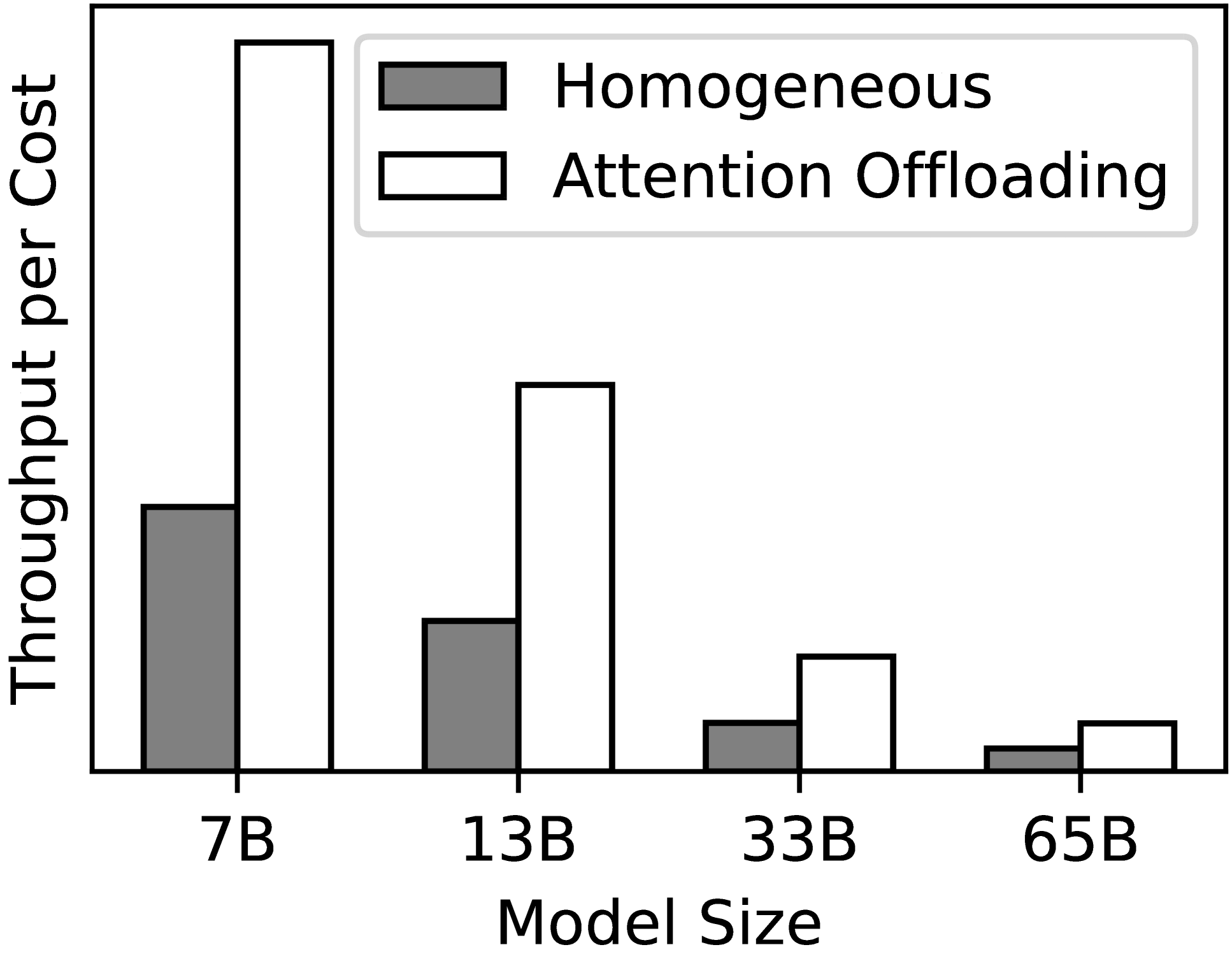
0
Efficient and Economic Large Language Model Inference with Attention Offloading
Shaoyuan Chen, Yutong Lin, Mingxing Zhang, Yongwei Wu
Transformer-based large language models (LLMs) exhibit impressive performance in generative tasks but introduce significant challenges in real-world serving due to inefficient use of the expensive, computation-optimized accelerators. This mismatch arises from the autoregressive nature of LLMs, where the generation phase comprises operators with varying resource demands. Specifically, the attention operator is memory-intensive, exhibiting a memory access pattern that clashes with the strengths of modern accelerators, especially as context length increases. To enhance the efficiency and cost-effectiveness of LLM serving, we introduce the concept of attention offloading. This approach leverages a collection of cheap, memory-optimized devices for the attention operator while still utilizing high-end accelerators for other parts of the model. This heterogeneous setup ensures that each component is tailored to its specific workload, maximizing overall performance and cost efficiency. Our comprehensive analysis and experiments confirm the viability of splitting the attention computation over multiple devices. Also, the communication bandwidth required between heterogeneous devices proves to be manageable with prevalent networking technologies. To further validate our theory, we develop Lamina, an LLM inference system that incorporates attention offloading. Experimental results indicate that Lamina can provide 1.48x-12.1x higher estimated throughput per dollar than homogeneous solutions.
Read more5/6/2024