Efficient Multi-agent Navigation with Lightweight DRL Policy

0
Sign in to get full access
Overview
- This paper proposes an efficient multi-agent navigation system using a lightweight deep reinforcement learning (DRL) policy.
- The goal is to enable a group of agents to navigate through a complex environment while avoiding collisions with each other and static obstacles.
- The authors introduce a novel DRL policy that is computationally efficient and can be deployed on resource-constrained devices.
Plain English Explanation
The paper describes a way to help a group of robots or other autonomous agents navigate through a cluttered environment without running into each other or stationary objects. The key idea is to use a form of machine learning called deep reinforcement learning to teach the agents how to move around safely.
Unlike some previous approaches that required a lot of computing power, the authors developed a "lightweight" deep reinforcement learning policy that can run efficiently even on devices with limited resources. This makes it practical to deploy their system in real-world scenarios like robot swarms or self-driving cars.
The agents learn through trial and error, getting rewarded when they reach their destination without colliding with anything. Over time, the neural network-based policy they develop becomes skilled at navigating around obstacles and coordinating their movements to avoid crashes. This allows the group of agents to travel through complex environments quickly and safely.
Technical Explanation
The paper presents a deep reinforcement learning approach for efficient multi-agent navigation. The key contributions are:
-
A lightweight DRL policy that can be deployed on resource-constrained devices. This is achieved by reducing the size of the neural network model while preserving navigation performance.
-
A multi-agent training framework that enables the agents to learn collision-free navigation through decentralized and emergent coordination, without requiring explicit inter-agent communication.
-
Comprehensive simulations demonstrating the superior navigation efficiency and scalability of the proposed approach compared to baseline methods, in terms of success rate, travel time, and computational cost.
The authors model the multi-agent navigation problem as a Markov Decision Process, where each agent observes its local environment and takes actions to reach its goal while avoiding collisions. The DRL policy is trained using proximal policy optimization (PPO), a popular reinforcement learning algorithm.
To reduce the computational complexity of the DRL policy, the authors employ techniques such as model compression, parameter sharing, and efficient feature extraction. This results in a compact neural network architecture that can be deployed on embedded devices with limited resources.
During training, the agents learn to navigate through the environment by receiving rewards for reaching their goals and penalties for collisions. Through this decentralized learning process, the agents develop coordinated behaviors that allow them to efficiently navigate as a group, without the need for explicit communication.
The paper presents extensive simulation results across various scenarios, including narrow passages, dynamic obstacles, and large-scale environments. The proposed approach is shown to outperform baseline methods in terms of success rate, travel time, and computational cost, demonstrating its potential for real-world applications.
Critical Analysis
The paper presents a compelling approach to efficient multi-agent navigation using a lightweight DRL policy. The key strengths of the work are:
- The ability to deploy the navigation system on resource-constrained devices, which expands the potential applications beyond powerful compute platforms.
- The decentralized training approach that enables the agents to learn coordinated behaviors without explicit communication, which is a desirable property for scalable multi-agent systems.
- The comprehensive simulation results that demonstrate the effectiveness of the proposed method across a variety of challenging scenarios.
However, the paper also has some limitations that could be addressed in future research:
- The evaluation is primarily focused on simulation-based experiments, and it would be valuable to see the system's performance in real-world robotic or vehicular environments.
- The paper does not explore the system's robustness to sensor noise, communication failures, or other real-world uncertainties that could affect the navigation performance.
- The training process and hyperparameter tuning are not described in detail, making it difficult to reproduce the results or apply the approach to different domains.
Overall, the paper presents a promising step towards efficient and scalable multi-agent navigation systems, with potential applications in robotics, autonomous vehicles, and other domains. Further research and real-world validation could help strengthen the impact of this work.
Conclusion
This paper introduces an efficient multi-agent navigation system that uses a lightweight deep reinforcement learning policy. The key contributions are a computationally efficient DRL policy that can be deployed on resource-constrained devices, and a decentralized training approach that enables the agents to learn coordinated behaviors without explicit communication.
The comprehensive simulation results demonstrate the superior performance of the proposed method compared to baseline approaches, in terms of success rate, travel time, and computational cost. This suggests that the system could be a valuable tool for real-world applications, such as robot swarms, autonomous vehicles, and other multi-agent systems operating in complex environments.
While the paper focuses on simulation-based evaluation, further research and real-world validation could help to fully realize the potential of this work and address the identified limitations. Overall, the paper presents an important step forward in the development of efficient and scalable multi-agent navigation systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Multi-agent Navigation with Lightweight DRL Policy
Xingrong Diao, Jiankun Wang
In this article, we present an end-to-end collision avoidance policy based on deep reinforcement learning (DRL) for multi-agent systems, demonstrating encouraging outcomes in real-world applications. In particular, our policy calculates the control commands of the agent based on the raw LiDAR observation. In addition, the number of parameters of the proposed basic model is 140,000, and the size of the parameter file is 3.5 MB, which allows the robot to calculate the actions from the CPU alone. We propose a multi-agent training platform based on a physics-based simulator to further bridge the gap between simulation and the real world. The policy is trained on a policy-gradients-based RL algorithm in a dense and messy training environment. A novel reward function is introduced to address the issue of agents choosing suboptimal actions in some common scenarios. Although the data used for training is exclusively from the simulation platform, the policy can be successfully transferred and deployed in real-world robots. Finally, our policy effectively responds to intentional obstructions and avoids collisions. The website is available at url{https://sites.google.com/view/xingrong2024efficient/%E9%A6%96%E9%A1%B5}.
Read more9/5/2024

0
Collision Avoidance and Navigation for a Quadrotor Swarm Using End-to-end Deep Reinforcement Learning
Zhehui Huang, Zhaojing Yang, Rahul Krupani, Bask{i}n c{S}enbac{s}lar, Sumeet Batra, Gaurav S. Sukhatme
End-to-end deep reinforcement learning (DRL) for quadrotor control promises many benefits -- easy deployment, task generalization and real-time execution capability. Prior end-to-end DRL-based methods have showcased the ability to deploy learned controllers onto single quadrotors or quadrotor teams maneuvering in simple, obstacle-free environments. However, the addition of obstacles increases the number of possible interactions exponentially, thereby increasing the difficulty of training RL policies. In this work, we propose an end-to-end DRL approach to control quadrotor swarms in environments with obstacles. We provide our agents a curriculum and a replay buffer of the clipped collision episodes to improve performance in obstacle-rich environments. We implement an attention mechanism to attend to the neighbor robots and obstacle interactions - the first successful demonstration of this mechanism on policies for swarm behavior deployed on severely compute-constrained hardware. Our work is the first work that demonstrates the possibility of learning neighbor-avoiding and obstacle-avoiding control policies trained with end-to-end DRL that transfers zero-shot to real quadrotors. Our approach scales to 32 robots with 80% obstacle density in simulation and 8 robots with 20% obstacle density in physical deployment. Video demonstrations are available on the project website at: https://sites.google.com/view/obst-avoid-swarm-rl.
Read more5/7/2024
0
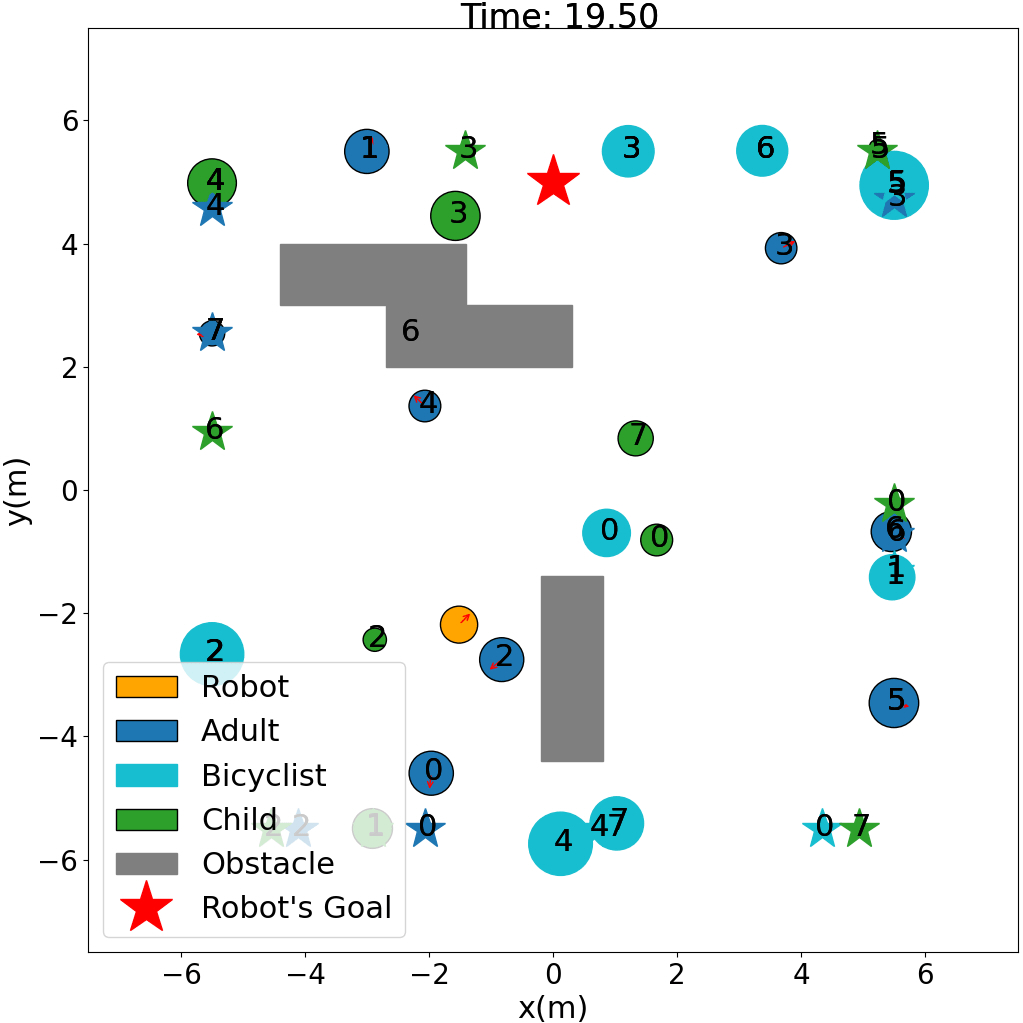
Robot Navigation with Entity-Based Collision Avoidance using Deep Reinforcement Learning
Yury Kolomeytsev, Dmitry Golembiovsky
Efficient navigation in dynamic environments is crucial for autonomous robots interacting with various environmental entities, including both moving agents and static obstacles. In this study, we present a novel methodology that enhances the robot's interaction with different types of agents and obstacles based on specific safety requirements. This approach uses information about the entity types, improving collision avoidance and ensuring safer navigation. We introduce a new reward function that penalizes the robot for collisions with different entities such as adults, bicyclists, children, and static obstacles, and additionally encourages the robot's proximity to the goal. It also penalizes the robot for being close to entities, and the safe distance also depends on the entity type. Additionally, we propose an optimized algorithm for training and testing, which significantly accelerates train, validation, and test steps and enables training in complex environments. Comprehensive experiments conducted using simulation demonstrate that our approach consistently outperforms conventional navigation and collision avoidance methods, including state-of-the-art techniques. To sum up, this work contributes to enhancing the safety and efficiency of navigation systems for autonomous robots in dynamic, crowded environments.
Read more8/27/2024
0
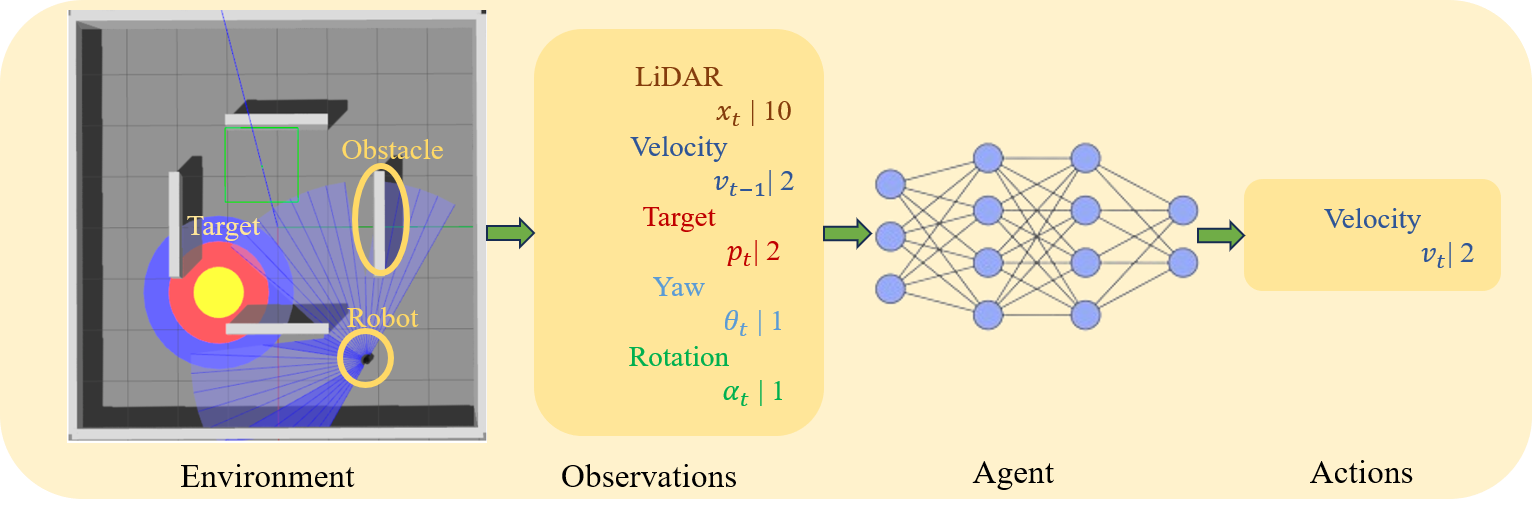
Deep Reinforcement Learning with Enhanced PPO for Safe Mobile Robot Navigation
Hamid Taheri, Seyed Rasoul Hosseini, Mohammad Ali Nekoui
Collision-free motion is essential for mobile robots. Most approaches to collision-free and efficient navigation with wheeled robots require parameter tuning by experts to obtain good navigation behavior. This study investigates the application of deep reinforcement learning to train a mobile robot for autonomous navigation in a complex environment. The robot utilizes LiDAR sensor data and a deep neural network to generate control signals guiding it toward a specified target while avoiding obstacles. We employ two reinforcement learning algorithms in the Gazebo simulation environment: Deep Deterministic Policy Gradient and proximal policy optimization. The study introduces an enhanced neural network structure in the Proximal Policy Optimization algorithm to boost performance, accompanied by a well-designed reward function to improve algorithm efficacy. Experimental results conducted in both obstacle and obstacle-free environments underscore the effectiveness of the proposed approach. This research significantly contributes to the advancement of autonomous robotics in complex environments through the application of deep reinforcement learning.
Read more8/9/2024