MAexp: A Generic Platform for RL-based Multi-Agent Exploration
2404.12824
0
0
Abstract
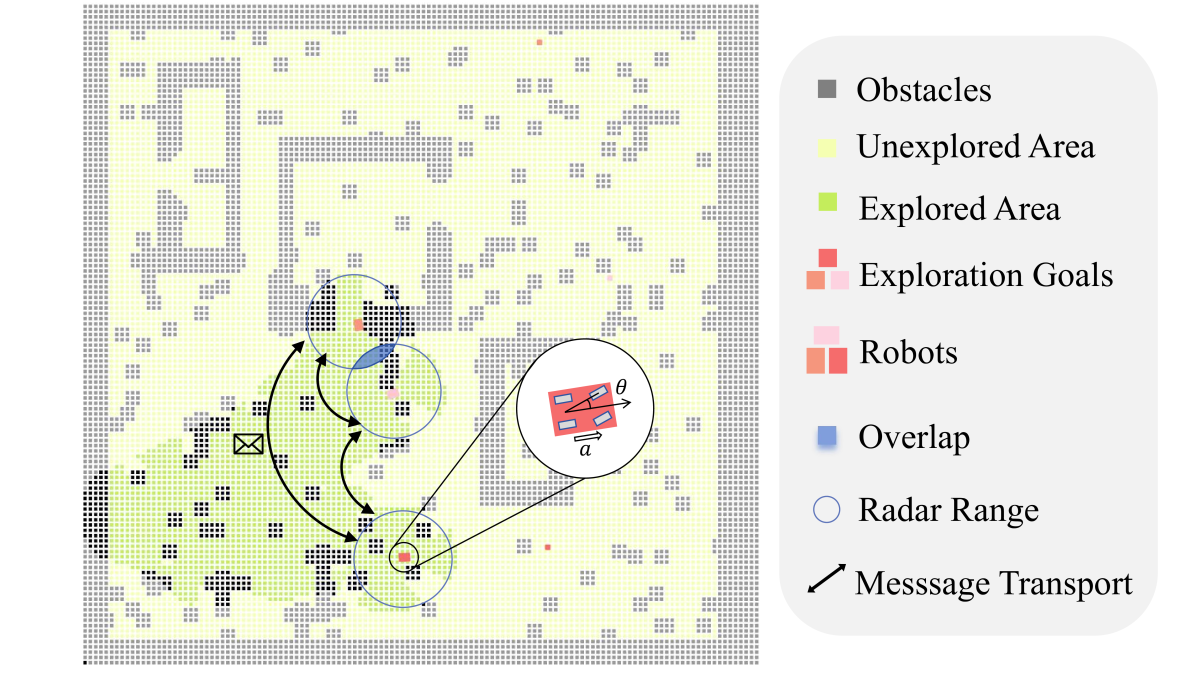
The sim-to-real gap poses a significant challenge in RL-based multi-agent exploration due to scene quantization and action discretization. Existing platforms suffer from the inefficiency in sampling and the lack of diversity in Multi-Agent Reinforcement Learning (MARL) algorithms across different scenarios, restraining their widespread applications. To fill these gaps, we propose MAexp, a generic platform for multi-agent exploration that integrates a broad range of state-of-the-art MARL algorithms and representative scenarios. Moreover, we employ point clouds to represent our exploration scenarios, leading to high-fidelity environment mapping and a sampling speed approximately 40 times faster than existing platforms. Furthermore, equipped with an attention-based Multi-Agent Target Generator and a Single-Agent Motion Planner, MAexp can work with arbitrary numbers of agents and accommodate various types of robots. Extensive experiments are conducted to establish the first benchmark featuring several high-performance MARL algorithms across typical scenarios for robots with continuous actions, which highlights the distinct strengths of each algorithm in different scenarios.
Create account to get full access
Overview
- Introduces MAexp, a generic platform for reinforcement learning-based multi-agent exploration
- Aims to provide a flexible and scalable framework for developing and evaluating multi-agent exploration algorithms
- Supports various exploration scenarios, agent types, and reward structures
Plain English Explanation
MAexp is a platform that allows researchers and developers to test and evaluate different algorithms for multi-agent exploration. In other words, it's a tool that helps them figure out the best ways for groups of artificial agents to explore and learn about their environment.
The platform is designed to be flexible, meaning it can be used to simulate a wide range of exploration scenarios, from simple to complex. It can also handle different types of agents, with varying capabilities, and lets researchers experiment with different reward structures to see how that affects the agents' behavior.
By providing a standardized and customizable environment, MAexp makes it easier for researchers to compare and build upon each other's work in the field of multi-agent reinforcement learning. This can lead to the development of more effective exploration algorithms, which could have applications in areas like robotics, autonomous vehicles, and even video games.
Technical Explanation
MAexp is a generic platform for reinforcement learning-based multi-agent exploration. It aims to provide a flexible and scalable framework for developing and evaluating multi-agent exploration algorithms. The platform supports various exploration scenarios, agent types, and reward structures, allowing researchers to test and compare different approaches.
The platform is designed with modularity in mind, enabling users to easily customize the environment, agent behaviors, and reward functions. This flexibility allows for the exploration of a wide range of multi-agent exploration problems, from simple cooperative tasks to more complex competitive or adversarial scenarios.
MAexp incorporates several key features, such as the ability to define custom agent types with varying capabilities, the option to specify different reward structures (e.g., shaped rewards, sparse rewards), and the support for both centralized and decentralized learning algorithms.
The platform also provides a suite of evaluation metrics and visualizations to help researchers analyze the performance and behavior of their exploration algorithms. This includes measures of exploration coverage, task completion, and agent coordination, among others.
Critical Analysis
The MAexp platform represents a valuable contribution to the field of multi-agent reinforcement learning, as it addresses the need for a standardized and flexible framework for evaluating exploration algorithms.
One potential limitation of the platform is that it may not capture the full complexity of real-world exploration scenarios, which can involve factors like sensor noise, dynamic environments, and heterogeneous agent capabilities. Additionally, the platform's reliance on simulated environments may limit the transferability of the learned algorithms to physical systems.
Further research could explore ways to bridge the gap between simulation and reality, such as by incorporating more realistic physics models or integrating the platform with physical robotic platforms.
Conclusion
MAexp is a powerful platform that enables researchers to develop and evaluate multi-agent exploration algorithms in a flexible and scalable manner. By providing a standardized environment and a suite of evaluation tools, the platform can help advance the state of the art in multi-agent reinforcement learning and contribute to the development of more effective exploration strategies.
The platform's modular design and support for various exploration scenarios and agent types make it a valuable resource for the research community. As the field of multi-agent exploration continues to evolve, tools like MAexp will play an increasingly important role in driving innovation and pushing the boundaries of what is possible in this exciting domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024
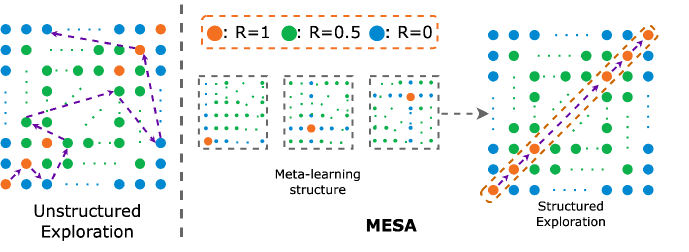
MESA: Cooperative Meta-Exploration in Multi-Agent Learning through Exploiting State-Action Space Structure
Zhicheng Zhang, Yancheng Liang, Yi Wu, Fei Fang
0
0
Multi-agent reinforcement learning (MARL) algorithms often struggle to find strategies close to Pareto optimal Nash Equilibrium, owing largely to the lack of efficient exploration. The problem is exacerbated in sparse-reward settings, caused by the larger variance exhibited in policy learning. This paper introduces MESA, a novel meta-exploration method for cooperative multi-agent learning. It learns to explore by first identifying the agents' high-rewarding joint state-action subspace from training tasks and then learning a set of diverse exploration policies to cover the subspace. These trained exploration policies can be integrated with any off-policy MARL algorithm for test-time tasks. We first showcase MESA's advantage in a multi-step matrix game. Furthermore, experiments show that with learned exploration policies, MESA achieves significantly better performance in sparse-reward tasks in several multi-agent particle environments and multi-agent MuJoCo environments, and exhibits the ability to generalize to more challenging tasks at test time.
5/3/2024
🏅
Randomized Exploration in Cooperative Multi-Agent Reinforcement Learning
Hao-Lun Hsu, Weixin Wang, Miroslav Pajic, Pan Xu
0
0
We present the first study on provably efficient randomized exploration in cooperative multi-agent reinforcement learning (MARL). We propose a unified algorithm framework for randomized exploration in parallel Markov Decision Processes (MDPs), and two Thompson Sampling (TS)-type algorithms, CoopTS-PHE and CoopTS-LMC, incorporating the perturbed-history exploration (PHE) strategy and the Langevin Monte Carlo exploration (LMC) strategy respectively, which are flexible in design and easy to implement in practice. For a special class of parallel MDPs where the transition is (approximately) linear, we theoretically prove that both CoopTS-PHE and CoopTS-LMC achieve a $widetilde{mathcal{O}}(d^{3/2}H^2sqrt{MK})$ regret bound with communication complexity $widetilde{mathcal{O}}(dHM^2)$, where $d$ is the feature dimension, $H$ is the horizon length, $M$ is the number of agents, and $K$ is the number of episodes. This is the first theoretical result for randomized exploration in cooperative MARL. We evaluate our proposed method on multiple parallel RL environments, including a deep exploration problem (textit{i.e.,} $N$-chain), a video game, and a real-world problem in energy systems. Our experimental results support that our framework can achieve better performance, even under conditions of misspecified transition models. Additionally, we establish a connection between our unified framework and the practical application of federated learning.
4/17/2024

Representation Learning For Efficient Deep Multi-Agent Reinforcement Learning
Dom Huh, Prasant Mohapatra
0
0
Sample efficiency remains a key challenge in multi-agent reinforcement learning (MARL). A promising approach is to learn a meaningful latent representation space through auxiliary learning objectives alongside the MARL objective to aid in learning a successful control policy. In our work, we present MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization) which applies a form of comprehensive representation learning devised to supplement MARL training. Specifically, MAPO-LSO proposes a multi-agent extension of transition dynamics reconstruction and self-predictive learning that constructs a latent state optimization scheme that can be trivially extended to current state-of-the-art MARL algorithms. Empirical results demonstrate MAPO-LSO to show notable improvements in sample efficiency and learning performance compared to its vanilla MARL counterpart without any additional MARL hyperparameter tuning on a diverse suite of MARL tasks.
6/6/2024