Efficient Multi-Task Large Model Training via Data Heterogeneity-aware Model Management

0
📈
Sign in to get full access
Overview
- Recent foundation models can handle multiple machine learning (ML) tasks and data types with a unified base model and specialized components
- However, training these multi-task (MT), multi-modal (MM) models poses significant challenges due to their complex architecture and heterogeneous workloads
- Requires massive GPU resources and suffers from sub-optimal system efficiency
Plain English Explanation
The paper discusses how recent advancements in foundation models have enabled models that can handle a wide variety of machine learning tasks and work with different types of data, such as text, images, and audio. These multi-task and multi-modal models use a common base model structure with specialized components.
However, training these complex models poses significant challenges for existing training systems. The heterogeneous nature of the different ML tasks and data types, as well as the sophisticated model architecture, requires massive GPU resources and results in suboptimal system efficiency.
Technical Explanation
The key idea of the research is to address these model management challenges through a data heterogeneity-aware approach. The researchers decompose the model execution into stages and solve the optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling.
Based on this approach, the researchers build a prototype system and evaluate it on various large-scale MT MM models. The experiments demonstrate that their system achieves superior performance and efficiency, with speedup ratios of up to 71% compared to state-of-the-art training systems.
Critical Analysis
The paper presents a novel and promising approach to addressing the model management challenges of large-scale MT MM models. However, it is important to note that the research is still in the prototype stage, and further evaluation and testing would be necessary to assess the real-world applicability and scalability of the proposed system.
Additionally, the paper does not provide a detailed analysis of the limitations or potential drawbacks of the approach, such as the impact on model quality or the specific trade-offs involved in the optimization process. Readers are encouraged to critically evaluate the research and consider these aspects when assessing the significance and implications of the work.
Conclusion
This research tackles the significant challenge of efficiently training large-scale multi-task, multi-modal machine learning models. By decomposing the model execution and addressing the optimization problem in a data heterogeneity-aware manner, the researchers have developed a prototype system that demonstrates substantial performance and efficiency improvements over existing training approaches.
The findings of this work have the potential to contribute to the ongoing development of more capable and versatile AI models, which could have far-reaching implications for a wide range of applications. However, further research and real-world testing are necessary to fully understand the merits and limitations of this approach.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Efficient Multi-Task Large Model Training via Data Heterogeneity-aware Model Management
Yujie Wang, Shenhan Zhu, Fangcheng Fu, Xupeng Miao, Jie Zhang, Juan Zhu, Fan Hong, Yong Li, Bin Cui
Recent foundation models are capable of handling multiple machine learning (ML) tasks and multiple data modalities with the unified base model structure and several specialized model components. However, the development of such multi-task (MT) multi-modal (MM) models poses significant model management challenges to existing training systems. Due to the sophisticated model architecture and the heterogeneous workloads of different ML tasks and data modalities, training these models usually requires massive GPU resources and suffers from sub-optimal system efficiency. In this paper, we investigate how to achieve high-performance training of large-scale MT MM models through data heterogeneity-aware model management optimization. The key idea is to decompose the model execution into stages and address the joint optimization problem sequentially, including both heterogeneity-aware workload parallelization and dependency-driven execution scheduling. Based on this, we build a prototype system and evaluate it on various large MT MM models. Experiments demonstrate the superior performance and efficiency of our system, with speedup ratio up to 71% compared to state-of-the-art training systems.
Read more9/6/2024

0
HetHub: A Heterogeneous distributed hybrid training system for large-scale models
Si Xu, Zixiao Huang, Yan Zeng, Shengen Yan, Xuefei Ning, Quanlu Zhang, Haolin Ye, Sipei Gu, Chunsheng Shui, Zhezheng Lin, Hao Zhang, Sheng Wang, Guohao Dai, Yu Wang
Training large-scale models relies on a vast number of computing resources. For example, training the GPT-4 model (1.8 trillion parameters) requires 25000 A100 GPUs . It is a challenge to build a large-scale cluster with one type of GPU-accelerator. Using multiple types of GPU-accelerators to construct a large-scale cluster is an effective way to solve the problem of insufficient homogeneous GPU-accelerators. However, the existing distributed training systems for large-scale models only support homogeneous GPU-accelerators, not support heterogeneous GPU-accelerators. To address the problem, this paper proposes a distributed training system with hybrid parallelism, HETHUB, for large-scale models, which supports heterogeneous cluster, including AMD, Nvidia GPU and other types of GPU-accelerators . It introduces a distributed unified communicator to realize the communication between heterogeneous GPU-accelerators, a distributed performance predictor, and an automatic parallel planner to develop and train models efficiently with heterogeneous GPU-accelerators. Compared to the distributed training system with homogeneous GPU-accelerators, our system can support six combinations of heterogeneous GPU-accelerators. We train the Llama-140B model on a heterogeneous cluster with 768 GPU-accelerators(128 AMD and 640 GPU-accelerator A). The experiment results show that the optimal performance of our system in the heterogeneous cluster has achieved up to 97.49% of the theoretical upper bound performance.
Read more8/12/2024
0
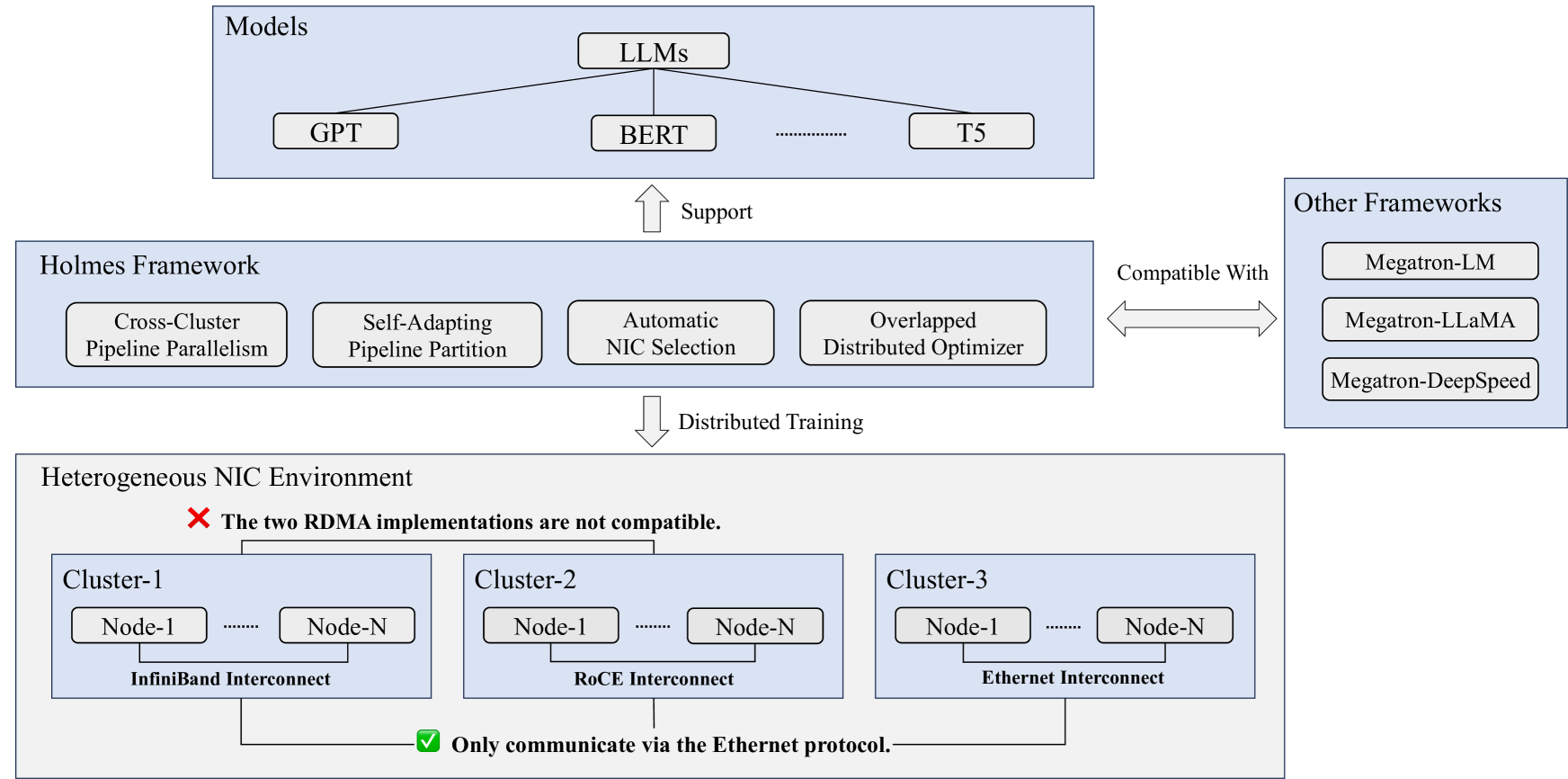
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Fei Yang, Shuang Peng, Ning Sun, Fangyu Wang, Yuanyuan Wang, Fu Wu, Jiezhong Qiu, Aimin Pan
Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
Read more4/30/2024
0
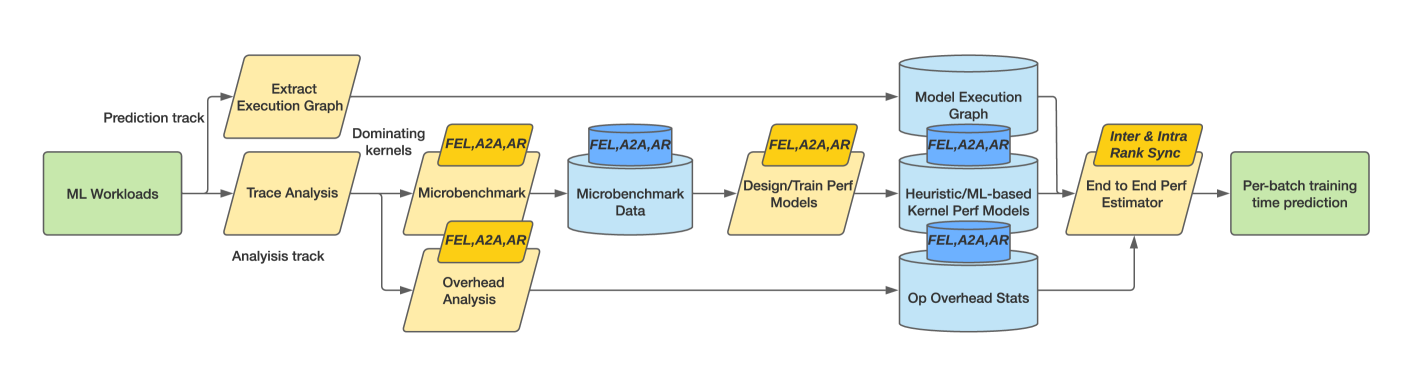
Towards Universal Performance Modeling for Machine Learning Training on Multi-GPU Platforms
Zhongyi Lin, Ning Sun, Pallab Bhattacharya, Xizhou Feng, Louis Feng, John D. Owens
Characterizing and predicting the training performance of modern machine learning (ML) workloads on compute systems with compute and communication spread between CPUs, GPUs, and network devices is not only the key to optimization and planning but also a complex goal to achieve. The primary challenges include the complexity of synchronization and load balancing between CPUs and GPUs, the variance in input data distribution, and the use of different communication devices and topologies (e.g., NVLink, PCIe, network cards) that connect multiple compute devices, coupled with the desire for flexible training configurations. Built on top of our prior work for single-GPU platforms, we address these challenges and enable multi-GPU performance modeling by incorporating (1) data-distribution-aware performance models for embedding table lookup, and (2) data movement prediction of communication collectives, into our upgraded performance modeling pipeline equipped with inter-and intra-rank synchronization for ML workloads trained on multi-GPU platforms. Beyond accurately predicting the per-iteration training time of DLRM models with random configurations with a geomean error of 5.21% on two multi-GPU platforms, our prediction pipeline generalizes well to other types of ML workloads, such as Transformer-based NLP models with a geomean error of 3.00%. Moreover, even without actually running ML workloads like DLRMs on the hardware, it is capable of generating insights such as quickly selecting the fastest embedding table sharding configuration (with a success rate of 85%).
Read more4/30/2024