Efficient Pre-training for Localized Instruction Generation of Videos

0

Sign in to get full access
Overview
- This paper presents an efficient pre-training strategy for generating localized video instructions.
- The authors propose a multi-task pre-training approach that jointly learns to localize and generate instructions for procedural videos.
- Their method outperforms previous state-of-the-art models on benchmark datasets for video instruction generation.
Plain English Explanation
The paper focuses on developing a more efficient way to train models that can generate step-by-step instructions for videos. This is a challenging task because the model needs to not only understand the video content, but also figure out what the key steps are and how to describe them clearly.
The researchers' key insight is to train the model on multiple related tasks at the same time, rather than just the final video instruction generation task. Specifically, they have the model also learn to identify the relevant steps and locations within the video that the instructions should cover. By learning these auxiliary tasks during pre-training, the model is better able to understand the structure of procedural videos and generate high-quality instructions.
This multi-task pre-training approach allows the model to build up a more robust understanding of the key elements needed for instruction generation, such as identifying step differences and correlating video content with text. The authors show that this leads to substantial performance improvements over prior methods for generating illustrated instructions on standard benchmarks.
Technical Explanation
The paper proposes an efficient pre-training strategy for the task of localized video instruction generation. The authors design a multi-task pre-training approach that jointly learns to localize relevant steps within procedural videos and generate natural language instructions describing those steps.
The pre-training tasks include:
- Step localization: Identifying the relevant steps and their temporal locations within the video.
- Instruction generation: Generating natural language descriptions for the localized steps.
By learning these auxiliary tasks during pre-training, the model is able to build up a more comprehensive understanding of the structure and content of procedural videos. This in turn allows the model to generate higher-quality instructions during the final fine-tuning stage.
The authors evaluate their approach on two benchmark datasets for video instruction generation. They show that their multi-task pre-trained model outperforms previous state-of-the-art methods that do not have this pre-training stage. The improvements are particularly significant for videos with more complex structures, demonstrating the value of the localization pre-training in capturing the nuances of procedural tasks.
Critical Analysis
The paper presents a well-designed and empirically validated approach for improving video instruction generation through efficient pre-training. The authors' key insight of leveraging auxiliary tasks like step localization is a clever way to bootstrap the model's understanding of procedural videos.
That said, the paper does not extensively discuss potential limitations or failure cases of their approach. For example, it's unclear how well the model would generalize to instructional videos with highly unusual or unseen structures, or whether the pre-training strategy is robust to noisy or partial video inputs.
Additionally, the authors could have provided more analysis on the relative importance of the different pre-training tasks. It would be interesting to know if certain tasks contribute more to the final performance than others, and whether there are optimal ways to balance the multi-task training.
Overall, this is a strong piece of research that advances the state-of-the-art in video instruction generation. The authors' approach of distilling vision-language models from millions of videos is a promising direction that deserves further exploration and refinement.
Conclusion
This paper presents an efficient pre-training strategy for generating localized instructions from procedural videos. By jointly learning to localize relevant steps and generate natural language descriptions, the model is able to build up a more comprehensive understanding of the structure and content of the videos.
The authors demonstrate that this multi-task pre-training approach outperforms previous state-of-the-art methods on standard benchmarks, particularly for more complex videos. This suggests that the ability to identify key steps and their temporal locations is critical for generating high-quality instructions.
The work represents an important advance in the field of video understanding and instruction generation. The insights from this paper could inform the development of more powerful models that can provide clear, step-by-step guidance from complex procedural videos, with applications in areas like education, DIY tutorials, and industrial training.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Pre-training for Localized Instruction Generation of Videos
Anil Batra, Davide Moltisanti, Laura Sevilla-Lara, Marcus Rohrbach, Frank Keller
Procedural videos, exemplified by recipe demonstrations, are instrumental in conveying step-by-step instructions. However, understanding such videos is challenging as it involves the precise localization of steps and the generation of textual instructions. Manually annotating steps and writing instructions is costly, which limits the size of current datasets and hinders effective learning. Leveraging large but noisy video-transcript datasets for pre-training can boost performance but demands significant computational resources. Furthermore, transcripts contain irrelevant content and differ in style from human-written instructions. To mitigate these issues, we propose a novel technique, Sieve-&-Swap, to automatically generate high-quality training data for the recipe domain: (i) Sieve: filters irrelevant transcripts and (ii) Swap: acquires high-quality text by replacing transcripts with human-written instruction from a text-only recipe dataset. The resulting dataset is three orders of magnitude smaller than current web-scale datasets but enables efficient training of large-scale models. Alongside Sieve-&-Swap, we propose Procedure Transformer (ProcX), a model for end-to-end step localization and instruction generation for procedural videos. When pre-trained on our curated dataset, this model achieves state-of-the-art performance on YouCook2 and Tasty while using a fraction of the training data. We have released code and dataset.
Read more7/23/2024

0
Order-Based Pre-training Strategies for Procedural Text Understanding
Abhilash Nandy, Yash Kulkarni, Pawan Goyal, Niloy Ganguly
In this paper, we propose sequence-based pretraining methods to enhance procedural understanding in natural language processing. Procedural text, containing sequential instructions to accomplish a task, is difficult to understand due to the changing attributes of entities in the context. We focus on recipes, which are commonly represented as ordered instructions, and use this order as a supervision signal. Our work is one of the first to compare several 'order as-supervision' transformer pre-training methods, including Permutation Classification, Embedding Regression, and Skip-Clip, and shows that these methods give improved results compared to the baselines and SoTA LLMs on two downstream Entity-Tracking datasets: NPN-Cooking dataset in recipe domain and ProPara dataset in open domain. Our proposed methods address the non-trivial Entity Tracking Task that requires prediction of entity states across procedure steps, which requires understanding the order of steps. These methods show an improvement over the best baseline by 1.6% and 7-9% on NPN-Cooking and ProPara Datasets respectively across metrics.
Read more4/9/2024

10
Step Differences in Instructional Video
Tushar Nagarajan, Lorenzo Torresani
Comparing a user video to a reference how-to video is a key requirement for AR/VR technology delivering personalized assistance tailored to the user's progress. However, current approaches for language-based assistance can only answer questions about a single video. We propose an approach that first automatically generates large amounts of visual instruction tuning data involving pairs of videos from HowTo100M by leveraging existing step annotations and accompanying narrations, and then trains a video-conditioned language model to jointly reason across multiple raw videos. Our model achieves state-of-the-art performance at identifying differences between video pairs and ranking videos based on the severity of these differences, and shows promising ability to perform general reasoning over multiple videos. Project page: https://github.com/facebookresearch/stepdiff
Read more7/1/2024
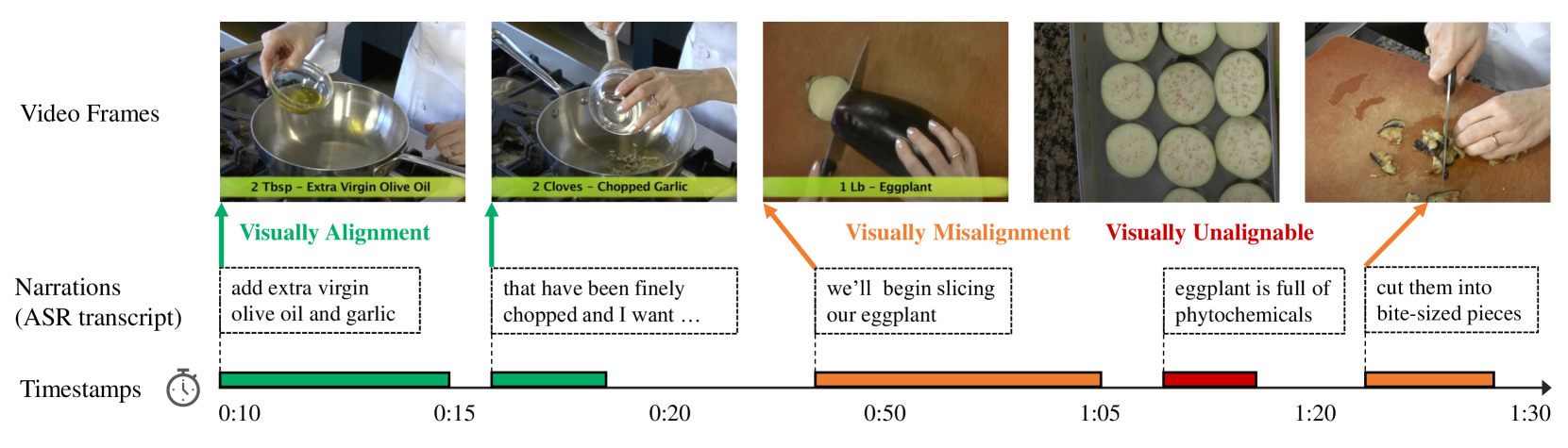
0
Multi-Sentence Grounding for Long-term Instructional Video
Zeqian Li, Qirui Chen, Tengda Han, Ya Zhang, Yanfeng Wang, Weidi Xie
In this paper, we aim to establish an automatic, scalable pipeline for denoising the large-scale instructional dataset and construct a high-quality video-text dataset with multiple descriptive steps supervision, named HowToStep. We make the following contributions: (i) improving the quality of sentences in dataset by upgrading ASR systems to reduce errors from speech recognition and prompting a large language model to transform noisy ASR transcripts into descriptive steps; (ii) proposing a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to temporally align the generated steps to corresponding video segments. To measure the quality of our curated datasets, we train models for the task of multi-sentence grounding on it, i.e., given a long-form video, and associated multiple sentences, to determine their corresponding timestamps in the video simultaneously, as a result, the model shows superior performance on a series of multi-sentence grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.0% on HT-Step, 5.1% on HTM-Align and 1.9% on CrossTask. All codes, models, and the resulting dataset have been publicly released.
Read more7/23/2024