Efficient Sample-Specific Encoder Perturbations

0

Sign in to get full access
Overview
- Introduces a technique for efficiently perturbing encoder models in a sample-specific manner
- Aims to improve the robustness and generalization of encoder models
- Presents a computationally efficient approach to generating sample-specific perturbations
Plain English Explanation
This research paper introduces a method for efficiently perturbing encoder models in a way that is specific to each input sample. The goal is to improve the robustness and generalization of these encoder models, which are commonly used in various machine learning tasks.
The key idea is to generate perturbations that are tailored to each individual input, rather than applying the same perturbations to all inputs. This allows the model to learn more nuanced and sample-specific representations, which can lead to better performance and increased resilience to noise or distortions in the input data.
The proposed approach is computationally efficient, making it practical to apply in real-world scenarios where processing time is a concern, such as in text-to-image generation or time series forecasting.
Technical Explanation
The paper introduces a method for efficiently perturbing encoder models in a sample-specific manner. The key idea is to generate perturbations that are tailored to each individual input, rather than applying the same perturbations to all inputs.
The approach involves training a small "perturbation network" that takes the input sample and the encoder's hidden representation as input, and outputs a sample-specific perturbation. This perturbation is then applied to the encoder's hidden representation, effectively modifying the input to the encoder in a way that is specific to each sample.
The authors show that this sample-specific perturbation technique can improve the robustness and generalization of the encoder model, leading to better performance on a variety of tasks. They also demonstrate that the approach is computationally efficient, making it practical to apply in real-world scenarios where processing time is a concern, such as in language model tuning or automatic speech recognition.
Critical Analysis
The paper presents a novel and promising approach to improving the robustness and generalization of encoder models. The sample-specific perturbation technique is a clever way to learn more nuanced representations that can better handle variations in the input data.
One potential limitation of the approach is that it requires training an additional "perturbation network," which adds complexity to the overall model and may increase the computational resources required. The authors acknowledge this and discuss strategies for making the perturbation network more efficient.
Another area for further research could be exploring the application of this technique to other types of encoder models, beyond the specific architectures used in the paper. It would be interesting to see how the sample-specific perturbations perform on a wider range of encoder-based models and tasks.
Overall, this research represents a valuable contribution to the field of machine learning, offering a practical solution for enhancing the performance and reliability of encoder models in various applications.
Conclusion
The paper presents an efficient technique for perturbing encoder models in a sample-specific manner, with the goal of improving the robustness and generalization of these models. By generating perturbations tailored to each input, the approach can lead to better performance on a variety of tasks, while remaining computationally efficient.
This research highlights the importance of considering the unique characteristics of each input sample when training machine learning models, and the potential benefits of developing specialized techniques for model adaptation and optimization. The sample-specific perturbation method could have far-reaching implications for the development of more reliable and versatile encoder-based systems, with applications spanning text-to-image generation, time series forecasting, language model tuning, and automatic speech recognition, among others.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Efficient Sample-Specific Encoder Perturbations
Yassir Fathullah, Mark J. F. Gales
Encoder-decoder foundation models have displayed state-of-the-art performance on a range of autoregressive sequence tasks. This paper proposes a simple and lightweight modification to such systems to control the behaviour according to a specific attribute of interest. This paper proposes a novel inference-efficient approach to modifying the behaviour of an encoder-decoder system according to a specific attribute of interest. Specifically, we show that a small proxy network can be used to find a sample-by-sample perturbation of the encoder output of a frozen foundation model to trigger the decoder to generate improved decodings. This work explores a specific realization of this framework focused on improving the COMET performance of Flan-T5 on Machine Translation and the WER of Whisper foundation models on Speech Recognition. Results display consistent improvements in performance evaluated through COMET and WER respectively. Furthermore, experiments also show that the proxies are robust to the exact nature of the data used to train them and can extend to other domains.
Read more5/6/2024
0
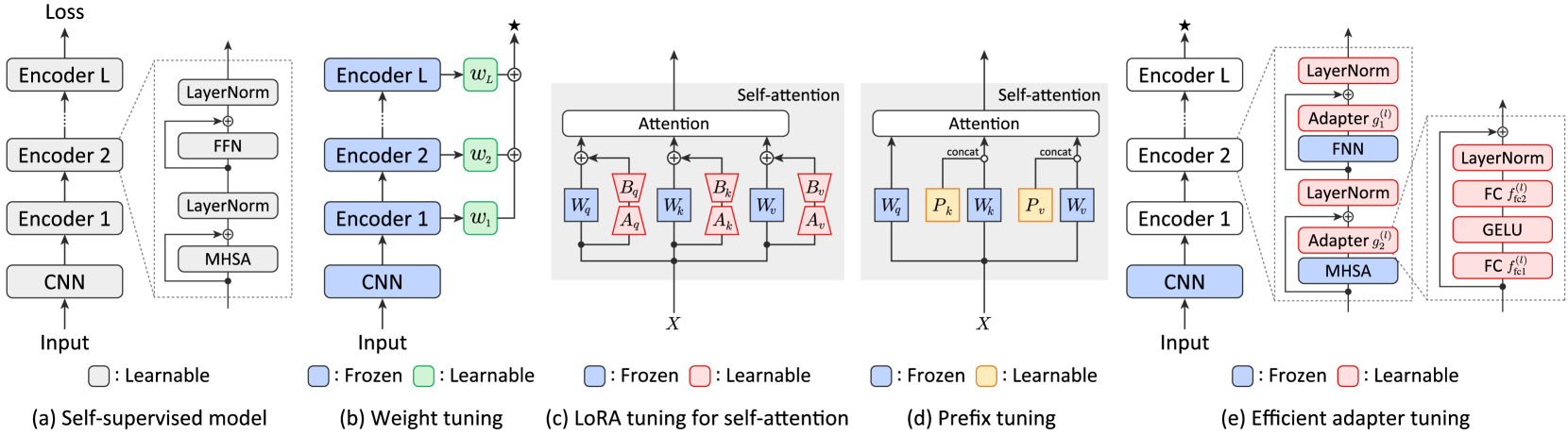
ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks
Nakamasa Inoue, Shinta Otake, Takumi Hirose, Masanari Ohi, Rei Kawakami
Self-supervised learning has emerged as a key approach for learning generic representations from speech data. Despite promising results in downstream tasks such as speech recognition, speaker verification, and emotion recognition, a significant number of parameters is required, which makes fine-tuning for each task memory-inefficient. To address this limitation, we introduce ELP-adapter tuning, a novel method for parameter-efficient fine-tuning using three types of adapter, namely encoder adapters (E-adapters), layer adapters (L-adapters), and a prompt adapter (P-adapter). The E-adapters are integrated into transformer-based encoder layers and help to learn fine-grained speech representations that are effective for speech recognition. The L-adapters create paths from each encoder layer to the downstream head and help to extract non-linguistic features from lower encoder layers that are effective for speaker verification and emotion recognition. The P-adapter appends pseudo features to CNN features to further improve effectiveness and efficiency. With these adapters, models can be quickly adapted to various speech processing tasks. Our evaluation across four downstream tasks using five backbone models demonstrated the effectiveness of the proposed method. With the WavLM backbone, its performance was comparable to or better than that of full fine-tuning on all tasks while requiring 90% fewer learnable parameters.
Read more8/1/2024
📈
3
A decoder-only foundation model for time-series forecasting
Abhimanyu Das, Weihao Kong, Rajat Sen, Yichen Zhou
Motivated by recent advances in large language models for Natural Language Processing (NLP), we design a time-series foundation model for forecasting whose out-of-the-box zero-shot performance on a variety of public datasets comes close to the accuracy of state-of-the-art supervised forecasting models for each individual dataset. Our model is based on pretraining a patched-decoder style attention model on a large time-series corpus, and can work well across different forecasting history lengths, prediction lengths and temporal granularities.
Read more4/19/2024
🛸
0
Continual Learning Optimizations for Auto-regressive Decoder of Multilingual ASR systems
Chin Yuen Kwok, Jia Qi Yip, Eng Siong Chng
Continual Learning (CL) involves fine-tuning pre-trained models with new data while maintaining the performance on the pre-trained data. This is particularly relevant for expanding multilingual ASR (MASR) capabilities. However, existing CL methods, mainly designed for computer vision and reinforcement learning tasks, often yield sub-optimal results when directly applied to MASR. We hypothesise that this is because CL of the auto-regressive decoder in the MASR model is difficult. To verify this, we propose four optimizations on the decoder. They include decoder-layer gradient surgery, freezing unused token embeddings, suppressing output of newly added tokens, and learning rate re-scaling. Our experiments on adapting Whisper to 10 unseen languages from the Common Voice dataset demonstrate that these optimizations reduce the Average Word Error Rate (AWER) of pretrained languages from 14.2% to 12.4% compared with Experience Replay, without compromising the AWER of new languages.
Read more7/15/2024