Vision Transformer Computation and Resilience for Dynamic Inference
2212.02687
0
0
👀
Abstract
State-of-the-art deep learning models for computer vision tasks are based on the transformer architecture and often deployed in real-time applications. In this scenario, the resources available for every inference can vary, so it is useful to be able to dynamically adapt execution to trade accuracy for efficiency. To create dynamic models, we leverage the resilience of vision transformers to pruning and switch between different scaled versions of a model. Surprisingly, we find that most FLOPs are generated by convolutions, not attention. These relative FLOP counts are not a good predictor of GPU performance since GPUs have special optimizations for convolutions. Some models are fairly resilient and their model execution can be adapted without retraining, while all models achieve better accuracy with retraining alternative execution paths. These insights mean that we can leverage CNN accelerators and these alternative execution paths to enable efficient and dynamic vision transformer inference. Our analysis shows that leveraging this type of dynamic execution can lead to saving 28% of energy with a 1.4% accuracy drop for SegFormer (63 GFLOPs), with no additional training, and 53% of energy for ResNet-50 (4 GFLOPs) with a 3.3% accuracy drop by switching between pretrained Once-For-All models.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- State-of-the-art deep learning models for computer vision tasks are based on the transformer architecture and often used in real-time applications.
- The resources available for each inference can vary, so it's useful to be able to dynamically adapt execution to trade accuracy for efficiency.
- The researchers leverage the resilience of vision transformers to pruning and switch between different scaled versions of a model.
- They find that most FLOPs are generated by convolutions, not attention, and that GPU performance is not well-predicted by FLOP counts due to special optimizations.
- Some models can adapt execution without retraining, while all models achieve better accuracy with retraining alternative execution paths.
Plain English Explanation
The latest and most advanced deep learning models for computer vision tasks, such as object detection and image segmentation, are often based on a type of architecture called a transformer. These models are commonly used in real-world applications that need to process images or videos in real-time, like self-driving cars or security cameras.
However, the amount of computing resources available can vary for each time the model is used, such as when a mobile device has less battery power than a desktop computer. To address this, the researchers looked at ways to dynamically adjust the model's performance to balance accuracy and efficiency.
They found that these transformer-based vision models are quite resilient to having parts of their structure removed or "pruned." This means they can switch between different versions of the same model, each with a different level of complexity and computational cost. Surprisingly, the researchers discovered that the majority of the computational work is actually done by a type of operation called a convolution, not the attention mechanism that is a key part of transformer models.
Interestingly, the researchers also found that the amount of computational work (measured in FLOPs) is not always a good predictor of how fast the model will run on a graphics processing unit (GPU). This is because GPUs have special optimizations for convolutions that make them run more efficiently.
Some of the models the researchers tested were able to adjust their execution without needing to be retrained, while others achieved better accuracy when alternative execution paths were retrained. These findings mean that the researchers can leverage both specialized convolution hardware and these alternative execution paths to create vision transformer models that can dynamically balance accuracy and efficiency as needed.
Technical Explanation
The researchers explore the idea of creating dynamic deep learning models for computer vision tasks, which can trade off accuracy for efficiency based on the available resources. They leverage the resilience of vision transformers to pruning by switching between different scaled versions of a model.
Surprisingly, the analysis reveals that the majority of FLOPs are generated by convolutions, not attention. This is notable because transformer models are known for their reliance on the attention mechanism. The researchers also find that FLOP counts are not a good predictor of GPU performance, as GPUs have special optimizations for convolutions.
Some of the models tested can adapt their execution without retraining, while all models achieve better accuracy when alternative execution paths are retrained. This suggests that the researchers can leverage both CNN accelerators and these alternative execution paths to create efficient and dynamic vision transformer inference.
The results show that by leveraging this dynamic execution, the researchers can save 28% of energy with a 1.4% accuracy drop for the SegFormer model (63 GFLOPs), without any additional training. For the ResNet-50 model (4 GFLOPs), they can save 53% of energy with a 3.3% accuracy drop by switching between pretrained Once-For-All models.
Critical Analysis
The paper provides valuable insights into the inner workings of transformer-based computer vision models and demonstrates the potential benefits of dynamic model execution. However, there are a few areas that could use further exploration or clarification:
-
The analysis is focused on relatively high-performance models (SegFormer with 63 GFLOPs, ResNet-50 with 4 GFLOPs). It would be interesting to see how these findings scale to smaller, more lightweight models that may be more commonly deployed on resource-constrained devices.
-
The paper does not delve into the specific hardware or software optimizations that enable the observed performance advantages for convolutions on GPUs. A deeper understanding of these factors could help inform the development of even more efficient dynamic vision models.
-
While the researchers show the potential for energy savings through dynamic execution, the impact on other important metrics like inference latency or memory usage is not addressed. Understanding the tradeoffs across multiple performance dimensions would provide a more holistic view.
-
The paper mentions that some models can adapt their execution without retraining, while others benefit from retraining alternative execution paths. Further analysis of the factors that determine this difference could lead to more general guidelines for designing dynamic vision models.
Overall, this research highlights the potential for transformer-based computer vision models to become more efficient and adaptable to diverse deployment scenarios. Building on these insights, future work could explore a wider range of model types, hardware platforms, and performance metrics to unlock the full potential of dynamic deep learning in real-world applications.
Conclusion
This paper presents an in-depth analysis of transformer-based computer vision models and their potential for dynamic execution, where the model can trade off accuracy for efficiency based on the available resources. The key findings include:
- Transformer-based vision models are resilient to pruning, allowing them to switch between scaled versions with different computational costs.
- Contrary to expectations, convolutions, not attention, generate the majority of FLOPs in these models, and FLOP counts do not always correlate well with GPU performance.
- Some models can adapt their execution without retraining, while all models achieve better accuracy when alternative execution paths are retrained.
These insights enable the researchers to leverage both specialized convolution hardware and alternative execution paths to create efficient and dynamic vision transformer models. Their results demonstrate significant energy savings (up to 53%) with relatively small accuracy drops, showcasing the promise of this approach for real-world, resource-constrained applications.
Related Papers
👀
Which Transformer to Favor: A Comparative Analysis of Efficiency in Vision Transformers
Tobias Christian Nauen, Sebastian Palacio, Andreas Dengel
0
0
Transformers come with a high computational cost, yet their effectiveness in addressing problems in language and vision has sparked extensive research aimed at enhancing their efficiency. However, diverse experimental conditions, spanning multiple input domains, prevent a fair comparison based solely on reported results, posing challenges for model selection. To address this gap in comparability, we design a comprehensive benchmark of more than 30 models for image classification, evaluating key efficiency aspects, including accuracy, speed, and memory usage. This benchmark provides a standardized baseline across the landscape of efficiency-oriented transformers and our framework of analysis, based on Pareto optimality, reveals surprising insights. Despite claims of other models being more efficient, ViT remains Pareto optimal across multiple metrics. We observe that hybrid attention-CNN models exhibit remarkable inference memory- and parameter-efficiency. Moreover, our benchmark shows that using a larger model in general is more efficient than using higher resolution images. Thanks to our holistic evaluation, we provide a centralized resource for practitioners and researchers, facilitating informed decisions when selecting transformers or measuring progress of the development of efficient transformers.
4/15/2024
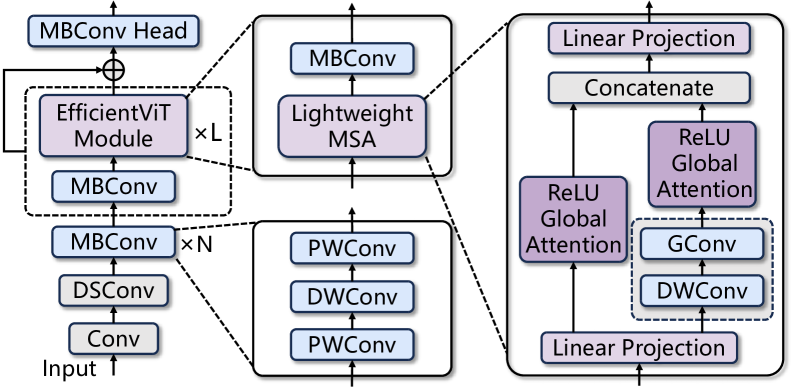
An FPGA-Based Reconfigurable Accelerator for Convolution-Transformer Hybrid EfficientViT
Haikuo Shao, Huihong Shi, Wendong Mao, Zhongfeng Wang
0
0
Vision Transformers (ViTs) have achieved significant success in computer vision. However, their intensive computations and massive memory footprint challenge ViTs' deployment on embedded devices, calling for efficient ViTs. Among them, EfficientViT, the state-of-the-art one, features a Convolution-Transformer hybrid architecture, enhancing both accuracy and hardware efficiency. Unfortunately, existing accelerators cannot fully exploit the hardware benefits of EfficientViT due to its unique architecture. In this paper, we propose an FPGA-based accelerator for EfficientViT to advance the hardware efficiency frontier of ViTs. Specifically, we design a reconfigurable architecture to efficiently support various operation types, including lightweight convolutions and attention, boosting hardware utilization. Additionally, we present a time-multiplexed and pipelined dataflow to facilitate both intra- and inter-layer fusions, reducing off-chip data access costs. Experimental results show that our accelerator achieves up to 780.2 GOPS in throughput and 105.1 GOPS/W in energy efficiency at 200MHz on the Xilinx ZCU102 FPGA, which significantly outperforms prior works.
4/1/2024
🧠
On the Efficiency of Convolutional Neural Networks
Andrew Lavin
0
0
Since the breakthrough performance of AlexNet in 2012, convolutional neural networks (convnets) have grown into extremely powerful vision models. Deep learning researchers have used convnets to produce accurate results that were unachievable a decade ago. Yet computer scientists make computational efficiency their primary objective. Accuracy with exorbitant cost is not acceptable; an algorithm must also minimize its computational requirements. Confronted with the daunting computation that convnets use, deep learning researchers also became interested in efficiency. Researchers applied tremendous effort to find the convnet architectures that have the greatest efficiency. However, skepticism grew among researchers and engineers alike about the relevance of arithmetic complexity. Contrary to the prevailing view that latency and arithmetic complexity are irreconcilable, a simple formula relates both through computational efficiency. This insight enabled us to co-optimize the separate factors that determine latency. We observed that the degenerate conv2d layers that produce the best accuracy-complexity trade-off also have low operational intensity. Therefore, kernels that implement these layers use significant memory resources. We solved this optimization problem with block-fusion kernels that implement all layers of a residual block, thereby creating temporal locality, avoiding communication, and reducing workspace size. Our ConvFirst model with block-fusion kernels ran approximately four times as fast as the ConvNeXt baseline with PyTorch Inductor, at equal accuracy on the ImageNet-1K classification task. Our unified approach to convnet efficiency envisions a new era of models and kernels that achieve greater accuracy at lower cost.
4/5/2024
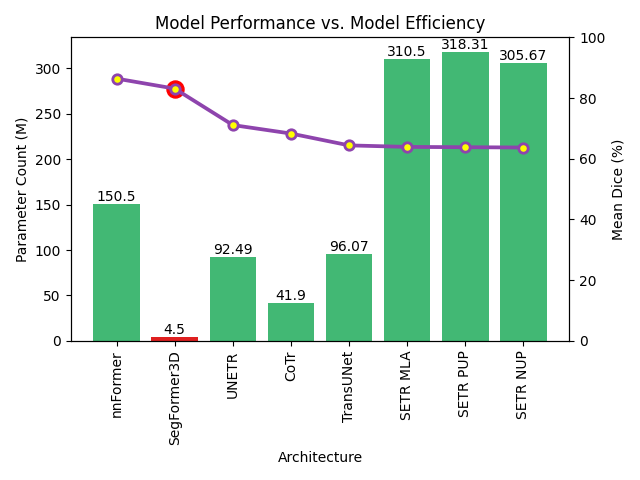
SegFormer3D: an Efficient Transformer for 3D Medical Image Segmentation
Shehan Perera, Pouyan Navard, Alper Yilmaz
0
0
The adoption of Vision Transformers (ViTs) based architectures represents a significant advancement in 3D Medical Image (MI) segmentation, surpassing traditional Convolutional Neural Network (CNN) models by enhancing global contextual understanding. While this paradigm shift has significantly enhanced 3D segmentation performance, state-of-the-art architectures require extremely large and complex architectures with large scale computing resources for training and deployment. Furthermore, in the context of limited datasets, often encountered in medical imaging, larger models can present hurdles in both model generalization and convergence. In response to these challenges and to demonstrate that lightweight models are a valuable area of research in 3D medical imaging, we present SegFormer3D, a hierarchical Transformer that calculates attention across multiscale volumetric features. Additionally, SegFormer3D avoids complex decoders and uses an all-MLP decoder to aggregate local and global attention features to produce highly accurate segmentation masks. The proposed memory efficient Transformer preserves the performance characteristics of a significantly larger model in a compact design. SegFormer3D democratizes deep learning for 3D medical image segmentation by offering a model with 33x less parameters and a 13x reduction in GFLOPS compared to the current state-of-the-art (SOTA). We benchmark SegFormer3D against the current SOTA models on three widely used datasets Synapse, BRaTs, and ACDC, achieving competitive results. Code: https://github.com/OSUPCVLab/SegFormer3D.git
4/17/2024