Efficient Tuning and Inference for Large Language Models on Textual Graphs

0
🤯
Sign in to get full access
Overview
- Textual graphs, which represent relationships between text elements, are used in many real-world applications like webpages, e-commerce, and academic articles.
- Existing methods typically use a shallow text encoder and a graph neural network (GNN) to model the textual and topological information in these graphs.
- With the recent advancements in large language models (LLMs), integrating them into the textual encoding process can significantly improve the performance of textual graphs.
- However, the efficiency of these methods is a significant challenge.
Plain English Explanation
In many real-world applications like websites, online shops, and academic papers, the relationships between different text elements (such as words, sentences, or paragraphs) are important. These relationships can be represented using textual graphs, where the text elements are the nodes, and the connections between them are the edges.
Researchers have typically used a two-step approach to model these textual graphs. First, they use a simple text encoder to convert the text into numerical representations. Then, they feed these representations into a graph neural network (GNN) to capture the relationships between the text elements.
However, with the recent advancements in large language models (LLMs), it's become clear that using these powerful models for the initial text encoding can significantly improve the performance of textual graphs. LLMs are able to understand the context and meaning of text much more effectively than simple text encoders.
The challenge is that integrating LLMs into textual graph models can be computationally expensive and resource-intensive. This is where the ENGINE method comes in. ENGINE is a way to efficiently fine-tune LLMs for use in textual graph models, without sacrificing performance.
Technical Explanation
The key innovation in ENGINE is the use of a "tunable side structure" to combine the LLM and GNN components. This approach significantly reduces the training complexity and computational cost compared to previous methods, while still maintaining the model's capacity to capture both the textual and topological information in the graph.
The researchers conducted extensive experiments on various textual graph datasets, and found that ENGINE outperformed other state-of-the-art methods in terms of model performance, while also having the lowest training cost.
Additionally, the researchers introduced two variants of ENGINE:
- Caching: This accelerates the training of ENGINE by 12x, by caching intermediate computations.
- Dynamic early exit: This can achieve up to 5x faster inference, with only a negligible drop in performance (at most 1.17% across 7 datasets).
These optimizations make ENGINE a highly efficient and practical solution for integrating LLMs into textual graph models, with benefits for both training and inference.
Critical Analysis
The researchers acknowledge that their method, while effective, still has some limitations. For example, the performance improvements may be dataset-dependent, and the specific hyperparameters or architectural choices may need to be tuned for different applications.
Additionally, the researchers note that the dynamic early exit approach, while improving inference speed, may not be suitable for all use cases where the full output of the model is required.
Further research could explore ways to make ENGINE even more efficient, such as investigating alternative side structure designs or exploring different caching or early exit strategies. It would also be interesting to see how ENGINE performs on a wider range of textual graph tasks and datasets.
Conclusion
The ENGINE method proposed in this paper represents an important step forward in integrating large language models into textual graph models. By introducing a parameter- and memory-efficient fine-tuning approach, ENGINE is able to leverage the power of LLMs without sacrificing efficiency.
The results demonstrate the effectiveness of ENGINE in achieving state-of-the-art performance on textual graph tasks, while also offering significant training and inference speed improvements through caching and dynamic early exit techniques.
This work has important implications for a wide range of applications that rely on understanding the relationships between text elements, such as web content analysis, e-commerce recommendations, and academic research. As the field of natural language processing continues to evolve, methods like ENGINE will be crucial for bringing the benefits of advanced language models to real-world, practical solutions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
0
Efficient Tuning and Inference for Large Language Models on Textual Graphs
Yun Zhu, Yaoke Wang, Haizhou Shi, Siliang Tang
Rich textual and topological information of textual graphs need to be modeled in real-world applications such as webpages, e-commerce, and academic articles. Practitioners have been long following the path of adopting a shallow text encoder and a subsequent graph neural network (GNN) to solve this problem. In light of recent advancements in large language models (LLMs), it is apparent that integrating LLMs for enhanced textual encoding can substantially improve the performance of textual graphs. Nevertheless, the efficiency of these methods poses a significant challenge. In this paper, we propose ENGINE, a parameter- and memory-efficient fine-tuning method for textual graphs with an LLM encoder. The key insight is to combine the LLMs and GNNs through a tunable side structure, which significantly reduces the training complexity without impairing the joint model's capacity. Extensive experiments on textual graphs demonstrate our method's effectiveness by achieving the best model performance, meanwhile having the lowest training cost compared to previous methods. Moreover, we introduce two variants with caching and dynamic early exit to further enhance training and inference speed. Specifically, caching accelerates ENGINE's training by 12x, and dynamic early exit achieves up to 5x faster inference with a negligible performance drop (at maximum 1.17% relevant drop across 7 datasets). Our codes are available at: https://github.com/ZhuYun97/ENGINE
Read more7/25/2024
0
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning
Qi Zhu, Da Zheng, Xiang Song, Shichang Zhang, Bowen Jin, Yizhou Sun, George Karypis
Text-rich graphs, which exhibit rich textual information on nodes and edges, are prevalent across a wide range of real-world business applications. Large Language Models (LLMs) have demonstrated remarkable abilities in understanding text, which also introduced the potential for more expressive modeling in text-rich graphs. Despite these capabilities, efficiently applying LLMs to representation learning on graphs presents significant challenges. Recently, parameter-efficient fine-tuning methods for LLMs have enabled efficient new task generalization with minimal time and memory consumption. Inspired by this, we introduce Graph-aware Parameter-Efficient Fine-Tuning - GPEFT, a novel approach for efficient graph representation learning with LLMs on text-rich graphs. Specifically, we utilize a graph neural network (GNN) to encode structural information from neighboring nodes into a graph prompt. This prompt is then inserted at the beginning of the text sequence. To improve the quality of graph prompts, we pre-trained the GNN to assist the frozen LLM in predicting the next token in the node text. Compared with existing joint GNN and LMs, our method directly generate the node embeddings from large language models with an affordable fine-tuning cost. We validate our approach through comprehensive experiments conducted on 8 different text-rich graphs, observing an average improvement of 2% in hit@1 and Mean Reciprocal Rank (MRR) in link prediction evaluations. Our results demonstrate the efficacy and efficiency of our model, showing that it can be smoothly integrated with various large language models, including OPT, LLaMA and Falcon.
Read more4/30/2024
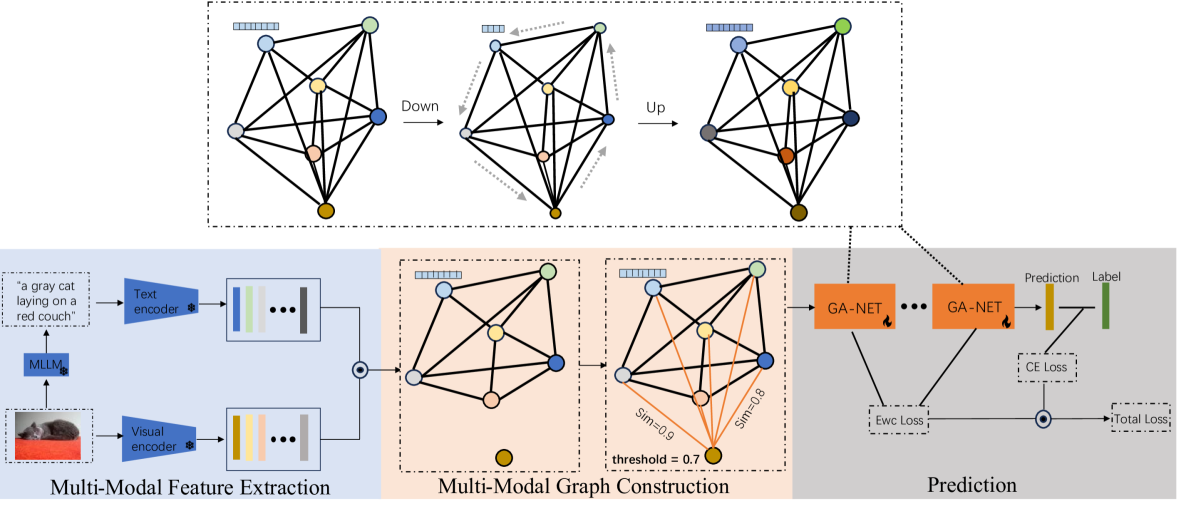
0
Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network
Bin Cheng, Jiaxuan Lu
With the advent of the era of foundation models, pre-training and fine-tuning have become common paradigms. Recently, parameter-efficient fine-tuning has garnered widespread attention due to its better balance between the number of learnable parameters and performance. However, some current parameter-efficient fine-tuning methods only model a single modality and lack the utilization of structural knowledge in downstream tasks. To address this issue, this paper proposes a multi-modal parameter-efficient fine-tuning method based on graph networks. Each image is fed into a multi-modal large language model (MLLM) to generate a text description. The image and its corresponding text description are then processed by a frozen image encoder and text encoder to generate image features and text features, respectively. A graph is constructed based on the similarity of the multi-modal feature nodes, and knowledge and relationships relevant to these features are extracted from each node. Additionally, Elastic Weight Consolidation (EWC) regularization is incorporated into the loss function to mitigate the problem of forgetting during task learning. The proposed model achieves test accuracies on the OxfordPets, Flowers102, and Food101 datasets that improve by 4.45%, 2.92%, and 0.23%, respectively. The code is available at https://github.com/yunche0/GA-Net/tree/master.
Read more8/2/2024

0
All Against Some: Efficient Integration of Large Language Models for Message Passing in Graph Neural Networks
Ajay Jaiswal, Nurendra Choudhary, Ravinarayana Adkathimar, Muthu P. Alagappan, Gaurush Hiranandani, Ying Ding, Zhangyang Wang, Edward W Huang, Karthik Subbian
Graph Neural Networks (GNNs) have attracted immense attention in the past decade due to their numerous real-world applications built around graph-structured data. On the other hand, Large Language Models (LLMs) with extensive pretrained knowledge and powerful semantic comprehension abilities have recently shown a remarkable ability to benefit applications using vision and text data. In this paper, we investigate how LLMs can be leveraged in a computationally efficient fashion to benefit rich graph-structured data, a modality relatively unexplored in LLM literature. Prior works in this area exploit LLMs to augment every node features in an ad-hoc fashion (not scalable for large graphs), use natural language to describe the complex structural information of graphs, or perform computationally expensive finetuning of LLMs in conjunction with GNNs. We propose E-LLaGNN (Efficient LLMs augmented GNNs), a framework with an on-demand LLM service that enriches message passing procedure of graph learning by enhancing a limited fraction of nodes from the graph. More specifically, E-LLaGNN relies on sampling high-quality neighborhoods using LLMs, followed by on-demand neighborhood feature enhancement using diverse prompts from our prompt catalog, and finally information aggregation using message passing from conventional GNN architectures. We explore several heuristics-based active node selection strategies to limit the computational and memory footprint of LLMs when handling millions of nodes. Through extensive experiments & ablation on popular graph benchmarks of varying scales (Cora, PubMed, ArXiv, & Products), we illustrate the effectiveness of our E-LLaGNN framework and reveal many interesting capabilities such as improved gradient flow in deep GNNs, LLM-free inference ability etc.
Read more7/23/2024