Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network

0
Sign in to get full access
Overview
- This paper presents a method for fine-tuning large language models in a parameter-efficient way for multi-modal tasks.
- The approach uses a graph neural network to learn task-specific adaptations to the model, rather than updating the entire model.
- This allows the model to be fine-tuned with significantly fewer parameters compared to traditional fine-tuning methods.
Plain English Explanation
The paper describes a technique for fine-tuning large language models to work well on multi-modal tasks (tasks that involve processing both text and other types of data, like images).
The key idea is to use a graph neural network to learn the adaptations needed for the specific task, rather than updating the entire language model. This parameter-efficient fine-tuning approach requires updating only a small portion of the model, which makes the process much more efficient.
Technical Explanation
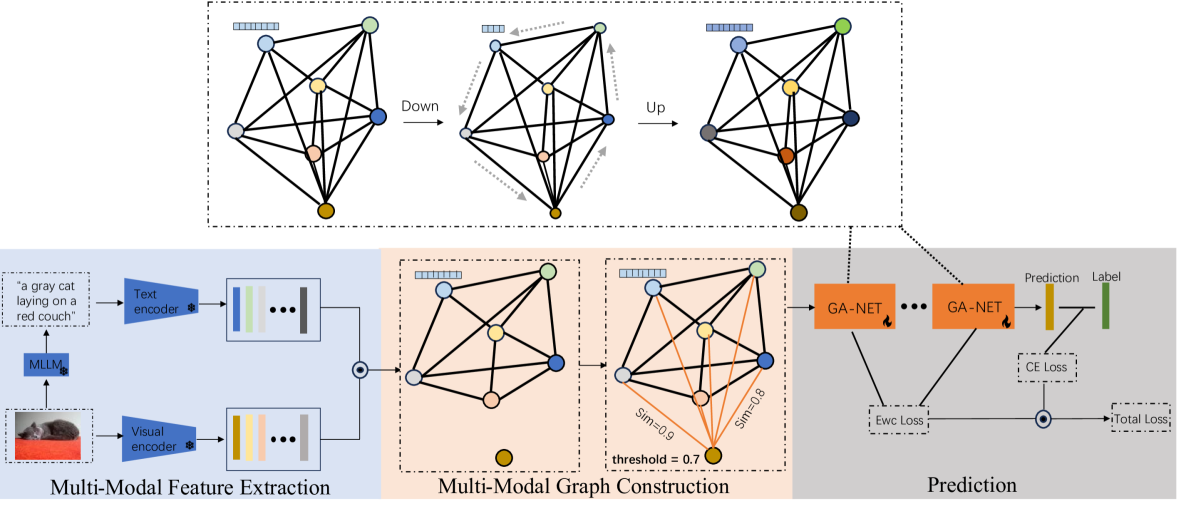
The paper proposes a Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network (MMPE-GNN) approach. The core idea is to use a graph neural network to learn task-specific adaptations to a pre-trained language model, rather than updating the entire model.
The graph neural network takes in the pre-trained language model embeddings and learns a set of task-specific parameter updates that can be efficiently applied to the language model. This allows the model to be fine-tuned for a new task with significantly fewer parameters compared to traditional fine-tuning methods.
The authors evaluate their approach on several multi-modal tasks, including visual question answering and cross-modal retrieval. They show that MMPE-GNN achieves strong performance while requiring 10-50x fewer parameters to fine-tune compared to standard fine-tuning approaches.
Critical Analysis
The paper presents a compelling approach for efficient fine-tuning of large language models on multi-modal tasks. The key strengths are the parameter-efficient nature of the fine-tuning process and the demonstrated performance on benchmark tasks.
However, the paper does not address some potential limitations or areas for further research. For example, it is unclear how the approach would scale to a large number of tasks or how the performance would compare to more complex fine-tuning strategies that update the entire model.
Additionally, the paper focuses on multi-modal tasks, but the general parameter-efficient fine-tuning approach could potentially be applied to other domains as well. Exploring the broader applicability of the technique could be an interesting direction for future work.
Conclusion
This paper presents an efficient approach for fine-tuning large language models on multi-modal tasks. By using a graph neural network to learn task-specific adaptations, the method can update the model with significantly fewer parameters compared to traditional fine-tuning.
The results demonstrate the effectiveness of this parameter-efficient fine-tuning approach, which could have important implications for deploying large language models in real-world applications where computational efficiency is a key concern.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Multi-Modal Parameter-Efficient Fine-tuning via Graph Neural Network
Bin Cheng, Jiaxuan Lu
With the advent of the era of foundation models, pre-training and fine-tuning have become common paradigms. Recently, parameter-efficient fine-tuning has garnered widespread attention due to its better balance between the number of learnable parameters and performance. However, some current parameter-efficient fine-tuning methods only model a single modality and lack the utilization of structural knowledge in downstream tasks. To address this issue, this paper proposes a multi-modal parameter-efficient fine-tuning method based on graph networks. Each image is fed into a multi-modal large language model (MLLM) to generate a text description. The image and its corresponding text description are then processed by a frozen image encoder and text encoder to generate image features and text features, respectively. A graph is constructed based on the similarity of the multi-modal feature nodes, and knowledge and relationships relevant to these features are extracted from each node. Additionally, Elastic Weight Consolidation (EWC) regularization is incorporated into the loss function to mitigate the problem of forgetting during task learning. The proposed model achieves test accuracies on the OxfordPets, Flowers102, and Food101 datasets that improve by 4.45%, 2.92%, and 0.23%, respectively. The code is available at https://github.com/yunche0/GA-Net/tree/master.
Read more8/2/2024
0
Parameter-Efficient Tuning Large Language Models for Graph Representation Learning
Qi Zhu, Da Zheng, Xiang Song, Shichang Zhang, Bowen Jin, Yizhou Sun, George Karypis
Text-rich graphs, which exhibit rich textual information on nodes and edges, are prevalent across a wide range of real-world business applications. Large Language Models (LLMs) have demonstrated remarkable abilities in understanding text, which also introduced the potential for more expressive modeling in text-rich graphs. Despite these capabilities, efficiently applying LLMs to representation learning on graphs presents significant challenges. Recently, parameter-efficient fine-tuning methods for LLMs have enabled efficient new task generalization with minimal time and memory consumption. Inspired by this, we introduce Graph-aware Parameter-Efficient Fine-Tuning - GPEFT, a novel approach for efficient graph representation learning with LLMs on text-rich graphs. Specifically, we utilize a graph neural network (GNN) to encode structural information from neighboring nodes into a graph prompt. This prompt is then inserted at the beginning of the text sequence. To improve the quality of graph prompts, we pre-trained the GNN to assist the frozen LLM in predicting the next token in the node text. Compared with existing joint GNN and LMs, our method directly generate the node embeddings from large language models with an affordable fine-tuning cost. We validate our approach through comprehensive experiments conducted on 8 different text-rich graphs, observing an average improvement of 2% in hit@1 and Mean Reciprocal Rank (MRR) in link prediction evaluations. Our results demonstrate the efficacy and efficiency of our model, showing that it can be smoothly integrated with various large language models, including OPT, LLaMA and Falcon.
Read more4/30/2024

0
An Empirical Study on Parameter-Efficient Fine-Tuning for MultiModal Large Language Models
Xiongtao Zhou, Jie He, Yuhua Ke, Guangyao Zhu, V'ictor Guti'errez-Basulto, Jeff Z. Pan
Multimodal large language models (MLLMs) fine-tuned with multimodal instruction datasets have demonstrated remarkable capabilities in multimodal tasks. However, fine-tuning all parameters of MLLMs has become challenging as they usually contain billions of parameters. To address this issue, we study parameter-efficient fine-tuning (PEFT) methods for MLLMs. We aim to identify effective methods for enhancing the performance of MLLMs in scenarios where only a limited number of parameters are trained. This paper conducts empirical studies using four popular PEFT methods to fine-tune the LLM component of open-source MLLMs. We present a comprehensive analysis that encompasses various aspects, including the impact of PEFT methods on various models, parameters and location of the PEFT module, size of fine-tuning data, model stability based on PEFT methods, MLLM's generalization, and hallucination. We evaluated four PEFT methods on seven datasets from two different categories: unseen and seen datasets. Across all experiments, we show that the adapter is the best-performing PEFT method. At the same time, fine-tuning the connector layers leads to improved performance in most MLLMs. Code and data are available at https://github.com/alenai97/PEFT-MLLM.git.
Read more6/10/2024
🤯
0
Efficient Tuning and Inference for Large Language Models on Textual Graphs
Yun Zhu, Yaoke Wang, Haizhou Shi, Siliang Tang
Rich textual and topological information of textual graphs need to be modeled in real-world applications such as webpages, e-commerce, and academic articles. Practitioners have been long following the path of adopting a shallow text encoder and a subsequent graph neural network (GNN) to solve this problem. In light of recent advancements in large language models (LLMs), it is apparent that integrating LLMs for enhanced textual encoding can substantially improve the performance of textual graphs. Nevertheless, the efficiency of these methods poses a significant challenge. In this paper, we propose ENGINE, a parameter- and memory-efficient fine-tuning method for textual graphs with an LLM encoder. The key insight is to combine the LLMs and GNNs through a tunable side structure, which significantly reduces the training complexity without impairing the joint model's capacity. Extensive experiments on textual graphs demonstrate our method's effectiveness by achieving the best model performance, meanwhile having the lowest training cost compared to previous methods. Moreover, we introduce two variants with caching and dynamic early exit to further enhance training and inference speed. Specifically, caching accelerates ENGINE's training by 12x, and dynamic early exit achieves up to 5x faster inference with a negligible performance drop (at maximum 1.17% relevant drop across 7 datasets). Our codes are available at: https://github.com/ZhuYun97/ENGINE
Read more7/25/2024